Set up a code Evaluator
A code Evaluator is a Python function that takes a generated Log (and optionally a testcase Datapoint if comparing to expected results) as input and returns a judgement. The judgement is in the form of a boolean or number that measures some criteria of the generated Log defined within the code.
Code Evaluators provide a flexible way to evaluate the performance of your AI applications, allowing you to re-use existing evaluation packages as well as define custom evaluation heuristics.
We support a fully featured Python environment; details on the supported packages can be found in the environment reference
Prerequisites
You should have an existing Prompt to evaluate and already generated some Logs. Follow our guide on creating a Prompt.
In this example, we’ll reference a Prompt that categorises a user query about Humanloop’s product and docs by which feature it relates to.
Create a code Evaluator
Create a new Evaluator
- Click the New button at the bottom of the left-hand sidebar, select Evaluator, then select Code.
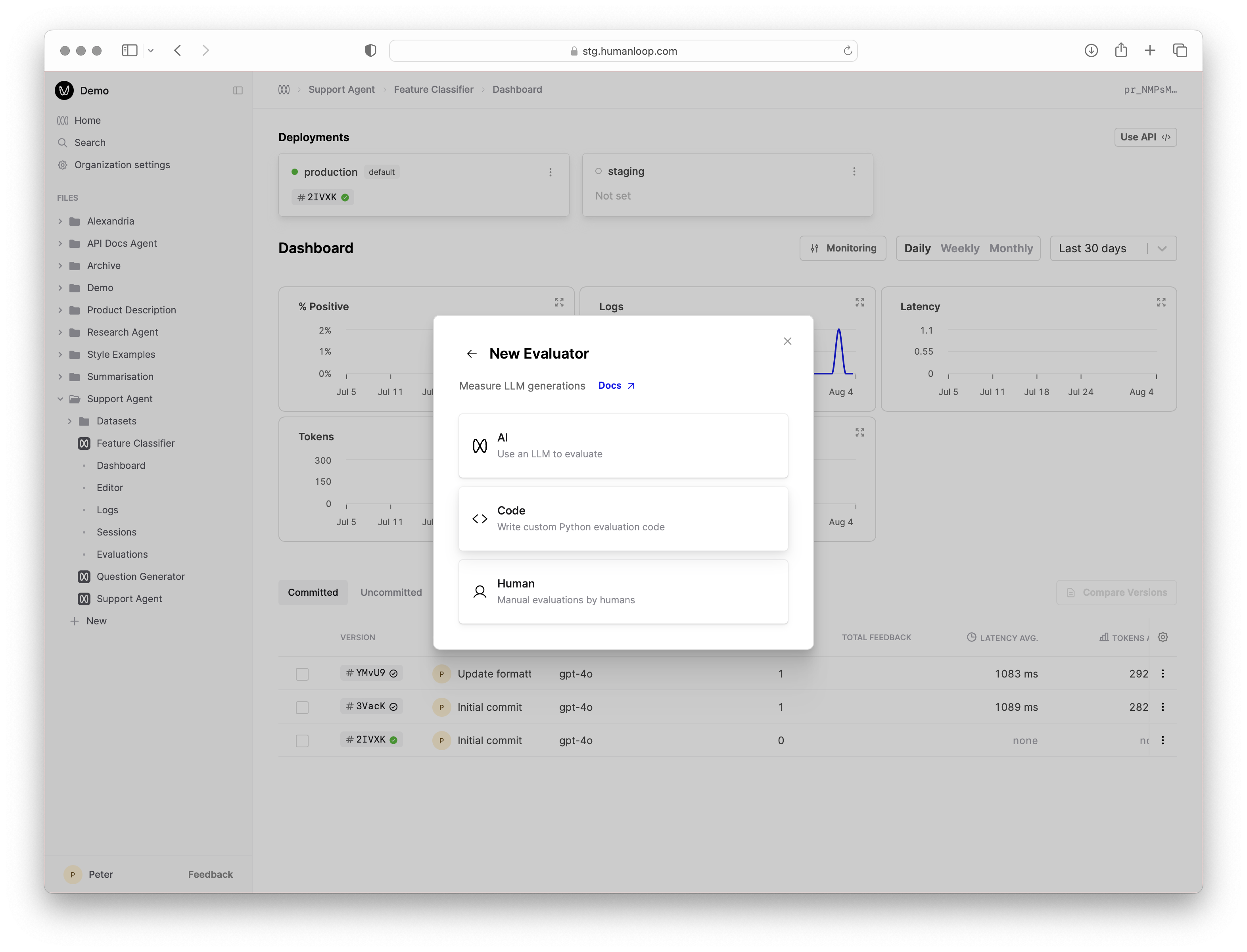
- Give the Evaluator a name when prompted in the sidebar, for example
Category Validator.
