LLM as a Judge
LLM as a Judge: Automating AI Evaluations
How do you maintain quality control in AI systems when scaling from hundreds to millions of interactions? Traditional evaluation methods like manual reviews or simplistic checks quickly become impractical, costly, and inadequate for nuanced tasks. As enterprises deploy AI across customer support and decision-making processes, the stakes for accuracy and relevance grow exponentially.
LLM-as-a-judge offers a viable solution: using large language models (LLMs) to evaluate AI outputs with the sophistication of human judgment but at the speed and scale of automation. Enterprises can ensure that their applications deliver consistent, reliable results by turning LLMs into dynamic assessors.
This guide will unpack how LLM-as-a-judge changes quality assurance, so enterprises can confidently deploy AI applications while reducing costs and accelerating iteration. We’ll also look at key benefits, types of LLM evaluators, challenges, and how to overcome them.
What is LLM as a Judge?
LLM-as-a-judge is an evaluation technique that leverages LLMs to assess the quality, relevance, and reliability of outputs generated by other LLMs. This approach addresses the challenge of evaluating open-ended, subjective tasks like chatbot responses, summarization, and code generation.
When evaluating LLM applications at scale, traditional metrics like accuracy or ROGUE fall short. By using LLMs as evaluators enterprises can automate quality control at scale while maintaining alignment with human judgment.
How Does LLM as a Judge Work?
The process of using LLM-as-a-judge involves several key steps:
Defining Evaluation Criteria
The first step is establishing what qualities or attributes need assessment. This might include factors like:
- Factual accuracy
- Helpfulness
- Conciseness
- Adherence to a specific tone
These criteria are then encoded into an evaluation prompt, which serves as the instruction set for the LLM performing the judgment.
Evaluation Prompting
An evaluation prompt is crafted to guide the judge LLM in its task. For example, if evaluating chatbot responses for helpfulness, the prompt might look like:
“Given a QUESTION and RESPONSE, evaluate whether the response is helpful. Helpful responses are clear, relevant, and actionable. Label the response as ‘helpful’ or ‘unhelpful’ and explain your reasoning.”
Another example of a prompt can be seen below.
Input Analysis
The judge LLM analyzes the input provided, which typically includes:
- The original query or task (e.g., a user question)
- The AI-generated output being evaluated (e.g., a chatbot’s response)
- Optional references or context (e.g., source documents in retrieval-augmented generation)
Scoring or Labeling
Based on the evaluation prompt, the judge LLM assigns a score, label (e.g., correct vs. incorrect), or even a detailed explanation of its assessment.
For example:
- Single output scoring: Evaluates one response based on predefined criteria
- Pairwise comparison: Compares two outputs and selects the better one
- Reference-guided scoring: Judges an output against a “gold standard” reference
Feedback Generation
The judge LLM can optionally provide detailed feedback explaining its evaluation. This helps developers understand why certain outputs were rated poorly and identify areas for improvement.
Different types of LLM as a Judge evaluators
LLM-as-a-judge evaluators are designed to assess the quality of AI-generated outputs across various use cases. These evaluators rely on LLMs to score, compare, or classify outputs based on predefined criteria.
Here, we’ll explore the main types of LLM-as-a-judge evaluators in-depth, focusing on how they work and when they are applied.
1. Single Output Scoring
This type of evaluator assesses a single AI-generated response against specific evaluation criteria. It can operate in two modes:
a. Without Reference
The LLM judge evaluates the output based solely on the input and predefined criteria. An example would be:
“Evaluate if the response is clear and concise. Return a label: ‘Concise’ or ‘Verbose.’”
It’s ideal for tasks like checking tone, politeness, or adhering to a format without a “gold standard” answer.
b. With Reference
The LLM judge compares the output to a reference or ‘gold standard’ answer provided in the prompt. One example is:
“Compare the generated response to the reference answer. Does it convey the same meaning? Return ‘Correct’ or ‘Incorrect’.”
This is commonly used in regression testing or when evaluating factual correctness.
2. Pairwise Comparison
In this setup, the LLM judge is presented with two outputs for the same input and tasked with determining which is better based on specific criteria.
An example prompt is:
“You will see two responses to the same question. Decide which response is better based on relevance and clarity. If both are equally good, declare a tie.”
