Evaluating LLM Applications
An ever-increasing number of companies are using large language models (LLMs) to transform both their product experiences and internal operations. These kinds of foundation models represent a new computing platform. The process of prompt engineering is replacing aspects of software development and the scope of what software can achieve is rapidly expanding.
In order to effectively leverage LLMs in production, having confidence in how they perform is paramount. This represents a unique challenge for most companies given the inherent novelty and complexities surrounding LLMs. Unlike traditional software and non-generative machine learning (ML) models, evaluation is subjective, hard to automate and the risk of the system going embarrassingly wrong is higher.
This post provides some thoughts on evaluating LLMs and discusses some emerging patterns I've seen work well in practice from experience with thousands of teams deploying LLM applications in production.
LLMs are not all you need
It’s important to first understand the basic makeup of what we are evaluating when working with LLMs in production. As the models get increasingly more powerful, a significant amount of effort is spent trying to give the model the appropriate context and access required to solve a task.
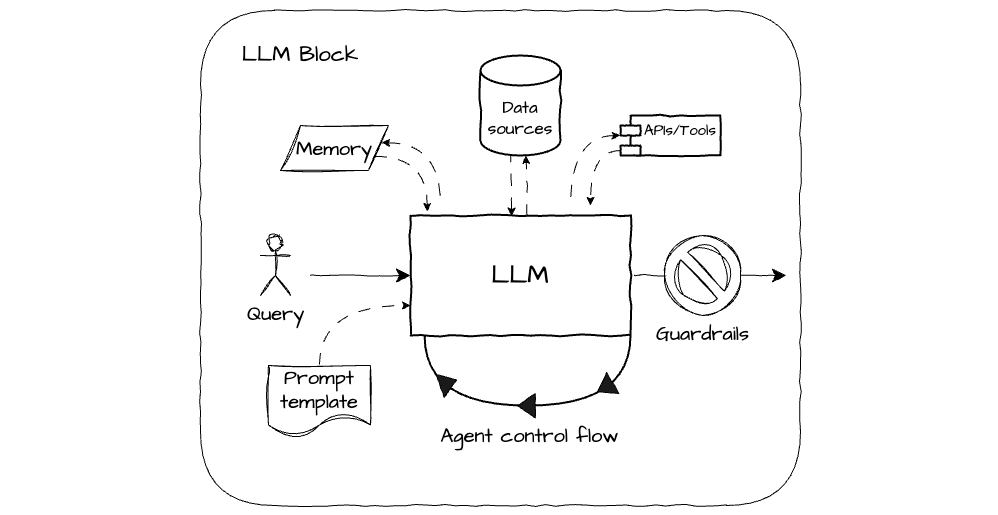
For the current generation of models, at the core of any LLM app is usually some combination of the following components:
- LLM model - the core reasoning engine; an API into OpenAI, Anthropic, Google, or open source alternatives like Mistral.
- Prompt template - the boilerplate instructions to your model, which are shared between requests. This is generally versioned and managed like code using formats like the .prompt file.
- Data sources - to provide the relevant context to the model; often referred to as retrieval augmented generation (RAG). Examples being traditional relational databases, graph databases, and vector databases.
- Memory - like a data source, but that builds up a history of previous interactions with the model for re-use.
- Tools - provides access to actions like API calls and code execution empowering the model to interact with external systems where appropriate.
- Agent control flow - some form of looping logic that allows the model to make multiple generations to solve a task before hitting some stopping criteria.
- Guardrails - a check that is run on the output of the model before returning the output to the user. This can be simple logic, for example looking for certain keywords, or another model. Often triggering fallback to human-in-the-loop workflows
LLM apps are complex systems
These individual components represent a large and unique design space to navigate. The configuration of each one requires careful consideration; it's no longer just strictly prompt engineering.
For example, take the vector database - now a mainstay for the problem of providing the relevant chunks of context to the model, for a particular query, from a larger corpus of documents. There is a near infinite number of open or closed source vector stores to choose from. Then there is the embedding model (that also has its own design choices), retrieval technique, similarity metric, how to chunk your documents, how to sync your vector store... and the list goes on.
Not only that, but there are often complex interactions between these components that are hard to predict. For example, maybe the performance of your prompt template is weirdly sensitive to the format of the separator tokens you forgot to strip when chunking your documents in the vector database (a real personal anecdote).
