Set up LLM as a Judge
In this guide, we will set up an LLM evaluator to check for PII (Personally Identifiable Information) in Logs.
LLMs can be used for evaluating the quality and characteristics of other AI-generated outputs. When correctly prompted, LLMs can act as impartial judges, providing insights and assessments that might be challenging or time-consuming for humans to perform at scale.
In this guide, we’ll explore how to setup an LLM as an AI Evaluator in Humanloop, demonstrating their effectiveness in assessing various aspects of AI-generated content, such as checking for the presence of Personally Identifiable Information (PII).
An AI Evaluator is a Prompt that takes attributes from a generated Log (and optionally from a testcase Datapoint if comparing to expected results) as context and returns a judgement. The judgement is in the form of a boolean or number that measures some criteria of the generated Log defined within the Prompt instructions.
Prerequisites
You should have an existing Prompt to evaluate and already generated some Logs. Follow our guide on creating a Prompt.
In this example we will use a simple Support Agent Prompt that answers user queries about Humanloop’s product and docs.

Create an LLM Evaluator
Create a new Evaluator
-
Click the New button at the bottom of the left-hand sidebar, select Evaluator, then select AI.
-
Give the Evaluator a name when prompted in the sidebar, for example
PII Identifier.
Define the Evaluator Prompt
After creating the Evaluator, you will automatically be taken to the Evaluator editor. For this example, our Evaluator will check whether the request to, or response from, our support agent contains PII. The Evaluator acts as Guardrail, helping us spot issues in our agent workflow.
- Make sure the Mode of the Evaluator is set to Online in the options on the left.
- Copy and paste the following Prompt into the Editor:
Available Prompt Variables
In the Prompt Editor for an LLM evaluator, you have access to the underlying log you are evaluating as well as the testcase Datapoint that gave rise to it if you are using a Dataset for offline Evaluations.
These are accessed with the standard {{ variable }} syntax, enhanced with a familiar dot notation to pick out specific values from inside the log and testcase objects.
For example, suppose you are evaluating a Log object like this.
