Evaluate. Optimize.
Ship with Confidence.
Remove the guesswork from your AI development with actionable insights about your model performance as you move from test to production. Be confident making changes knowing your model is performing as expected.
Daniele Alfarone
Sr. Director of Engineering at Dixa
Full evaluators suite:
code, human, AI
Automate and scale your evals with code or LLM-as-a-judge evaluators that encompass best practices, runs fast, and are fully managed on our platform.
Establish ground truth by inviting your subject matter experts to our friendly interface for feedback – eliminating the need for cumbersome spreadsheets and fragmented workflows.
For ultimate flexibility, integrate your own external evaluators tailored to your unique business requirements.
Freely experiment, get data driven insights
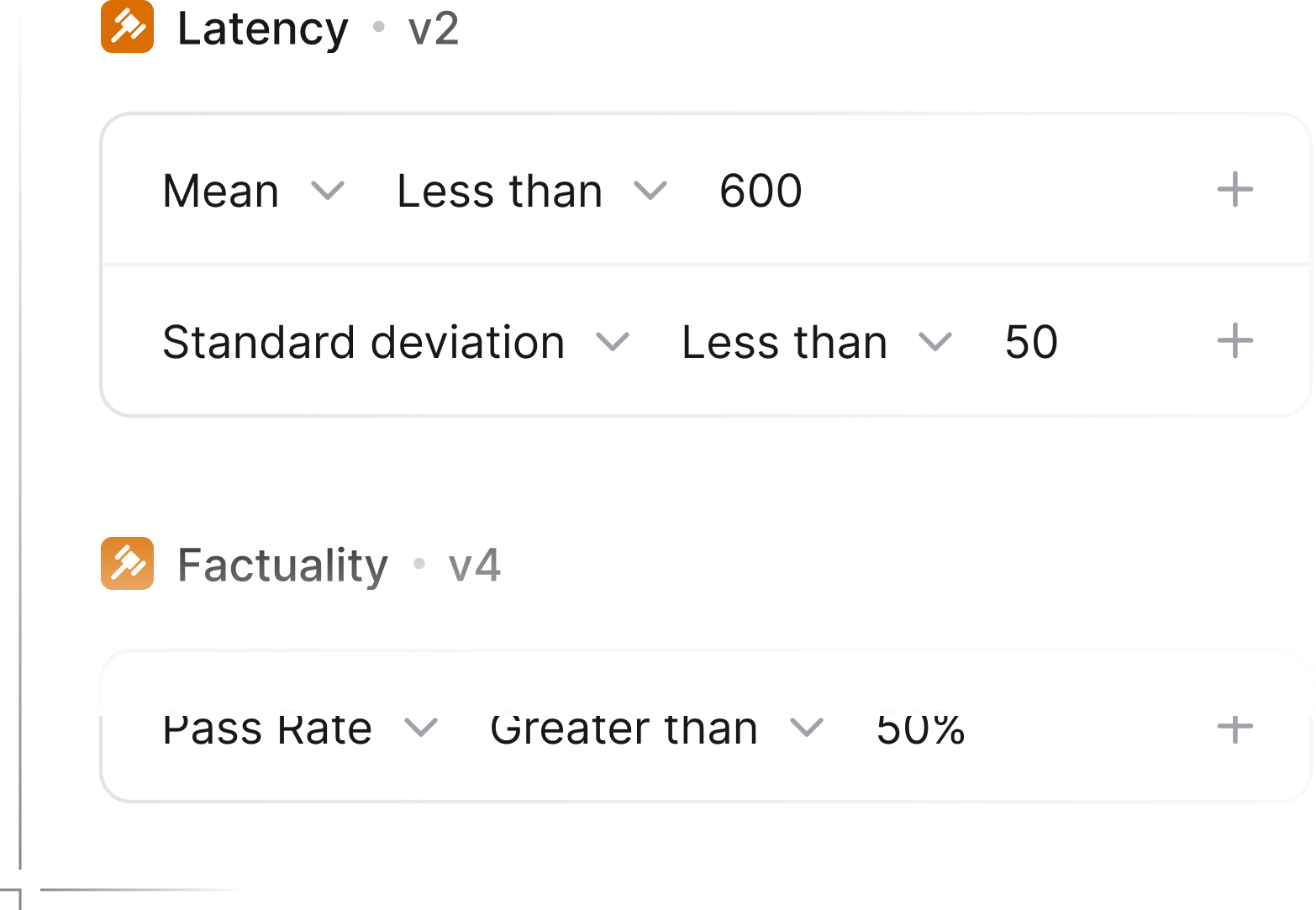
Easily benchmark your AI application so you can adopt new-generation models without risking your reputation.
Run experiments, compare results in our intuitive UI, and deep dive with powerful tools to uncover performance issues and root causes.


Accelerate your AI
use cases
Book a 1:1 demo for a guided tour of the platform tailored to your organization.
Cofounder & CEO
Get started fast with templates
Accelerate time to value by incorporating our library of pre-built evaluators for common use cases like retrieval, or easily customize them to your business use case.
Our unified platform to manage and run your evaluator makes it simpler for you to automate and track performance.

Catch regressions within your CI/CD
Easily integrate evaluations into your existing workflow for fast automated testing, and detect regressions or performance issues before they reach production.
Maintain consistency by running reproducible evaluations with version controlled datasets to track changes and performance results.
Brianna Connelly
VP of Data Science, Filevine

Ready to build successful AI products?
Book a 1:1 demo for a guided tour of the platform tailored to your organization.