Define the Evaluator code
After creating the Evaluator, you will automatically be taken to the code editor. For this example, our Evaluator will check that the feature category returned by the Prompt is from the list of allowed feature categories. We want to ensure our categoriser isn’t hallucinating new features.
- Make sure the Mode of the Evaluator is set to Online in the options on the left.
- Copy and paste the following code into the code editor:
Code Organisation
You can define multiple functions in the code Editor to organize your evaluation logic. The final function defined is used as the main Evaluator entry point that takes the Log argument and returns a valid judgement.
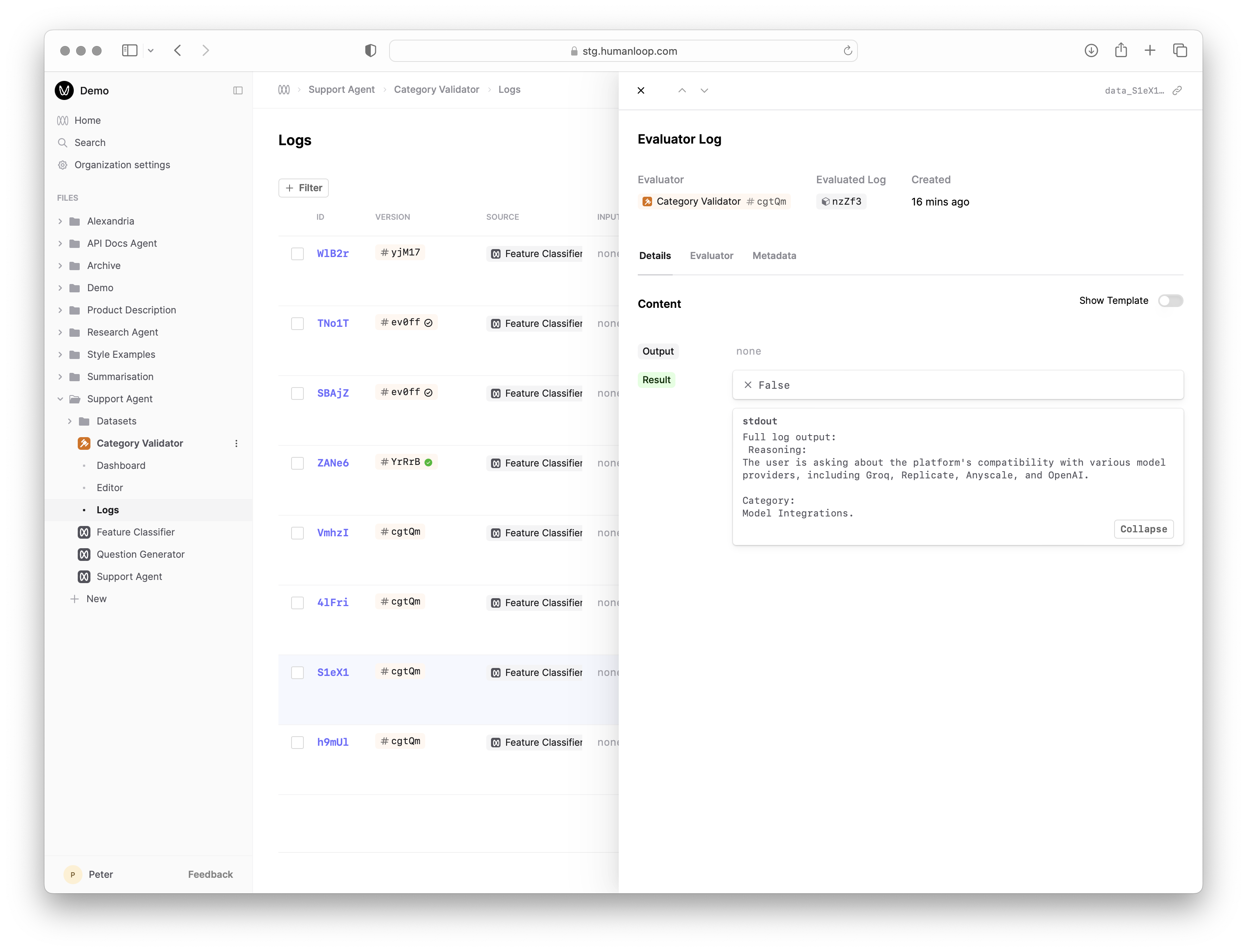
Debug the code with Prompt Logs
- In the debug console beneath where you pasted the code, click Select Prompt or Dataset and find and select the Prompt you’re evaluating. The debug console will load a sample of Logs from that Prompt.