Pairwise comparison is often employed to compare outputs from different models or prompts during model development. One key advantage of this approach is that it provides relative judgments less prone to inconsistencies than absolute scoring. Although, it’s worth noting that it isn’t scalable for large datasets since every combination of outputs must be compared.
3. Reference Guided Scoring
This evaluator incorporates additional context or reference material into its judgment process. It’s especially useful in cases where grounding responses in external information is essential.
For teams looking to evaluate a retrieval-augmented generation (RAG) app, reference-guided scoring ensures outputs align with retrieved documents, reducing hallucinations.

How to Build an LLM Evaluator
Building an effective LLM evaluator requires careful planning and alignment with your AI application’s unique applications.
To help you get started, we’ll cover the differences between offline and online LLM evaluators, how to build an LLM evaluator with Humanloop, and the best practices you should follow.
Offline vs Online LLM Evaluators
LLM evaluators can operate in two modes, depending on when and how they are applied: offline or online. Both approaches serve different purposes in an AI application's lifecycle.
Offline LLM Evaluators
Offline LLM evaluators are used during the development and testing phases before deployment. They evaluate models in controlled environments using pre-curated datasets.
Key features include:
- Dataset-based testing: Uses golden datasets with labeled datasets and expected outputs.
- Pre-deployment validation: Ensures that models meet performance benchmarks before going live.
- Prompt experimentation: Allows teams to test modifications to prompts or model configurations without affecting production teams.
An example use case would be testing a customer support chatbot offline using a dataset of common user queries and reference answers to ensure it provides accurate responses across scenarios.
Online LLM Evaluators
Online LLM evaluators operate in real-time on live production data, continuously monitoring model performance during deployment. Teams can evaluate an agent in real-time to identify potential biases or inconsistencies as they arise.
Key features include:
- Real-time feedback: Evaluates outputs as they are generated in production environments.
- Dynamic data handling: Captures live user interactions, which may include unexpected edge cases not present in offline datasets.
- Continuous monitoring: Tracks performance metrics like accuracy, latency, or user satisfaction over time.
One example is a healthcare assistant deployed in production that uses an online evaluator to flag potentially harmful advice before it reaches users.
Here are the key differences between offline and online evaluators:
| Purpose | Offline evaluators | Online evaluators |
|---|---|---|
| Environment | Controlled (pre-production) | Real-time production |
| Data source | Curated datasets | Live user interactions |
| Purpose | Pre-deployment validation | Continuous monitoring and issue detection |
| Cost efficiency | Lower cost; no real-time processing | Higher cost due to real-time interaction |
| Use case example | Testing prompt changes before deployment | Monitoring chatbot responses for hallucinations |
Combining offline evaluations for pre-deployment testing with online evaluations for real-time monitoring is best. This ensures your LLM applications perform reliably throughout their lifecycle while adapting to dynamic production environments.
Building LLM as a Judge with Humanloop
With Humanloop’s platform, teams can design, deploy, and monitor custom LLM evaluators tailored to their specific use cases.
Here’s how you can use the UI to carry out evaluations on Humanloop’s platform:
1. Get the Prerequisites
Firstly, you’ll want to prepare:
- Prompt versions you want to compare
- Dataset that contains datapoints for the task
- An evaluator (code, human or AI) to judge prompt performance
2. Setup an Evaluation Run
Go to the evaluations tab for the prompt you want to evaluate.
Press “Evaluate”, then ”+Run”.
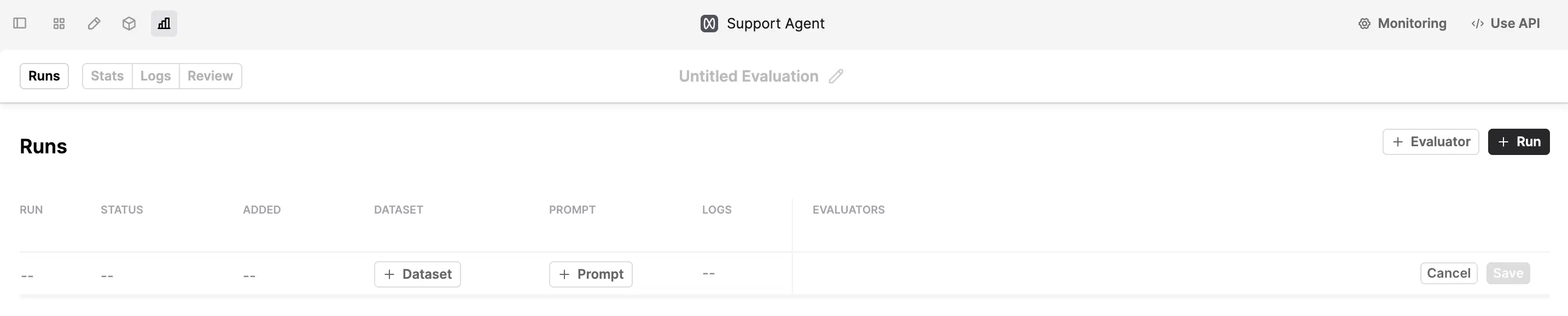
Afterwards, choose a dataset by pressing “+Dataset”. You can then add the versions of the prompt you want to compare with “+Prompt”. Use “+Evaluator” to add the evaluators you want to judge the performance of.
