Run an Evaluation via the UI
An Evaluation on Humanloop leverages a Dataset, a set of Evaluators and different versions of a Prompt to compare.
The Dataset contains datapoints describing the inputs (and optionally the expected results) for a given task. The Evaluators define the criteria for judging the performance of the Prompts when executed using these inputs.
Prompts, when evaluated, produce Logs. These Logs are then judged by the Evaluators. You can see the summary of Evaluators judgments to systematically compare the performance of the different Prompt versions.
Prerequisites
- A set of Prompt versions you want to compare - see the guide on creating Prompts.
- A Dataset containing datapoints for the task - see the guide on creating a Dataset.
- At least one Evaluator to judge the performance of the Prompts - see the guides on creating Code, AI and Human Evaluators.
Run an Evaluation via UI
For this example, we’re going to evaluate the performance of a Support Agent that responds to user queries about Humanloop’s product and documentation.
Our goal is to understand which base model between gpt-4o, gpt-4o-mini and claude-3-5-sonnet-20241022 is most appropriate for this task.
Navigate to the Evaluations tab of your Prompt
- Go to the Prompt you want to evaluate and then click on Evaluations tab at the top of the page.
- Click the Evaluate button top right to create a new Evaluation.
- Click the +Run button top right to create a new Evaluation Run.
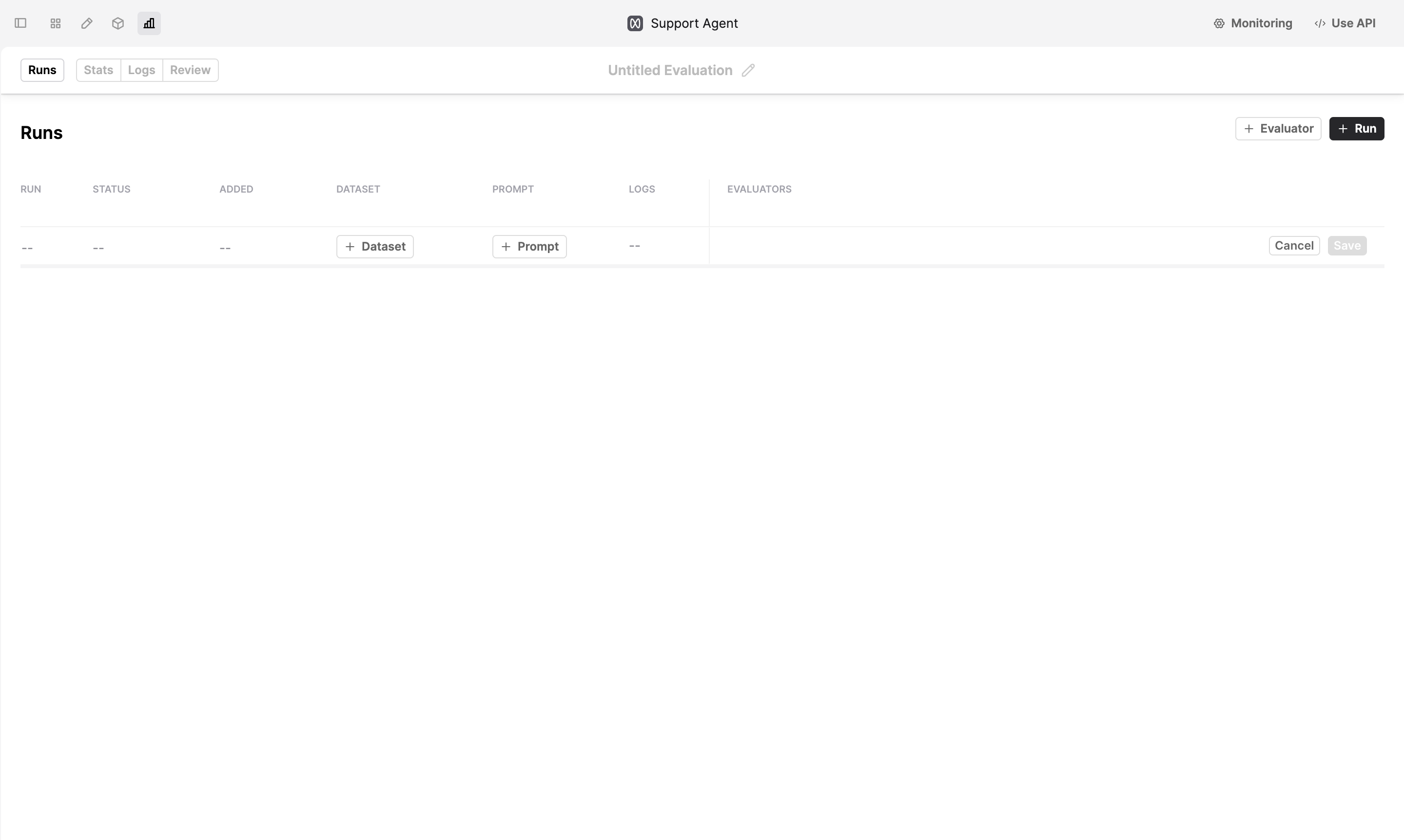
Set up an Evaluation Run
- Select a Dataset using +Dataset.