Furthermore, we're seeing applications that have multiple specialist blocks of these components chained together to solve a task. This all adds to the challenge of evaluating the resulting complex system. Specialist tooling is increasingly a necessity to help teams build robust applications.
Like for testing in traditional software development, the goal of a good LLM evaluation framework is to provide confidence that the system is working as expected and also transparency into what might be causing issues when things go wrong. Unlike traditional software development, a significant amount of experimentation and collaboration is required when building with LLMs. From prompt engineering with domain experts, to tool integrations with engineers. A systematic way to track progress is required.
Take lessons from traditional software
A large proportion of teams now building great products with LLMs aren't experienced ML practitioners. Conveniently many of the goals and best practices from software development are broadly still relevant when thinking about LLM evals.
Automation and continuous integration is still the goal
Competent teams will traditionally set up robust test suites that are run automatically against every system change before deploying to production. This is a key aspect of continuous integration (CI) and is done to protect against regressions and ensure the system is working as the engineers expect. Test suites are generally made up of 3 canonical types of tests: unit, integration and end-to-end.

- Unit - very numerous, target a specific atom of code and are fast to run.
- Integration - less numerous, cover multiple chunks of code, are slower to run than unit tests and may require mocking external services.
- End-to-end - emulate the experience of an end UI user or API caller; they are slow to run and oftentimes need to interact with a live version of the system.
The most effective mix of test types for a given system often sparks debate. Yet, the role of automated testing as part of the deployment lifecycle, alongside the various trade-offs between complexity and speed, remain valuable considerations when working with LLMs.
Unit tests are tricky for LLMs
There are however a number of fundamental differences with LLM native products when it comes to this type of testing. Of the test types, the most difficult to transfer over to LLMs is the unit test because of:
- Randomness - LLMs produce probabilities over words which can result in random variation between generations for the same prompt. Certain applications, like task automation, require deterministic predictions. Others, like creative writing, demand diversity.
- Subjectivity - we oftentimes want LLMs to produce natural human-like interactions. This requires more nuanced approaches to evaluation because of the inherent subjectivity of the correctness of outputs, which may depend on context or user preferences.
- Cost and latency - given the computation involved, running SOTA LLMs can come with a significant cost and tend to have relatively high latency; especially if configured as an agent that can take multiple steps.
- Scope - LLMs are increasingly capable of solving broader less well-defined tasks, resulting in the scope of what we are evaluating often being a lot more open-ended than in traditional software applications.
As a result, the majority of automation efforts in evaluating LLM apps take the form of integration and end-to-end style tests and should be managed as such within CI pipelines.
Observability needs to evolve
There is also the important practice of monitoring the system in production. Load and usage patterns in the wild can be unexpected and lead to bugs. Traditional observability solutions like Datadog and New Relic monitor the health of the system and provide alerts when things go wrong; usually based on simple heuristics and error codes. This tends to fall short when it comes to LLMs. The more capable and complex the system, the harder it can be to determine something actually went wrong and the more important observability and traceability is.
Furthermore, one of the promises of building with LLMs is the potential to more rapidly intervene and experiment. By tweaking instructions you can fix issues and improve performance. Another advantage is that less technical teams can be more involved in building; the makeup of the teams is evolving. This impacts what's needed from an observability solution in this setting. A tighter integration between observability data and the development environment to make changes is more beneficial, as well as usability for collaborating with product teams and domain experts outside of engineering. This promise of more rapid and sometimes non-technical iteration cycles also increases the importance of robust regression testing.
Before delving more into the stages of evaluation and how they relate to existing CI and observability concepts, it's important to understand more about the different types of evaluations in this space.
Types of evaluation can vary significantly
When evaluating one or more components of an LLM block, different types of evaluations are appropriate depending on your goals, the complexity of the task and available resources. Having good coverage over the components that are likely to have an impact over the overall quality of the system is important.
These different types can be roughly characterized by the return type and the source of, as well as the criteria for, the judgment required.
Judgment return types are best kept simple
The most common judgment return types are familiar from traditional data science and machine learning frameworks. From simple to more complex:
- Binary - involves a yes/no, true/false, or pass/fail judgment based on some criteria.
- Categorical - involves more than two categories; for exampling adding an abstain or maybe option to a binary judgment.
- Ranking - the relative quality of output from different samples or variations of the model are being ranked from best to worst based on some criteria. Preference based judgments are often used in evaluating the quality of a ranking.