Press “Save”, and you’ll start seeing the evaluation logs generated.
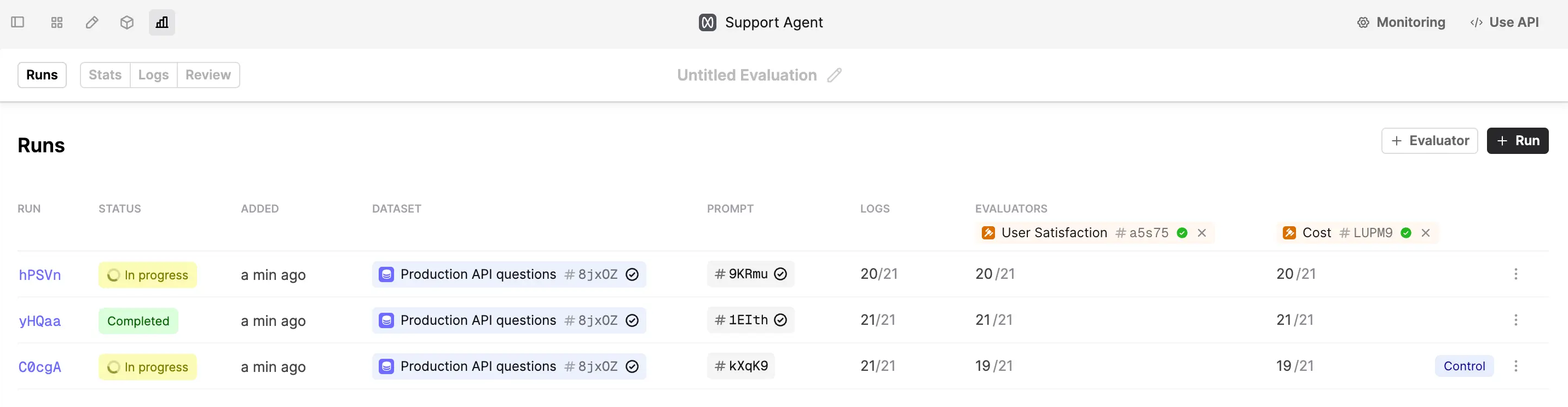
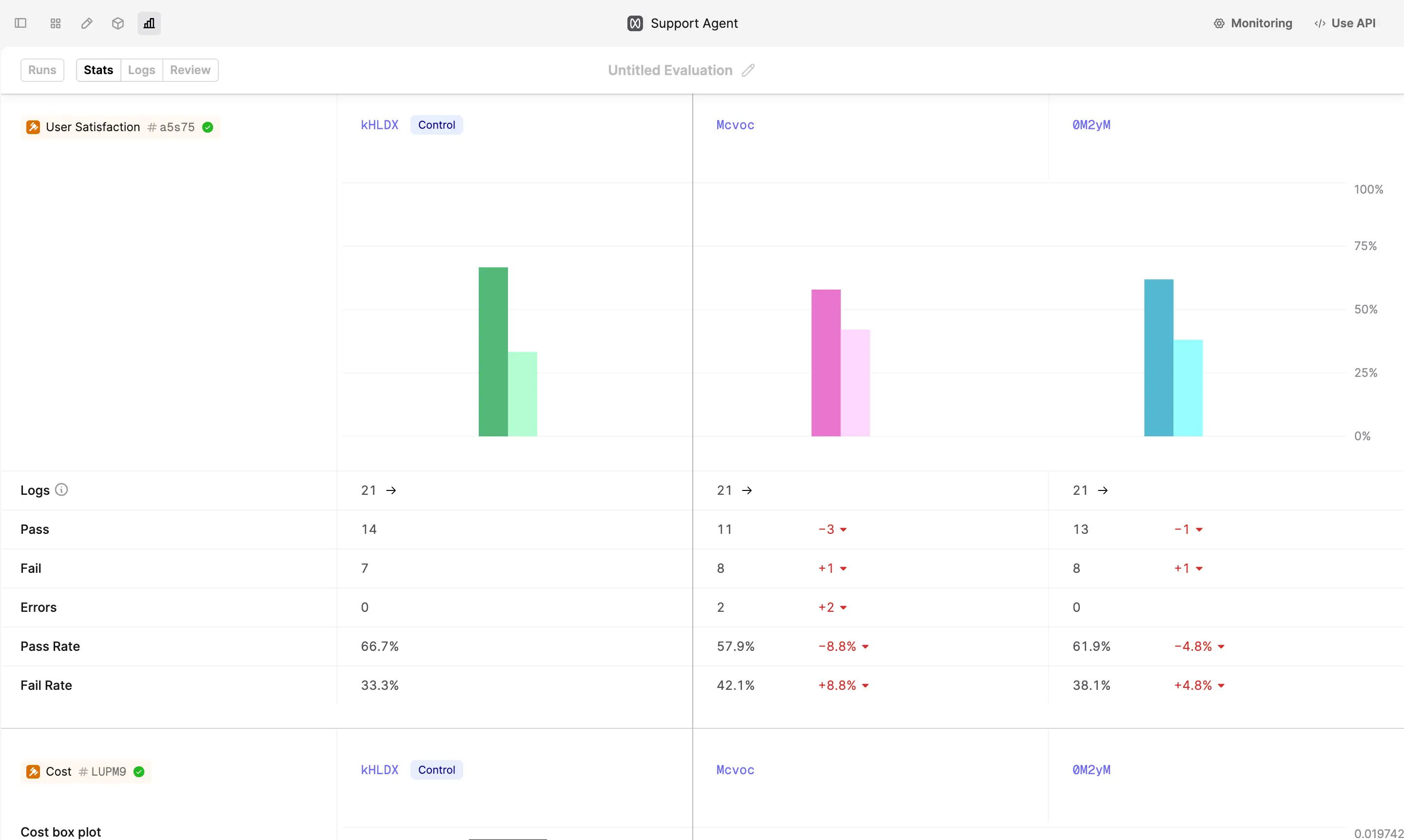
3. Review Results
Use the “Stats” tab to review the performance of different versions of the prompt. You’ll see a spider plot containing a summary of the average evaluator performance across all prompt versions.
This example shows gpt-4o provided the best user satisfaction despite having a higher cost and being slower.
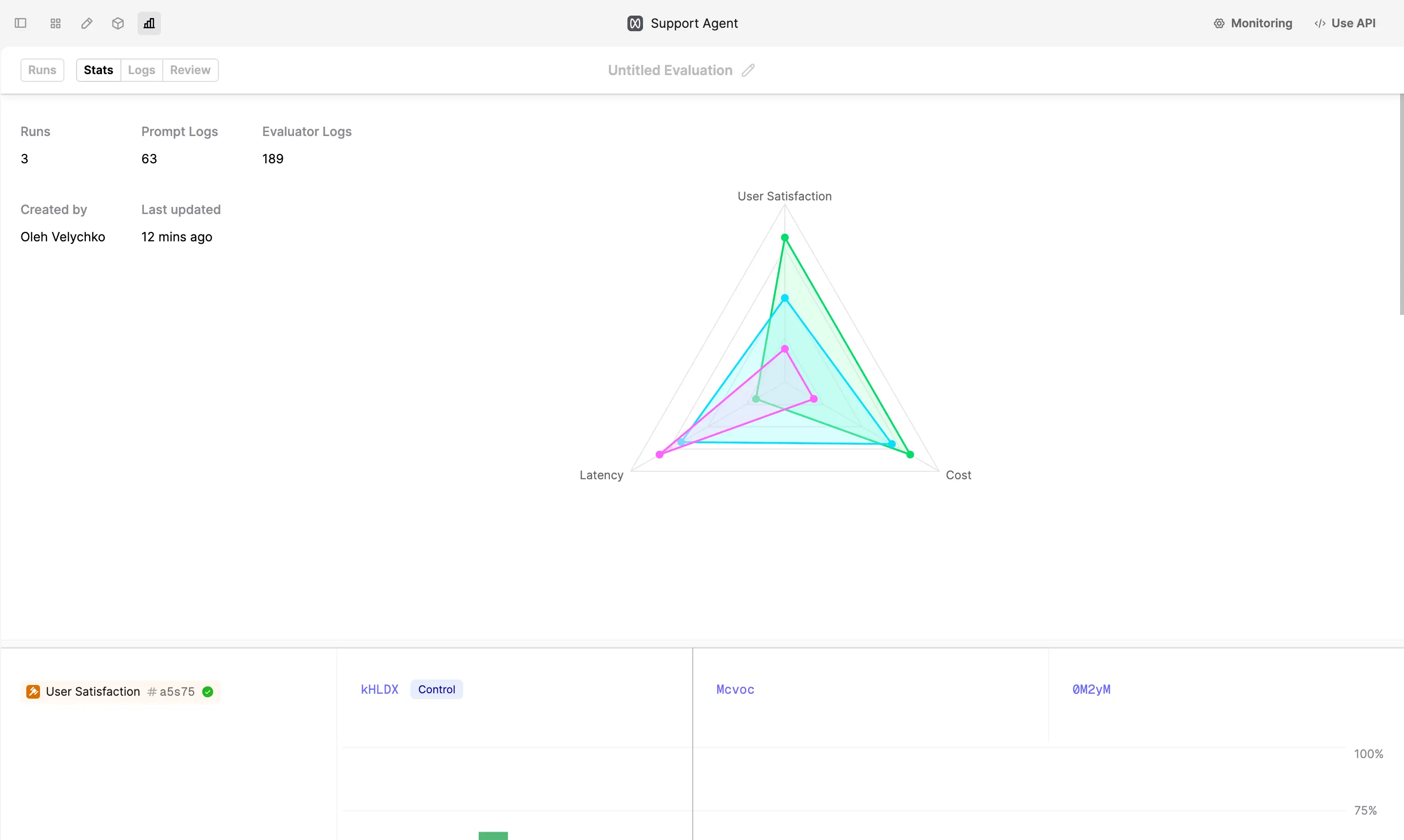
Below the spider plot, you’ll see the breakdown of performance per evaluator.
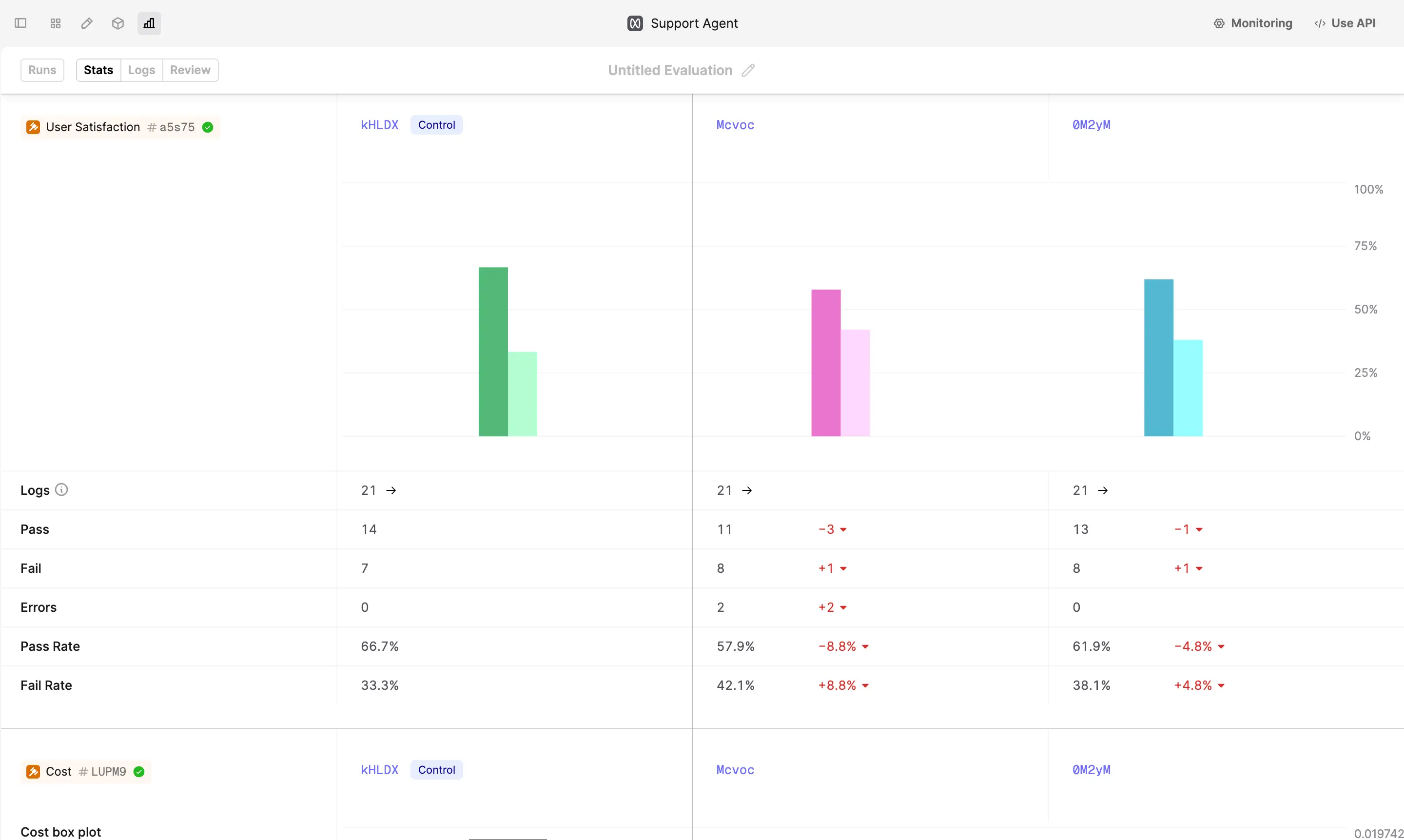
You can also debug the generated logs via the “Review” tab.
Best Practices for Using LLM as a Judge
Some key practices to consider when using LLM as a judge include:
- Leverage high-quality datasets and synthetic data: Leverage high-quality datasets and synthetic data: Combine real user interactions, academic benchmarks, and