- Add the Prompt versions you want to compare using +Prompt.
- Add the Evaluators you want to use to judge the performance of the Prompts using +Evaluator.
Log Caching
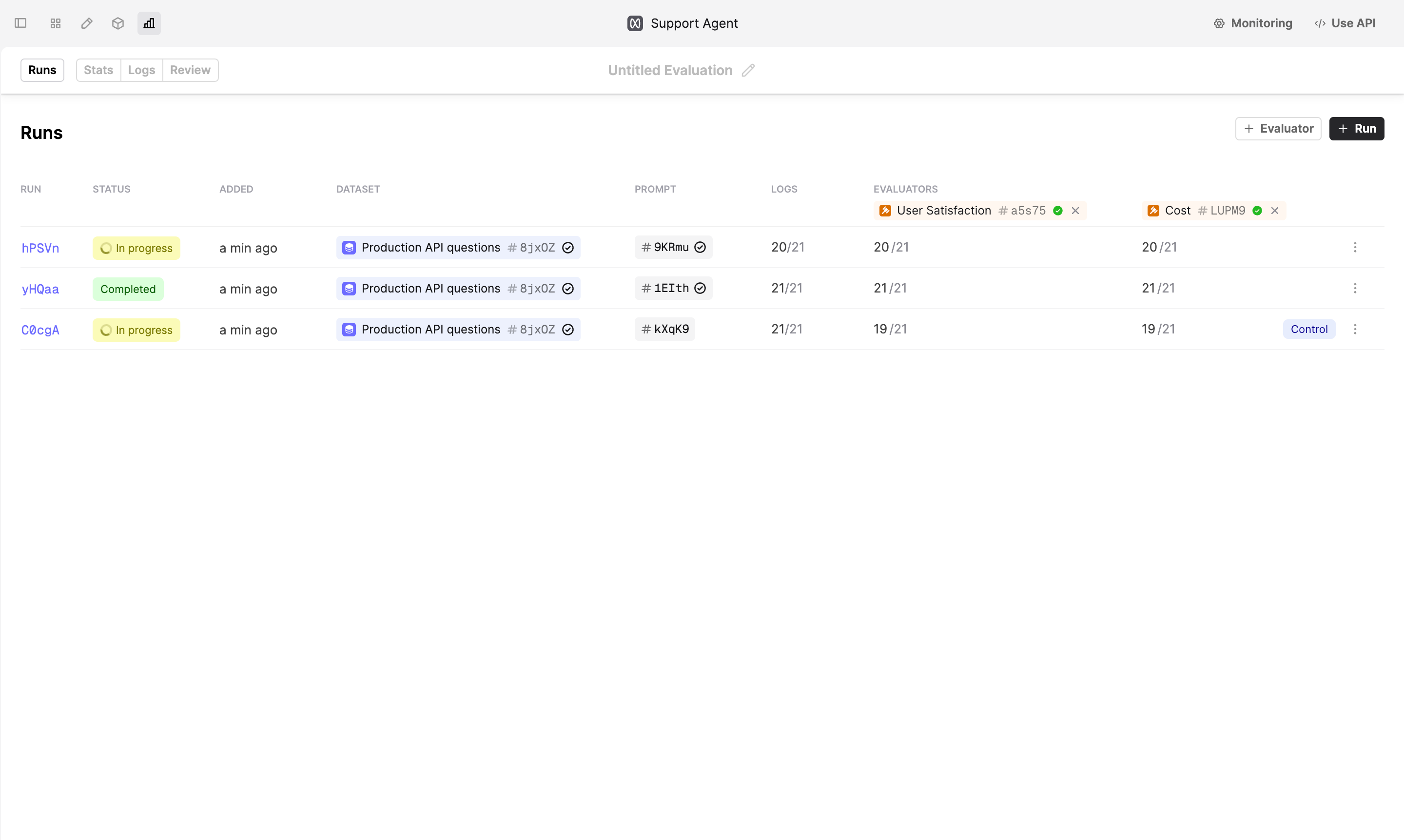
By default the system will re-use Logs if they exist for the chosen Dataset, Prompts and Evaluators. This makes it easy to extend Evaluation Run without paying the cost of re-running your Prompts and Evaluators.