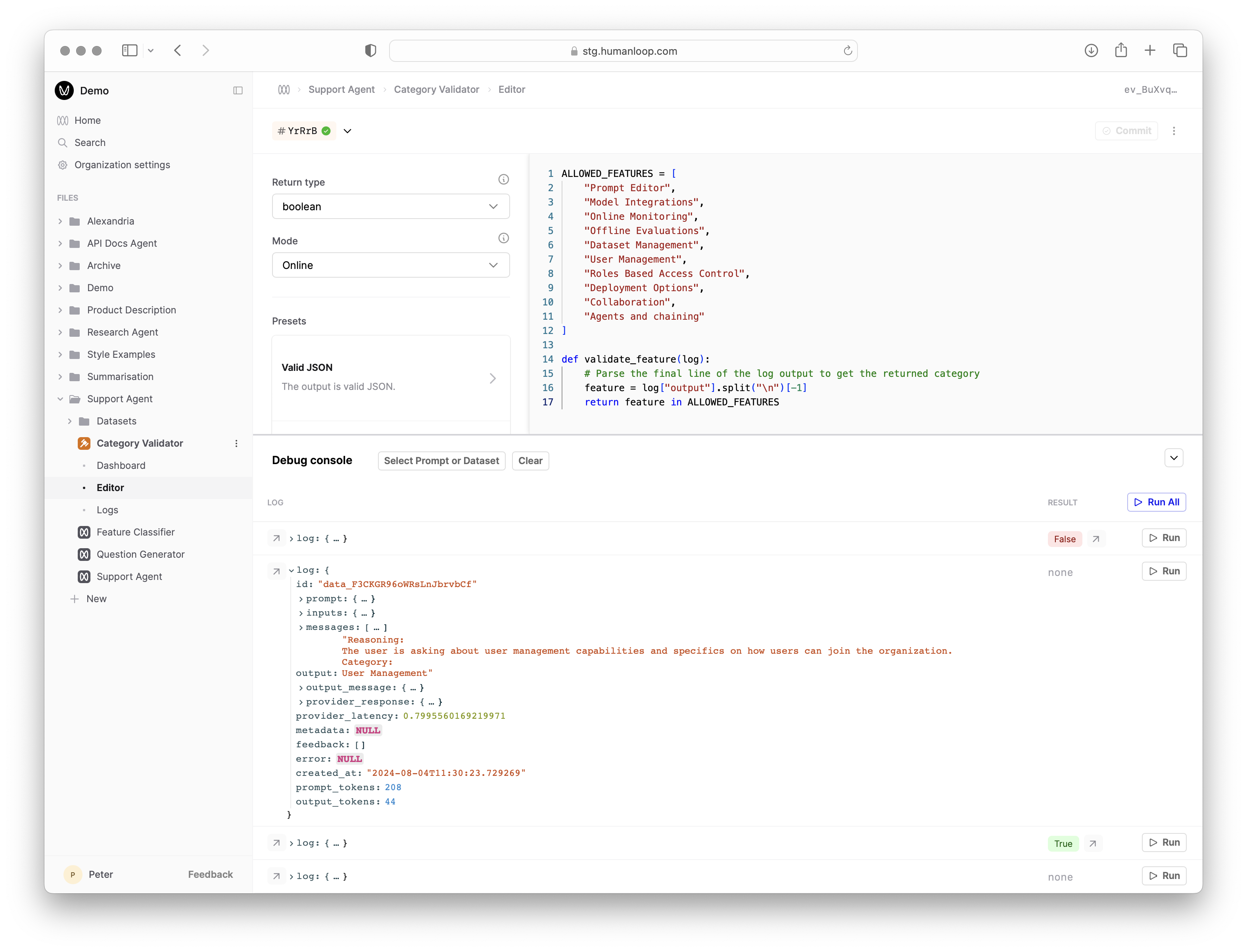
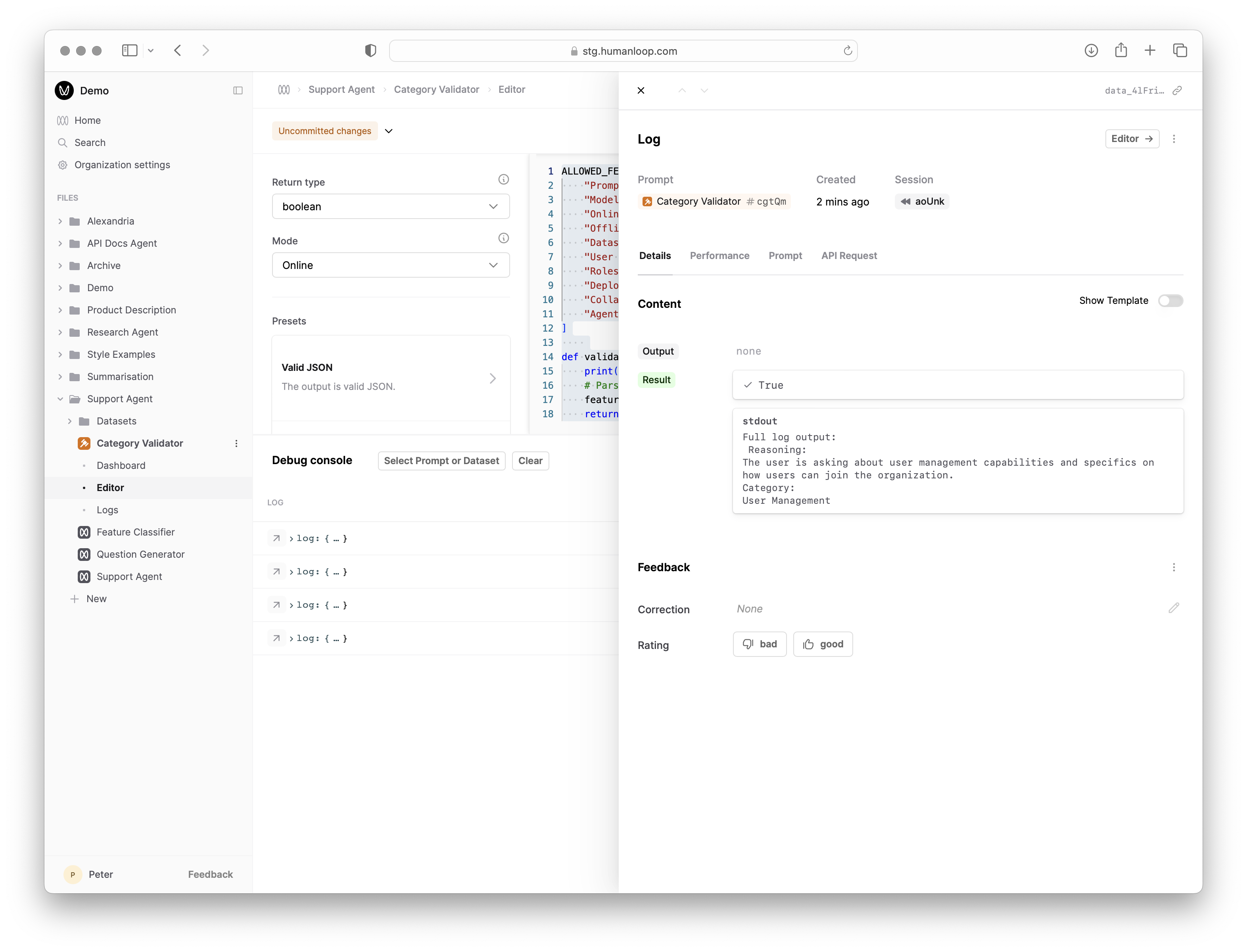
- Click the Run button at the far right of one of the loaded Logs to trigger a debug run. This causes the code to be executed with the selected Log as input and populates the Result column.
- Inspect the output of the executed code by selecting the arrow to the right of Result.
Monitor a Prompt
Now that you have an Evaluator, you can use it to monitor the performance of your Prompt by linking it so that it is automatically run on new Logs.
Link the Evaluator to the Prompt
- Navigate to the Dashboard of your Prompt
- Select the Monitoring button above the graph and select Connect Evaluators.
- Find and select the Evaluator you just created and click Chose.