- Numerical - involves a score, a percentage, or any other kind of numeric rating.
- Text - a simple comment or a more detailed critique. Often used when a more nuanced or detailed evaluation of the model's output is required.
- Multi-task - combines multiple types of judgment simultaneously. For example, a model's output could be evaluated using both a binary rating and a free-form text explanation.
Simple individual judgments can be easily aggregated across a dataset of multiple examples using well known metrics. For example, for classification problems, precision, recall and F1 are typical choices. For rankings, there are metrics like NDCG, Elo ratings and Kendall's Tau. For numerical judgments there are variations of the Bleu score.
I find that in practice binary and categorical types generally cover the majority of use cases. They have the added benefit of being the most straight forward to source reliably. The more complex the judgment type, the more potential for ambiguity there is and the harder it becomes to make inferences.
Model sourced judgments are increasingly promising
Sourcing judgments is an area where there are new and evolving patterns around foundation models like LLMs. At Humanloop, we've standardised around the following canonical sources:
- Heuristic/Code - using simple deterministic rules based judgments against attributes like cost, token usage, latency, regex rules on the output, etc. These are generally fast and cheap to run at scale.
- Model (or 'AI') - using other foundation models to provide judgments on the output of the component. This allows for more qualitative and nuanced judgments for a fraction of the cost of human judgments.
- Human - getting gold standard judgments from either end users of your application, or internal domain experts. This can be the most expensive and slowest option, but also the most reliable.

Model judgments in particular are increasingly promising and an active research area. The paper Judging LLM-as-a-Judge demonstrates that an appropriately prompted GPT-4 model achieves over 80% agreement with human judgments when rating LLM model responses to questions on a scale of 1-10; that's equivalent to the levels of agreement between humans.
Such evaluators can be equally effective in evaluating the important non-LLM components, such as the retrieval component in RAG. In Automated Evaluation of Retrieval Augmented Generation a GPT-3 model is tasked with extracting the most relevant sentences from the retrieved context. A numeric judgment for relevance is then computed using the ratio of the number of relevant to irrelevant sentences, which was also found to be highly correlated with expert human judgments.
However, there are risks to consider. The same reasons that evaluating LLMs is hard apply to using them as evaluators. Recent research has also shown LLMs to have biases that can contaminate the evaluation process. In Benchmarking Cognitive Biases in Large Language Models as Evaluators they measure 6 cognitive biases across 15 different LLM variations. They find that simple details such as the order of the results presented to the model can have material impact on the evaluation.

The takeaway here is that it's important to still experiment with performance on your target use cases before trusting LLM evaluators - evaluate the evaluator! All the usual prompt engineering techniques such as including few-shot examples are just as applicable here. In addition, fine-tuning specialist, more economical evaluator models using human judgements can be a real unlock.
I believe teams should consider shifting more of their human judgment efforts up a level to focus on helping improve model evaluators. This will ultimately lead to a more scalable, repeatable and cost-effective evaluation process. As well as one where the human expertise can be more targeted on the most important high value scenarios.
Judgment criteria is where most of the customisation happens
The actual criteria for the judgment is what tends to be most specific to the needs of a particular use case. This will either be defined in code, in a prompt (or in the parameters of a model), or just in guidelines depending on whether it's a code, model or human based evaluator.
There are lots of broad themes to crib from. Humanloop for example provides templates for popular use cases and best practises, with the ability to experiment and customize. There are categories like general performance (latency, cost and error thresholds), behavioural (tone of voice, writing style, diversity, factuality, relevance, etc.), ethical (bias, safety, privacy, etc.) and user experience (engagement, satisfaction, productivity, etc.).
Unsurprisingly, starting with a small set of evaluators that cover the most important criteria is wise. These can then be adapted and added to over time as requirements are clarified and new edge cases uncovered. Tradeoffs are often necessary between these criteria. For example, a more diverse set of responses might be more engaging, but also more likely to contain errors and higher quality can often come at a cost in terms of latency.
Thinking about these criteria upfront for your project can be a good hack to ensure your team deeply understand the end goals of the application.
Different stages of evaluation are necessary
As discussed with the distinction between CI and observability; different stages of the app development lifecycle will have different evaluation needs. I've found this lifecycle to naturally still consist of some sort of planning and scoping exercise, followed by cycles of development, deployment and monitoring.