synthetic data to build comprehensive evaluation datasets. Synthetic data can supplement limited datasets, while real user interactions provide valuable insights.
- Define clear evaluation criteria and use model-sourced judgments: Establish specific evaluation criteria tailored to your use case, such as factual accuracy or relevance. Leverage public LLM benchmarks to validate your evaluator’s performance against established standards before trusting it for production use.
- Collaboration and iteration: Involve domain experts and non-technical stakeholders in evaluation design and refinement. Treat evaluation as an ongoing process that adapts to new data.
Benefits of LLM as a Judge
LLM-as-a-judge offers a scalable, flexible, and efficient alternative to traditional evaluation methods.
1. Scalability for Large-scale Evaluations
One of the biggest advantages of LLM-as-a-judge is its ability to evaluate large amounts of data quickly and consistently. Traditional human evaluations are time-consuming and resource-intensive, making them impractical for large datasets or continuous monitoring.
As generative AI applications scale, the volume of outputs requiring evaluation scales exponentially. For example, a customer support chatbot might generate thousands of responses a day. LLM-as-a-judge can assess these outputs in real-time or batch mode - without bottlenecks.
2. Flexibility Across Use Cases
LLM judges can be customized to evaluate various criteria - from factual accuracy to tone and relevance. This flexibility makes them suitable for diverse applications.
Fixed LLM metrics like BLEU or ROGUE are limited to specific tasks like translation or summarization. On the other hand, LLM judges can adapt to subjective and context-specific needs. For example, a legal document generator can focus on precision and compliance with legal standards.
3. Nuanced Understanding Beyond Traditional Metrics
Traditional evaluation metrics often fail to capture the complexity of open-ended AI-generated outputs. Instead, LLM judges excel at understanding nuances like context and style. These are qualities that are difficult to quantify with rule-based systems.
Many generative tasks don’t have a single “correct” answer. Summarizing an article or responding to a user query might involve multiple valid outputs. LLM judges can effectively assess these nuanced qualities.
One example is that an LLM judge evaluating summaries could assess whether they are concise yet comprehensive while maintaining the original text’s meaning. Traditional metrics often struggle with this.
4. Cost-effectiveness Compared to Human Evaluation
Human evaluation is not only time-consuming but also expensive. This is especially true when domain expertise is required. LLM-as-a-judge significantly reduces costs by automating evaluations while maintaining high levels of accuracy.