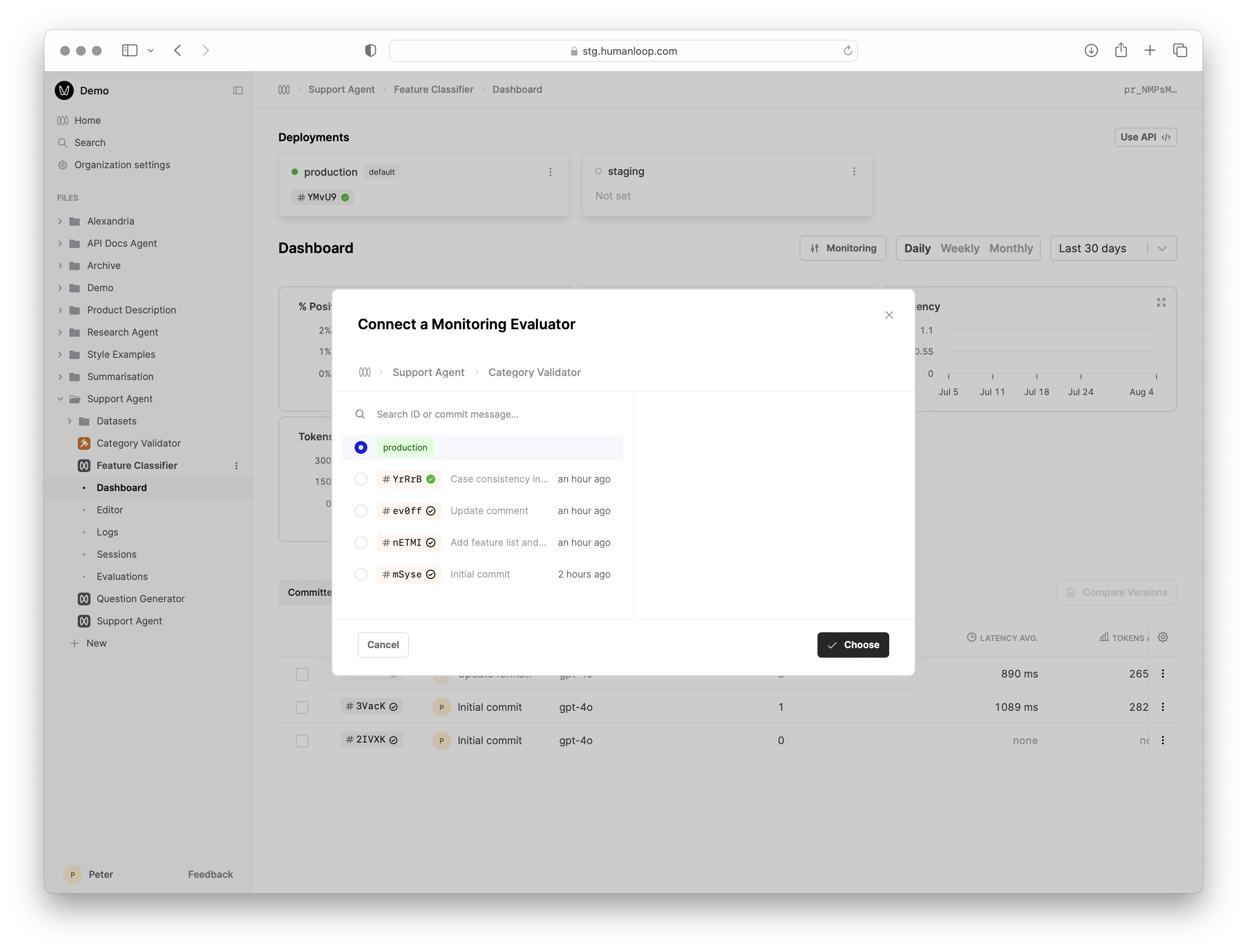
Linking Evaluators for Monitoring
You can link to a deployed version of the Evaluator by choosing the
environment such as production, or you can link to a specific version of the
Evaluator. If you want changes deployed to your Evaluator to be automatically
reflected in Monitoring, link to the environment, otherwise link to a specific
version.
This linking results in: - An additional graph on your Prompt dashboard showing the Evaluator results over time. - An additional column in your Prompt Versions table showing the aggregated Evaluator results for each version. - An additional column in your Logs table showing the Evaluator results for each Log.
Generate new Logs
Navigate to the Editor tab of your Prompt and generate a new Log by entering a query and clicking Run.