These cycles are then repeated during the lifetime of the LLM app in order to intervene and improve performance. The stronger the teams, the more agile and continuous this process tends to be.
Development here will include both the typical app development; orchestrating your LLM blocks in code, setting up your UIs, etc, as well more LLM specific interventions and experimentation; including prompt engineering, context tweaking, tool integration updates and fine-tuning - to name a few. Both the choices and quality of interventions to optimize your LLM performance are much improved if the right evaluation stages are in place. It facilitates a more data-driven, systematic approach.
From my experience there are 3 complementary stages of evaluation that are highest ROI in supporting rapid iteration cycles of the LLM block related interventions:
-
Interactive - it's useful to have an interactive playground-like editor environment that allows rapid experimentation with components of the model and provides immediate evaluator feedback. This usually works best on a relatively small number of scenarios. This allows teams (both technical and non-technical) to quickly explore the design space of the LLM app and get an informal sense of what works well.
-
Batch offline - benchmarking or regression testing the most promising variations over a larger curated set of scenarios to provide a more systematic evaluation. Ideally a range of different evaluators for different components of the app can contribute to this stage, some comparing against gold standard expected results for the task. This can fit naturally into existing CI processes.
-
Monitoring online - post deployment, real user interactions can be evaluated continuously to monitor the performance of the model. This process can drive alerts, gather additional scenarios for offline evaluations and inform when to make further interventions. Staging deployments through internal environments, or beta testing with selected cohorts of users first, are usually super valuable.
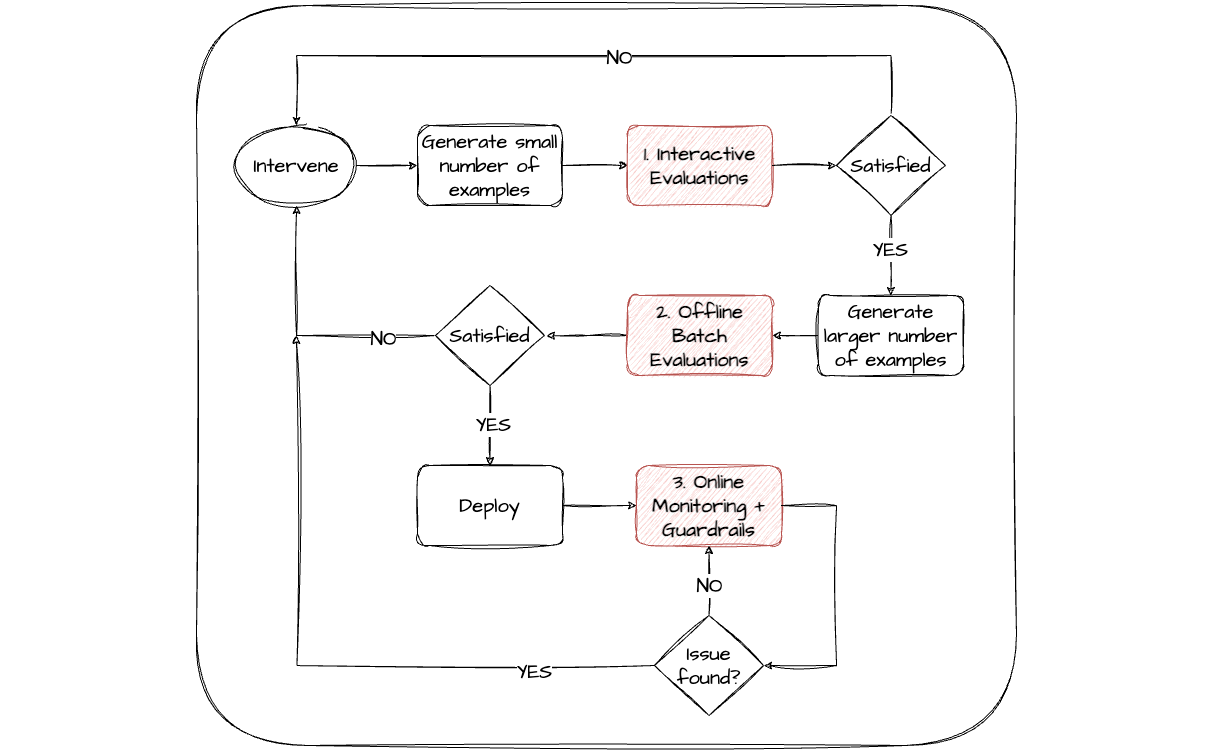
It's usually necessary to co-evolve to some degree the evaluation framework alongside the app development as more data becomes available and requirements are clarified. The ability to easily version control and share across stages and teams both the evaluators and the configuration of your app can significantly improve the efficiency of this process.