Consequently, enterprises don’t need to rely on large teams of human reviewers for tasks like grading chatbot responses or testing new prompts. An enterprise testing multiple versions of a prompt for a conversational AI system can use an LLM judge to compare outputs and select the best-performing one without human evaluators.
5. Continuous Monitoring and Real-time Feedback
LLM judges enable real-time evaluation of AI systems in production environments. Enterprises can continuously monitor performance and detect issues as they arise.
Additionally, continuous monitoring ensures that models remain aligned with desired outcomes even after deployment. It also helps identify helpful trends or anomalies that might require attention, like a sudden increase in unhelpful responses.
Challenges of Using LLM as a Judge
Despite offering a flexible and scalable way to evaluate AI outputs, it comes with various challenges. These issues can affect the reliability, consistency, and fairness of evaluations.
Here are five key challenges, along with some practical solutions to address them:
1. Bias in Evaluations
LLM judges are prone to various biases. This includes:
- Verbosity bias (favoring longer responses)
- Positional bias (favoring the first response in pairwise comparisons)
- Self-enhancement bias (favoring outputs generated by the same model)
These biases can skew evaluations, leading to inaccurate or unfair results. For example, in pairwise comparison, an LLM judge might consistently favour the first response - regardless of its quality.
To mitigate this, you’ll want to regularly test the evaluator on a labeled dataset and correct systematic biases. Additionally, consider using prompt engineering, such as randomising the order of responses in pairwise comparisons.
2. Lack of Consistency
LLM judges are inherently non-deterministic. They can produce different evaluations for the same input under identical conditions. This variability undermines trust in the evaluation process and makes it difficult to reproduce results. An LLM judge might rate the same chatbot response as “helpful” in one run but “unhelpful” in another due to slight variations in sampling.
One solution would be to use few-shot examples within prompts to guide the model toward consistent decision-making. Another would be to implement aggregation techniques, like running multiple evaluations and averaging scores or selecting the majority label.
3. Difficulty Handling Complex Tasks
LLMs often struggle to evaluate tasks requiring deep reasoning, domain expertise, or mathematical precision. If an LLM cannot solve a problem, it’s unlikely to evaluate others’ solutions accurately. This can be seen in a scenario where an LLM judge might fail to evaluate multi-step mathematical reasoning tasks correctly because it struggles with the underlying logic.
To counteract this, supplement LLM judges with domain-specific fine-tuning by training them on datasets tailored to complex tasks. You’ll also want to combine LLM evaluators with human oversight for highly specialised tasks.
4. Sensitivity to Prompt Design
The quality of an LLM judge’s evaluation greatly depends on how the prompts are written. Poorly designed prompts may lead to ambiguous or irrelevant judgements. Notably, even small changes in phrasing could lead to drastically different results.
A vague prompt like “Is this response good?” might result in inconsistent or unhelpful evaluations compared to a detailed prompt specifying criteria, such as clarity and relevance.
It’s important to invest time in iterative prompt refinement, testing multiple versions of prompts on labeled datasets. Additionally, you’ll want to include clear instructions and examples within prompts to reduce ambiguity. Look into using tools like Humanloop’s evaluation platform for structured prompt experimentation.
5. Limited Explainability
Typically, LLM judges provide scores or labels without explaining their reasoning, making it difficult to understand why a particular evaluation was made. This lack of transparency hinders debugging and alignment with human expectations. For instance, an LLM judge might rate a response as “irrelevant” without explaining the problematic part of the output.
Use prompts explicitly requesting explanations alongside scores, such as “rate this response from 1-5 for relevance and explain your reasoning”. Moreover, incorporate self-improvement mechanisms, where human corrections are stored as examples for future evaluations.
Learn More About LLM-as-a-Judge
LLM-as-a-judge is reshaping how enterprises evaluate and scale AI applications offering a powerful framework to automate quality control while maintaining alignment with human judgment. By integrating LLM evaluators into development and production pipelines, teams can ensure their AI systems delive consistent, reliable outputs as they tackle increasingly complex and open-ended tasks.
At Humanloop, we empower enterprises to implement LLM-as-a-judge with precision and confidence. Ready to change how you evaluate and scale AI systems?
Book a demo today to see how Humanloop’s platform can help adopt LLM judges to build trustworthy, enterprise-grade AI.
About the author

- 𝕏@conorkellyai