If you want to force the system to re-run the Prompts against the Dataset producing a new batch of Logs, you can click on regenerate button next to the Logs count
- Click Save. Humanloop will start generating Logs for the Evaluation.
Using your Runtime
This guide assumes both the Prompt and Evaluator Logs are generated using the Humanloop runtime. For certain use cases where more flexibility is required, the runtime for producing Logs instead lives in your code - see our guide on Logging, which also works with our Evaluations feature. We have a guide for how to run Evaluations with Logs generated in your code coming soon!
Review the results
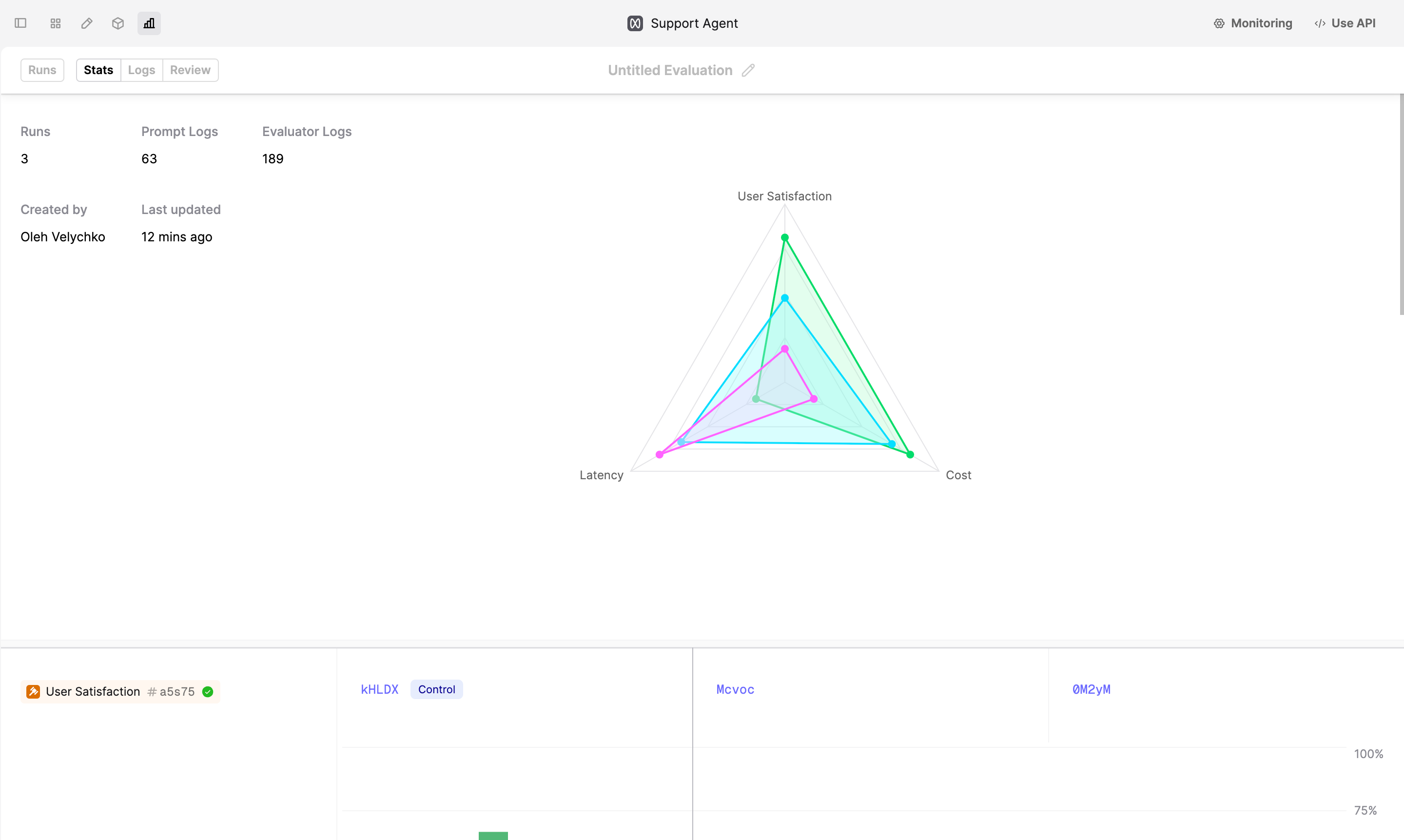
Once the Logs are produced, you can review the performance of the different Prompt versions by navigating to the Stats tab.
