Evaluate an Agent in code
Humanloop offers first-class support for agents on its runtime. This tutorial provides guidance on how to instrument existing code-based agentic systems with Humanloop.
Check out our Evaluating Agents in UI tutorial for a more streamlined experience, including tool calling on the Humanloop runtime, and autonomous agents.
Working with LLMs is daunting: you are dealing with a black box that outputs unpredictable results.
Humanloop provides tools to make your development process systematic, bringing it closer to traditional software testing and quality assurance.
In this tutorial, we’ll build an agentic question-and-answer system and use Humanloop to iterate on its performance. The agent will provide simple, child-friendly answers using Wikipedia as its source of factual information.
Prerequisites
Account setup
Create a Humanloop Account
If you haven’t already, create an account or log in to Humanloop
Add an OpenAI API Key
If you’re the first person in your organization, you’ll need to add an API key to a model provider.
- Go to OpenAI and grab an API key.
- In Humanloop Organization Settings set up OpenAI as a model provider.
Using the Prompt Editor will use your OpenAI credits in the same way that the OpenAI playground does. Keep your API keys for Humanloop and the model providers private.
Install dependencies
Python
TypeScript
Install the project’s dependencies:
Humanloop SDK requires Python 3.9 or higher. Optionally, create a virtual environment to keep dependencies tidy.
Initial agent code
Let’s build the first iteration of the agent. We’ll use OpenAI’s function calling to connect the agent to the Wikipedia API. The agent will also be allowed to refine its answer through multiple iterations if the initial tool call doesn’t yield relevant information.
Run the agent and check that it works as expected:
Python
TypeScript
Add Humanloop to the agent
Humanloop offers first-class support for agentic systems, plus the ability to effortlessly switch between providers.
Evaluate the agent
How Evaluators work
Evaluators are callables that take the Log’s dictionary representation as input and return a judgment. The Evaluator’s judgment should respect the return_type present in the Evaluator’s specification.
The Evaluator can take an additional target argument to compare the Log against. The target is provided in an Evaluation context by the validation Dataset.
For more details, check out our Evaluator explanation.
Let’s check if the agent respects the requirement of providing easy-to-understand answers.
We will create an Evaluation to benchmark the performance of the agent. An Evaluation requires a Dataset and at least one Evaluator.
Create LLM judge
We will use an LLM judge to automatically evaluate the agent’s responses.
We will define the Evaluator in code, but you can also manage Evaluators in the UI.
Replace your main function with the following:
Iterate and evaluate again
The score of the initial setup is quite low. Click the Evaluation link from the terminal and switch to the Logs view. You will see that the model tends to provide elaborate answers.

Python
TypeScript
Let’s modify the LLM prompt inside call_model:
Run the agent again and let the Evaluation finish:
Click the Evaluation link again. The agent’s performance has improved significantly.

Add detailed logging
Up to this point, we have treated the agent as a black box, reasoning about its behavior by looking at the inputs and outputs.
Let’s use Humanloop logging to observe the step-by-step actions taken by the agent.
Python
TypeScript
Modify main.py:
Evaluate the agent again. When it’s done, head to your workspace and click the Agent Flow on the left. Select the Logs tab from the top of the page.
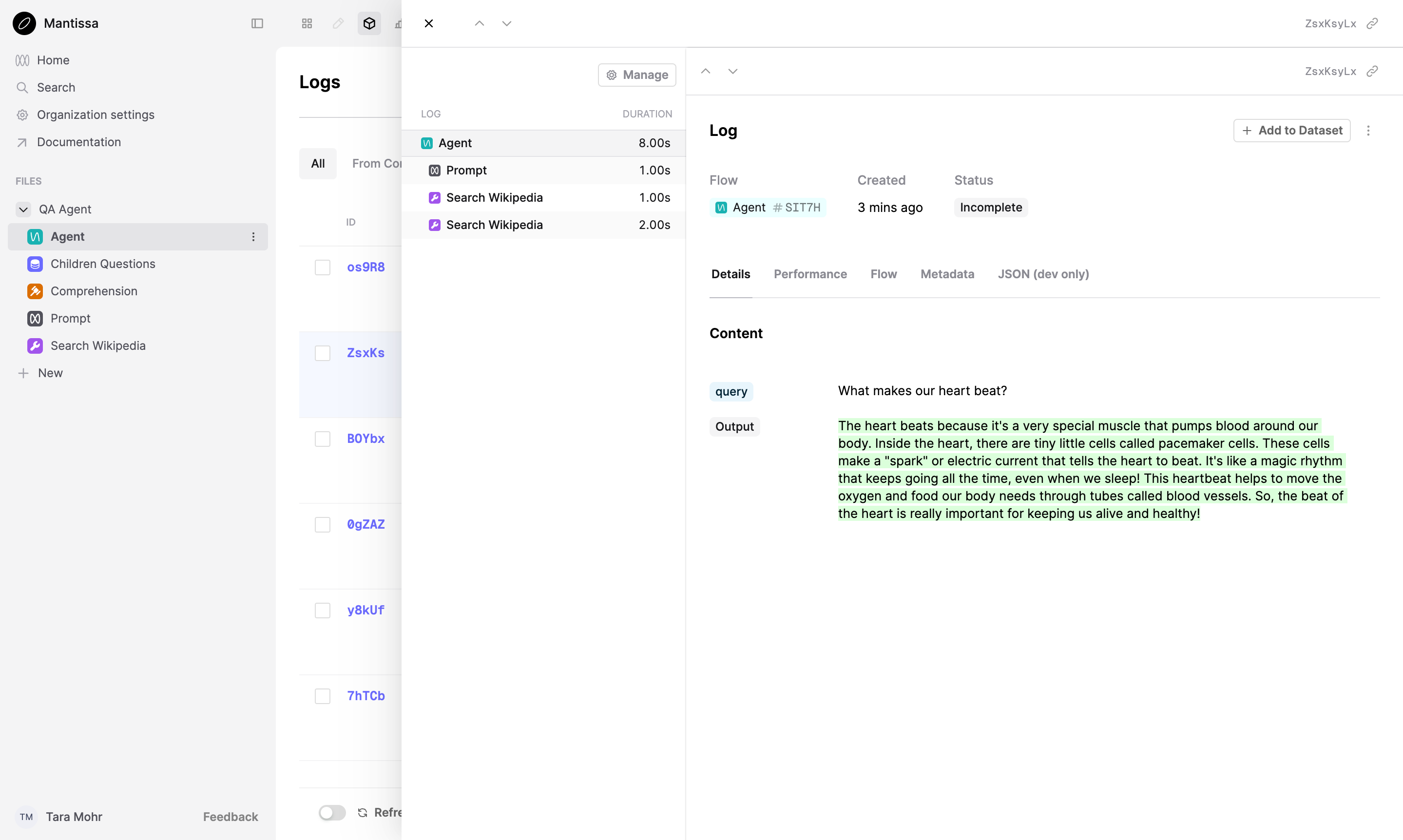
The decorators divide the code in logical components, allowing you to observe the steps taken to answer a question. Every step taken by the agent creates a Log.
Next steps
We’ve built a complex agentic workflow and learned how to use Humanloop to add logging to it and evaluate its performance.
Take a look at these resources to learn more about evals on Humanloop:
-
Learn how to create a custom dataset for your project.
-
Learn more about using LLM Evaluators on Humanloop.