In the LLM Evaluator Prompt, {{ log.inputs.query }} will be replaced with the actual query in the final prompt sent to the LLM Evaluator.
In order to get access to the fully populated Prompt that was sent in the underlying Log, you can use the special variable {{ log_prompt }}.
Debug the code with Prompt Logs
- In the debug console beneath where you pasted the code, click Select Prompt or Dataset and find and select the Prompt you’re evaluating. The debug console will load a sample of Logs from that Prompt.
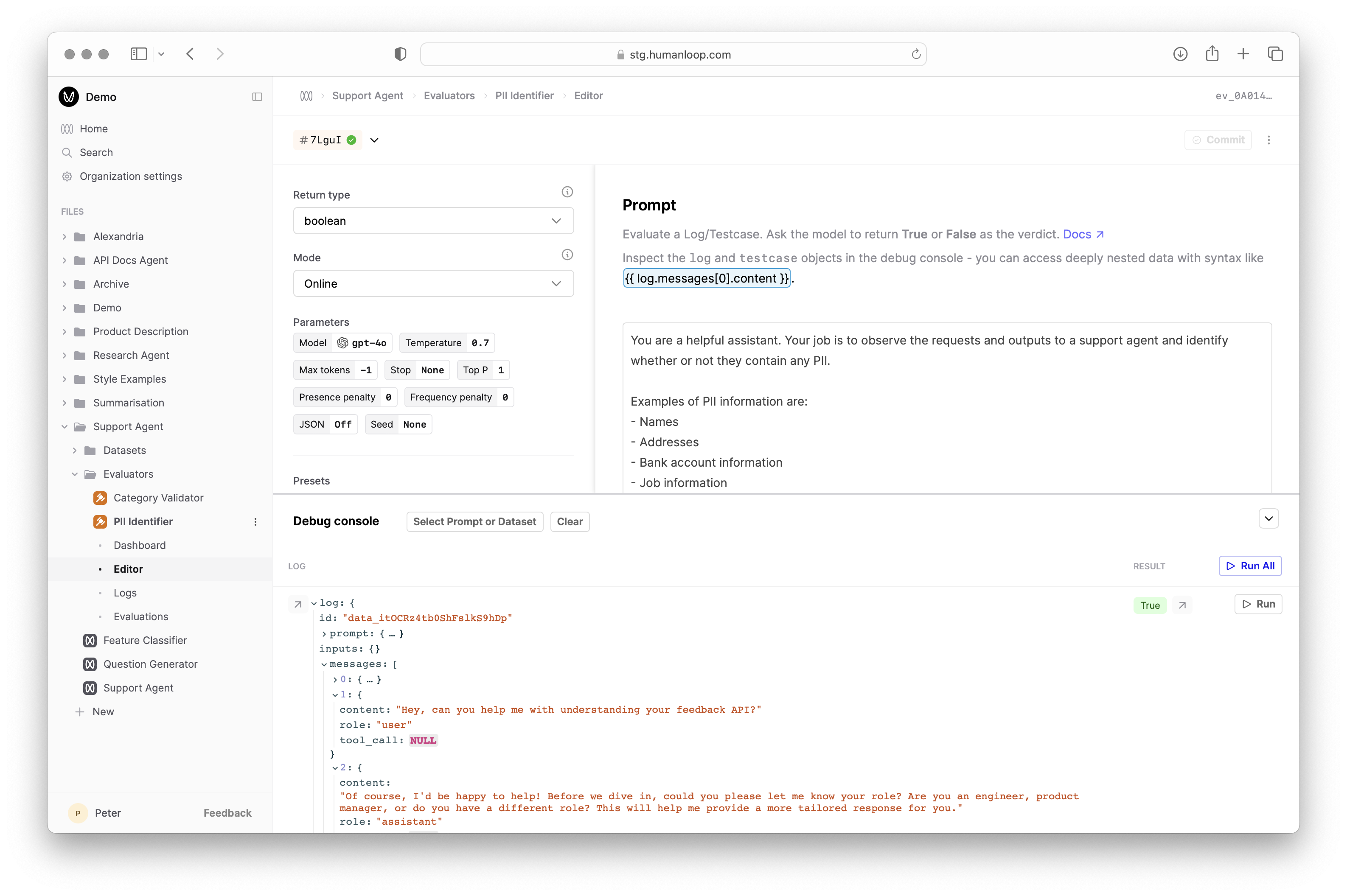
- Click the Run button at the far right of one of the loaded Logs to trigger a debug run. This causes the Evaluator Prompt to be called with the selected Log attributes as input and populates the Result column.
- Inspect the output of the executed code by selecting the arrow to the right of Result.
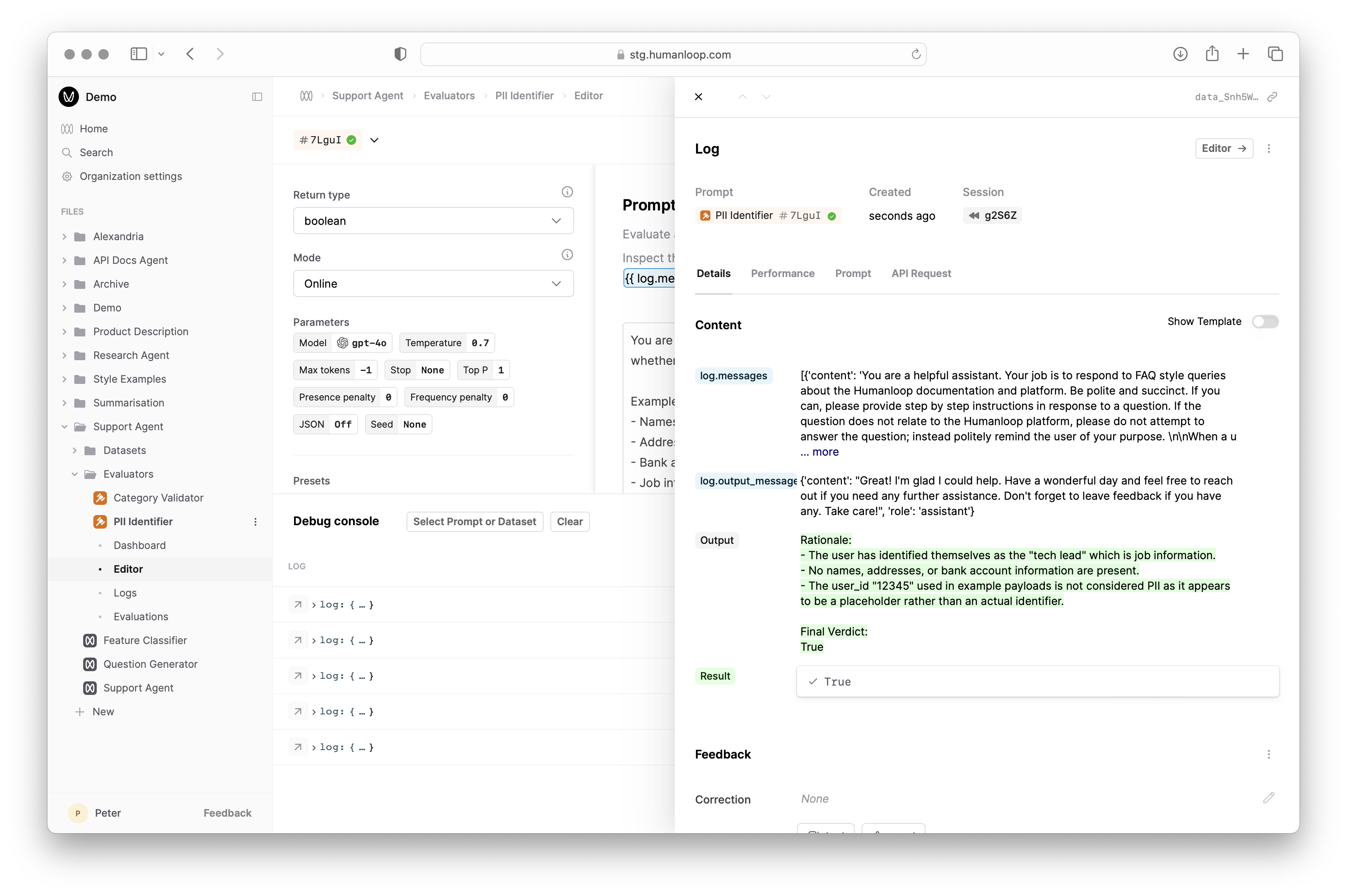
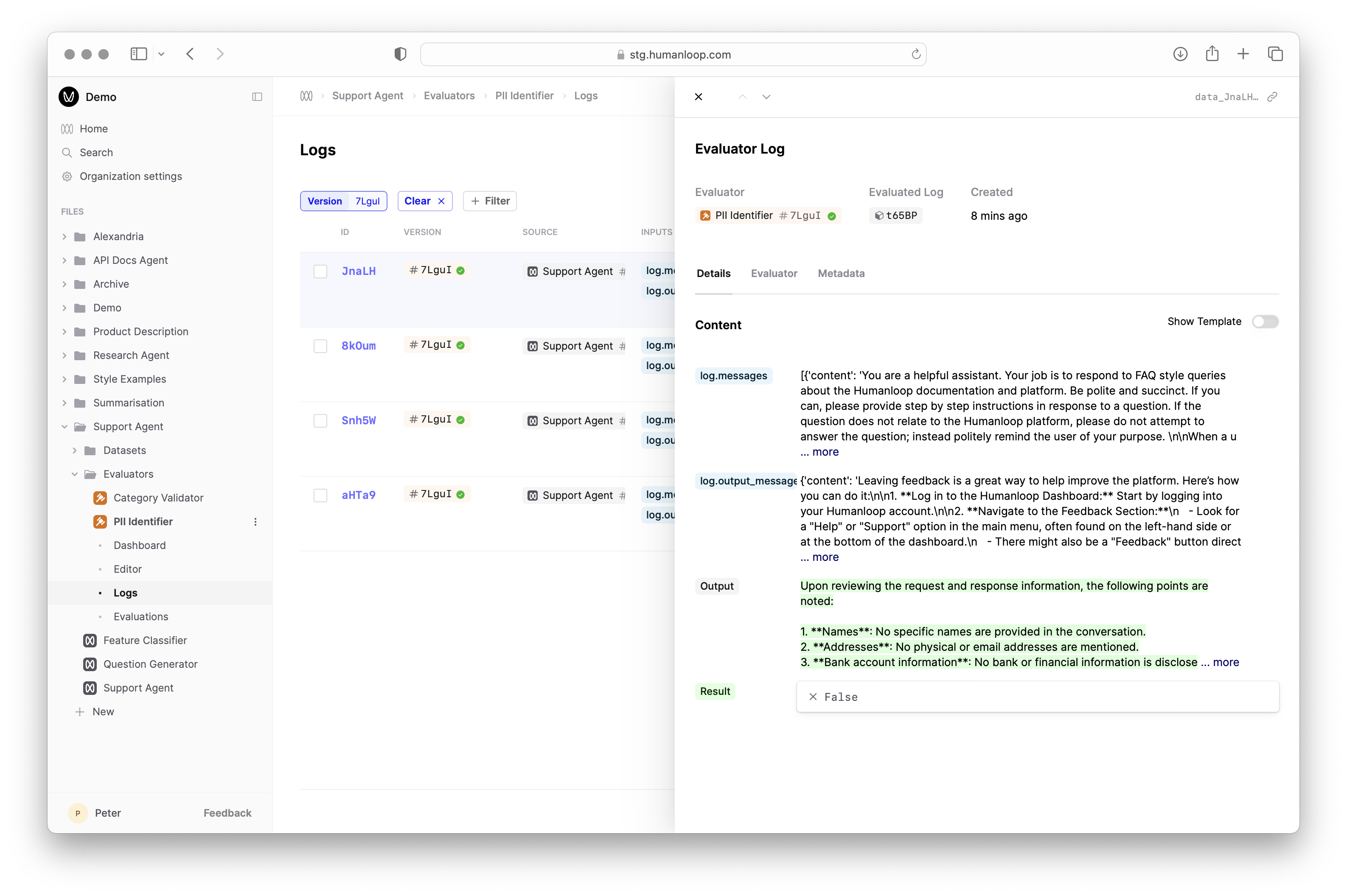
Next steps
- Explore Code Evaluators and Human Evaluators to complement your AI judgements.
- Combine your Evaluator with a Dataset to run Evaluations to systematically compare the performance of different versions of your AI application.