- The top spider plot provides you with a summary of the average Evaluator performance across all the Prompt versions.
In our case,
gpt-4o, although on average slightly slower and more expensive on average, is significantly better when it comes to User Satisfaction.
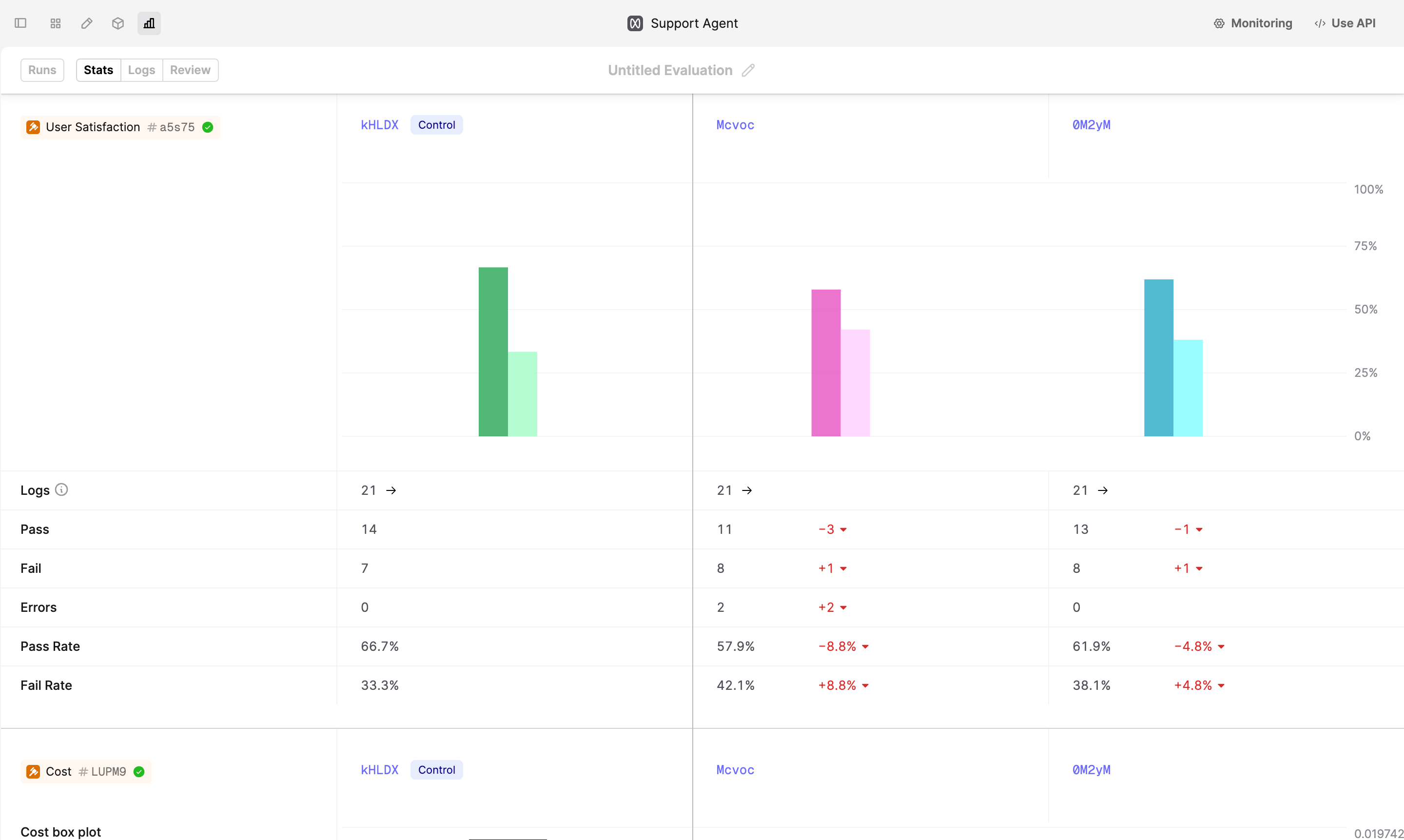
- Below the spider plot, you can see the breakdown of performance per Evaluator.