High quality datasets are still paramount
Lack of access to high quality data will undermine any good evaluation framework. A good evaluation dataset should ideally be representative of the full distribution of behaviours you expect to see and care about in production, considering both the inputs and the expected outputs. It's also important to keep in mind that coverage of the expected behaviours for the individual components of your app is important.
Here are some strategies that I think are worth considering: leveraging public/academic benchmarks, collecting data from your own systems and creating synthetic data.
Pay attention to academic and public benchmarks
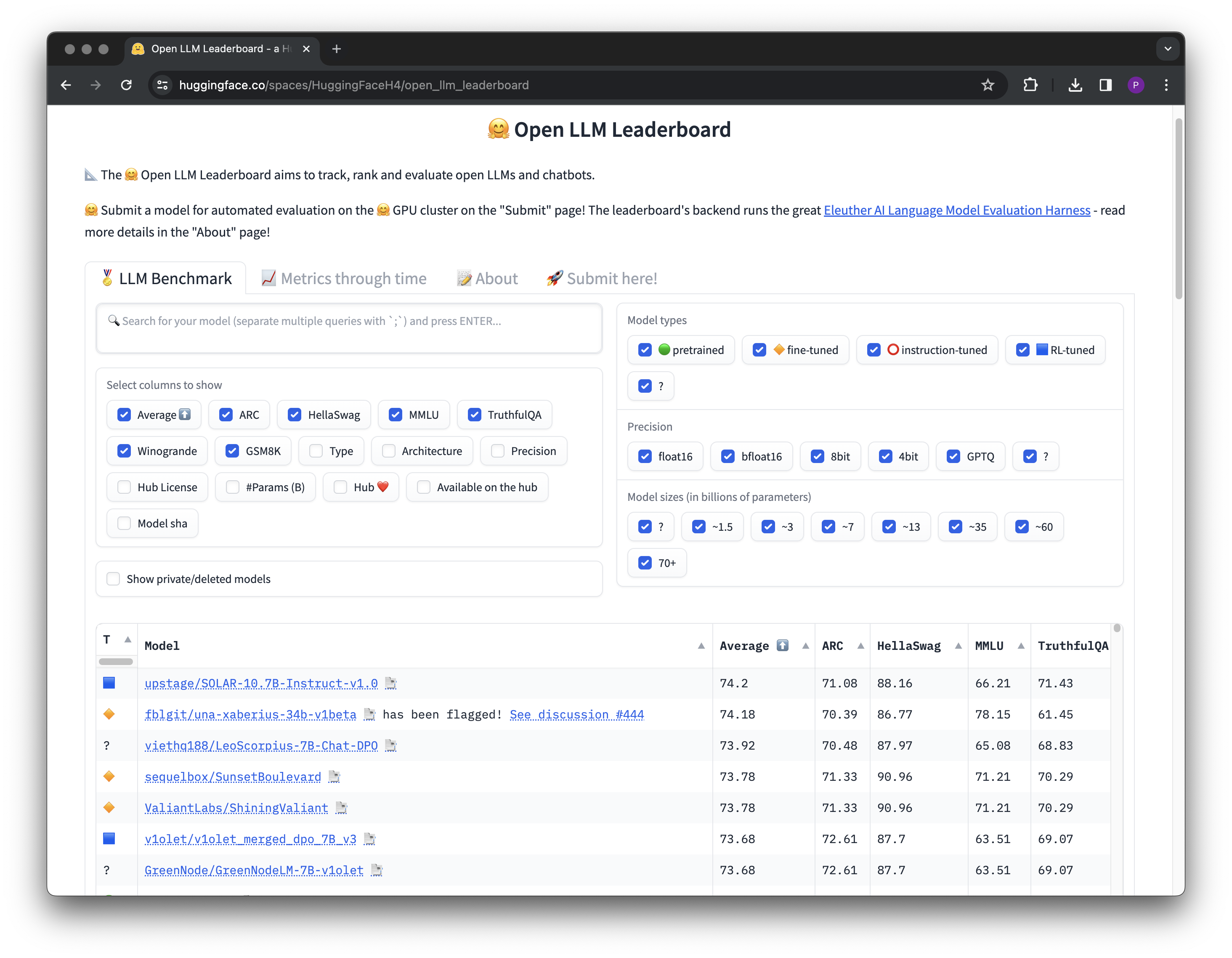
There are well cited academic benchmarks that have been curated to evaluate the general capabilities of LLMs. For AI leaders, these can be helpful to reference when choosing which base models to build with originally, or to graduate to when things like scale and cost start to factor in. For example the Large Model Systems Organizations maintains Chatbot Arena where they have crowd-sourced over 200k human preferences votes to rank LLMs, both commercial and open source, as well as recording the performance on academic multi-task reasoning benchmarks like MMLU.

