Measuring Active Learning performance in the real world
We recently wrote about why you should be using active learning. In this post we measure the performance of Active Learning in practice. Humanloop worked with Black Swan Data, a company at the forefront of applied NLP, to test our active learning platform.
Black Swan uses language AI to understand consumer trends and analyze what customers are saying in millions of online conversations. By understanding customer demand Black Swan have surfaced new opportunities for world leading brands like Pepsi Co, Lipton and McDonald's to service their customers.
To manually read all of the data in just one of these projects would take an unaided human over 100 years
That's where Humanloop came in. Humanloop demonstrated that we could train AI systems to do these tasks and consistently reduce labeling costs by as much as 40%. The reduction in labeling also opens the possibility that Black Swan could bring their data labeling in house, which would in turn significantly improve the quality of their data and the performance of their models. Here's a summary of what we learned from our tests.
The Problem
Training language AI still requires humans to read some subset of the data and manually label those examples so the model can learn. In the case of Black Swan, this means manually reading thousands of social media posts and interpreting their content for the AI system.
Data labeling remains one of the most expensive bottlenecks in building any NLP system.
Black Swan had experimented with outsourced data labeling solutions but were continually frustrated by the low quality of annotations. The performance of a machine learning model depends heavily on the quality of the annotated data. If annotators make mistakes or don't understand the guidelines, this will inevitably degrade the performance of any models trained on that data.
Could Humanloop help them reduce the required data volumes so that annotation could be done in house with much higher quality?
Back Testing the Humanloop Platform
To demonstrate the potential savings of Humanloop's active learning technology Black Swan provided Humanloop with a historical dataset that had already been labeled at random by their team.
The question we wanted to answer was: how much better would the performance have been if the team had labeled using intelligent data selection on the Humanloop platform.
To test this, we trained NLP models on 3 different classification problems with datasets of increasing size. We considered two different scenarios:
Scenario 1: We used random data selection (the industry norm) to choose which data points to include in the models training.
Scenario 2: We used Humanloop's active learning to select the data points that would have the highest impact on the model.
To ensure that we could provide meaningful scientifically valid results, we trained thousands of models on repeated experiments and averaged the results to produce confidence bounds.
Results show Humanloop could halve Black Swan's data labeling costs
Across 3 different datasets Humanloop was able to save at least 40% of the labeling normally required whilst improving performance
The graphs below show how the performance of models varied as we increased the amount of labeled data in our two scenarios.
Dataset 1:
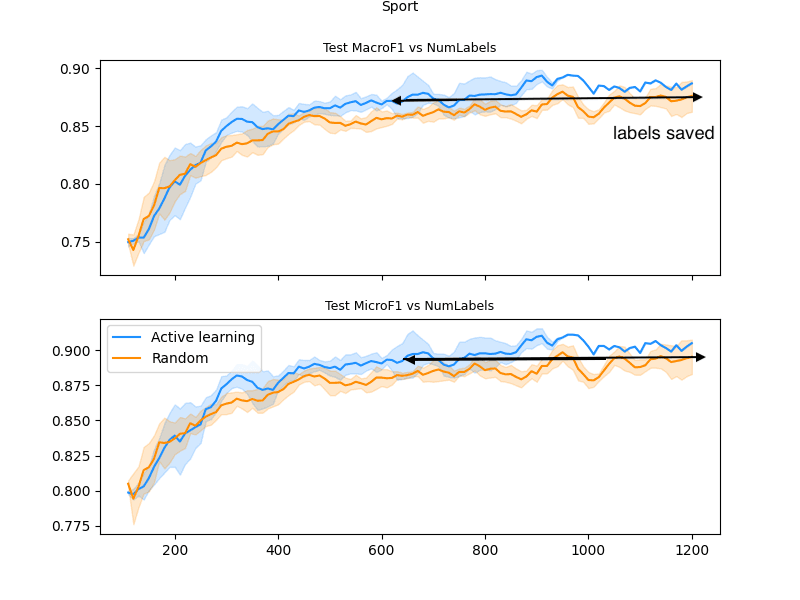
The above graph shows test performance as a function of training data size. What you can see from the graph is that the random learning (orange line) plateaus at around 87% F1 score. The same model trained on the Humanloop dataset reaches this accuracy after just 600 labels. The model also continues to improve beyond the random dataset. That means that Black Swan could either stop at 600 labels without any degradation in performance or continue labeling and have a better final model.
Dataset 2:
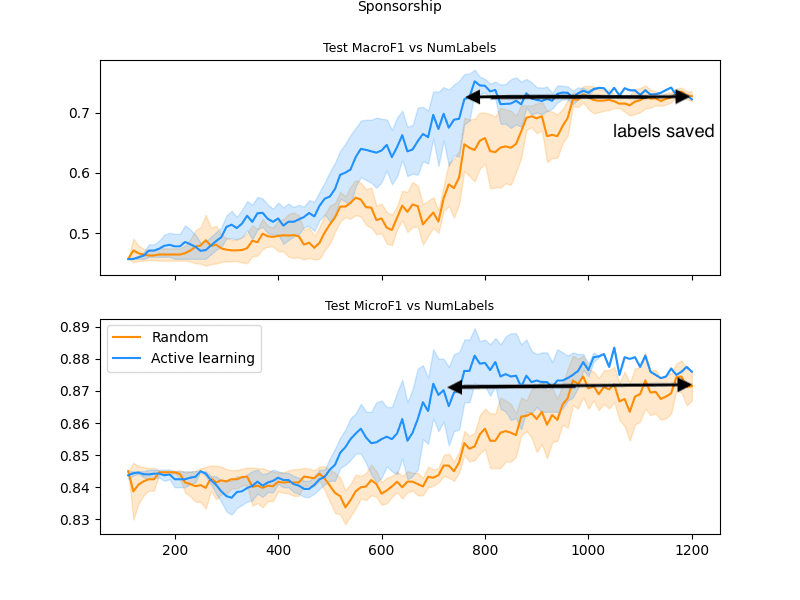
Testing the platform on a different dataset has similarly promising results. The random model plateaus again at a level well below the final Humanloop performance and there is a ~ 40% labeling saving to be had.