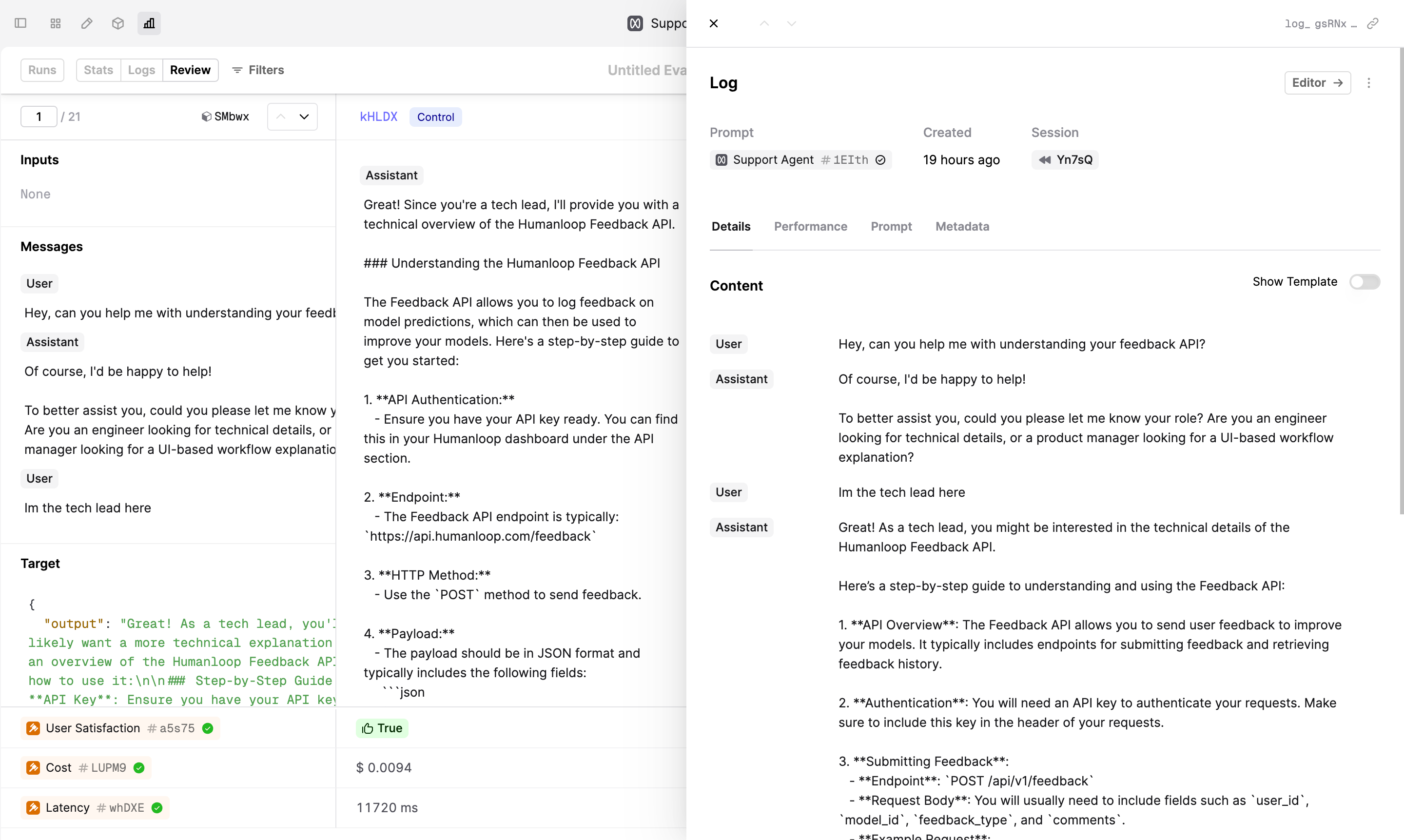
- To drill into and debug the Logs that were generated, navigate to the Review tab at top left of the Run page. The Review view allows you to better understand performance and replay logs in our Prompt Editor.
Next Steps
- Incorporate this Evaluation process into your Prompt engineering and deployment workflow.
- Setup Evaluations where the runtime for producing Logs lives in your code - see our guide on Logging.
- Utilise Evaluations as part of your CI/CD pipeline