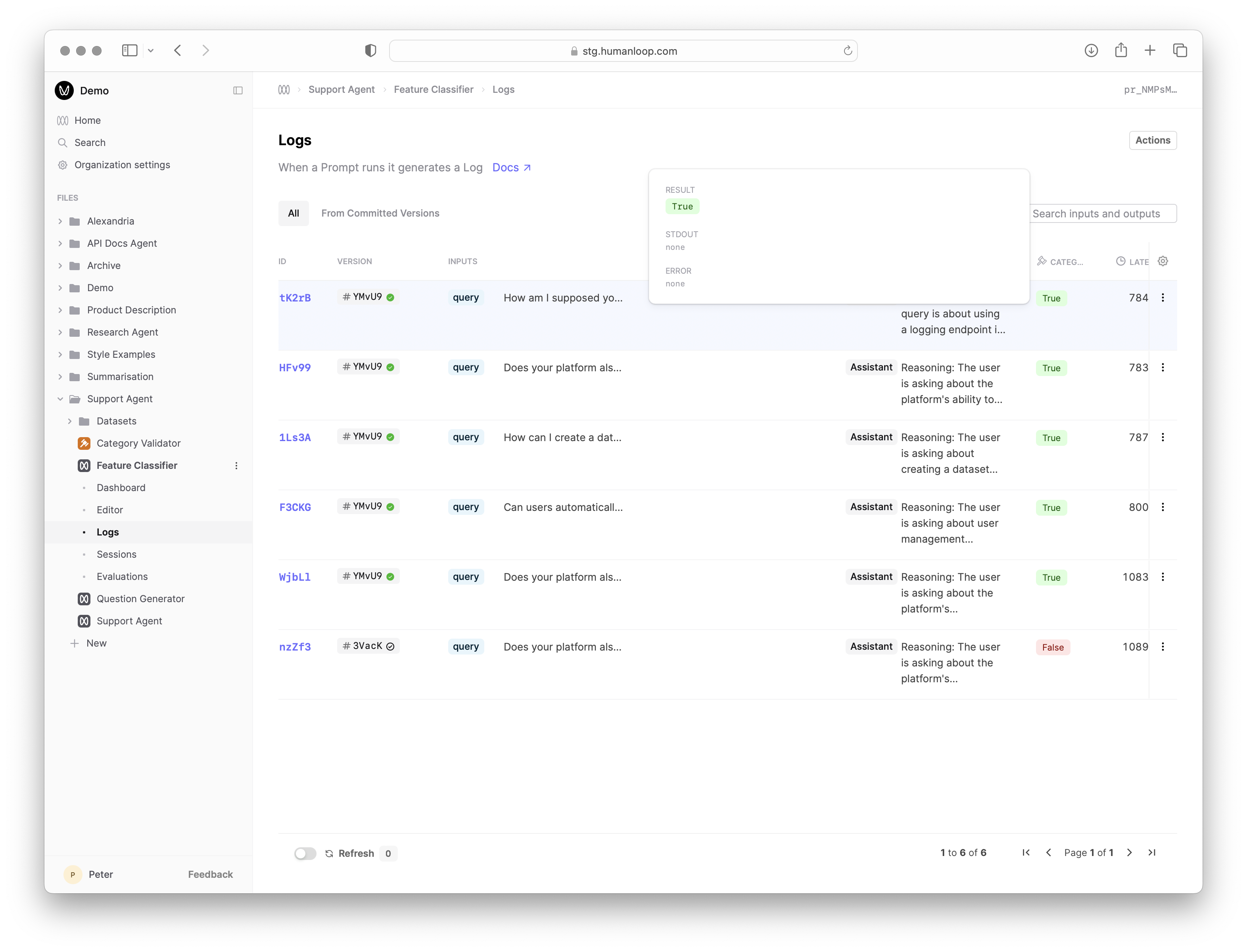
Inspect the Monitoring results
Navigate to the Logs tab of your Prompt and see the result of the linked Evaluator against the new Log. You can filter on this value in order to create a Dataset of interesting examples.
Evaluating a Dataset
When running a code Evaluator on a Dataset, you can compare a generated Log to each Datapoint’s target. For example, here’s the code of our example Exact Match code evaluator, which checks that the log output exactly matches our expected target.
Next steps
- Explore AI Evaluators and Human Evaluators to complement your code-based judgements for more qualitative and subjective criteria.
- Combine your Evaluator with a Dataset to run Evaluations to systematically compare the performance of different versions of your AI application.