Dataset 3:
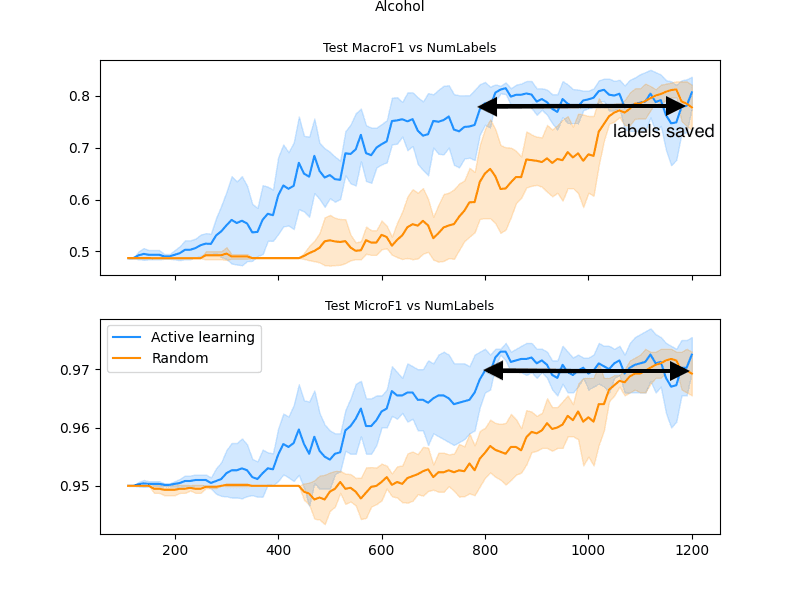
On our final dataset, results are equally compelling - Humanloop Reaches the full performance of the random system after 800 labels, with the random dataset-model taking much longer to achieve the accuracy of the model trained on Humanloop selected data.
Humanloop's active learning helped find rare points in imbalanced datasets
When we look at the balance of classes in the datasets constructed by Humanloop, we can see that over time Humanloop learns to oversample the rare class and balance an otherwise imbalanced dataset.
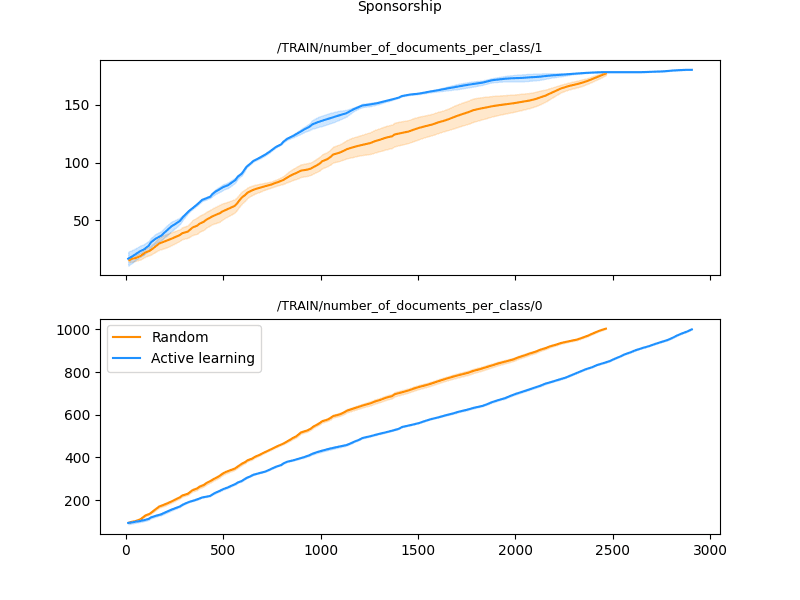
The above graph shows how much data from each of the two classes was present at each stage of our experiments. What we can see is that the rare class (class 1) is oversampled by the active learning method.
By increasing the occurrence of the rare class in the training data, Humanloop helps the model to learn about both classes quickly and so improves overall performance and the speed of learning.
Reducing labeling costs is only one of the benefits of using an Active Learning Platform
The active learning model was able to match the accuracy of a standard model with much less labeled data. Even more impressive though, we've demonstrated that an active learning model can actually achieve higher performance with less data. This is because most datasets contain both redundancy and actively harmful data. Using active learning, we can find only the high value data and avoid these harmful points.
These data savings are only one of the benefits of using active learning though. The other key benefits are the ability to get much master feedback on model performance and have tighter iteration loops so that the time-to-value of building AI systems can be dramatically reduced. If you'd like to learn more, we'd love to hear from you!
About the author

- 𝕏@RazRazcle