Another great resource in the same vein is Hugging Face datasets, where they also maintain a leaderboard of how all the latest OSS models perform across a range of tasks using the Eleuther LLM evaluation harness library.
More domain specific academic datasets may also be particularly relevant for your target use case and can be used to warm start your evaluation efforts; for example if you were working on medical related tasks.
Real product interactions are the most valuable source of data
Arguably the best form of dataset comes from real user interactions. Useful sources of this kind of data are actually the interactive and monitoring stages discussed above.
With access to an interactive environment for prompt engineering (or a test version of your application), internal domain experts can synthesize examples of the kinds of interactions they expect to see in production. These interactions should be recorded throughout the course of initial experimentation to form a benchmark dataset for subsequent offline evaluations.
For leveraging real end-user interactions, a tighter integration between observability data and the development environment that manages evaluations makes it easier to curate real scenarios into your benchmark datasets over time.
Something worth careful consideration to maximise the impact of end-user interactions is to set up your application to capture rich feedback from users form the start. This is an example of an online evaluator that relies on human judgments, which can be used to filter for particularly interesting scenarios to add to benchmark datasets.
Feedback doesn't need to be only explicit from the user; it can be provided implicitly in the way they interact with the system. For example, github copilot reportedly monitors whether the code suggestion was accepted at various time increments after the suggestion was made, as well as whether the user made any edits to the suggestion before accepting it.
Synthetic data is on the rise
Once you have a small amount of high quality data leveraging LLMs to generate additional input examples can help bootstrap to larger datasets. By utilizing few-shot prompting and including a representative subset of your existing data within the prompt, you can guide the synthesizer model to generate a wide range of supplementary examples.
A quick pointer here is to prompt the model to generate a batch of examples at a time, rather than one at a time, such that you can encourage characteristics like diversity between examples. Or, similarly, feed previously generated examples back into your prompt. For instance, for a customer service system, prompts could be designed to elicit responses across a variety of emotional states, from satisfaction to frustration.
A specific example of this is model red-teaming, or synthesizing adversarial examples. This is where you use the synthesizer model to generate examples that are designed to break the system. For example, in Red Teaming Language Models with Language Models, they uncover offensive replies, data leakage and other vulnerabilities in an LLM chat-bot using variations of few-shot prompts to generate adversarial questions. They also leverage a pre-trained offensive classifier to help automate their evaluation process. However, it is worth noting they too point out the limitations caused by LLM biases that limits diversity. They ultimately need to generate and filter hundreds of thousands of synthetic examples.

As with LLM evaluators, all the same rigour and tools should be applied to evaluating the quality of the synthetic data generator model before trusting it.
Looking forward...
This is a rapidly evolving area of research and practice. Here's a few areas that I'm particularly excited about working more on at Humanloop over the coming months that we'll touch on further in future posts:
-
Increasing adoption of AI based evaluators for all components of these systems, with improved support for fine-tuning and specialisation happening at this level. The existence of OpenAI's Superalignment team shows there is focus here on the research front.
-
Supporting more multi-modal applications deployed in production, with more text, image, voice and even video based models coming online.
-
More complex agent-based workflows and experimenting with more multi-agent setups and how evaluation needs to adapt to supervise these systems.
-
Moving towards more end-to-end optimization for the components of these complex systems. A robust set of evaluators can provide an objective to measure performance, coupled with data synthesization to simulate the system.
At Humanloop, we've built an integrated solution for managing the development lifecycle of LLM apps from first principles, which includes some of the evaluation challenges discussed in this post. Please reach out if you'd like to learn more.
About the author











