Evaluate a RAG app
Use Humanloop to evaluate more complex workflows like Retrieval Augmented Generation (RAG).
This tutorial demonstrates how to take an existing RAG pipeline and use Humanloop to evaluate it. At the end of the tutorial you’ll understand how to:
- Run an Eval on your RAG pipeline.
- Set up detailed logging with SDK decorators.
- Log to Humanloop manually
The full code for this tutorial is available in the Humanloop Cookbook.
Example RAG Pipeline
In this tutorial we’ll first implement a simple RAG pipeline to do Q&A over medical documents without Humanloop. Then we’ll add Humanloop and use it for evals. Our RAG system will have three parts:
- Dataset: A version of the MedQA dataset from Hugging Face.
- Retriever: Chroma as a simple local vector DB.
- Prompt: Managed in code, populated with the user’s question and retrieved context.
Set up RAG pipeline
Set up environment variables:
Set up the Vector DB:
Define the Prompt:
Define the RAG Pipeline:
Run the pipeline:
Run an Evaluation
Now we will integrate Humanloop into our RAG pipeline to evaluate it. We will use the Humanloop SDK to run an Eval on our RAG pipeline.
Initialize the Humanloop SDK:
Set up Evaluators
Our Dataset has ground truth answers we can compare against. It’s very unlikely that the AI answers are exactly the same as the answers but we can measure how close they are by using the “Levenshtein distance” Evaluator. The code for this Evaluator is in the cookbook. We can run the Evaluator locally. However, if we upload it to Humanloop, we get the added benefit that Humanloop can run the Evalaution for us and this can be integrated into CI/CD.
Create a Dataset
We upload a test dataset to Humanloop:
Run Eval
Now that we have our Flow, our Dataset and our Evaluators we can create and run an Evaluation.
Add detailed logging
One limitation of our Evaluation so far is that we’ve measured the app end-to-end but we don’t know how the different components contribute to performance. If we really want to improve our app, we’ll need to log the full trace of events, including separate Tool and Prompt steps:
We can do this by adding logging for the Prompt and Tool steps within the Flow using Humanloop’s Python decorators. If you’re using a different language, you can still log to Humanloop via the API. Skip to the “Logging with the API” section below or check out our guide for more details.
You can now run the pipeline as before and the full trace will be logged to Humanloop.
Re-run the Evaluation
These decorated functions can similarly be used to run an Eval on the pipeline. This will allow you to evaluate the pipeline and see the detailed logs for each step in the pipeline.
Let’s change from gpt-4o-mini to gpt-4o and re-run the Eval.
By passing in the same name to humanloop.evaluations.run(...) call, we’ll add another run to the previously-created Evaluation on Humanloop. This will allow us to compare the two Runs side-by-side.
Viewing our Evaluation on Humanloop, we can see that our newly-added Run with gpt-4o has been added to the Evaluation.
On the Stats tab, we can see that gpt-4o scores better for our “Exact match” (and “Levenshtein”) metrics, but has higher latency.
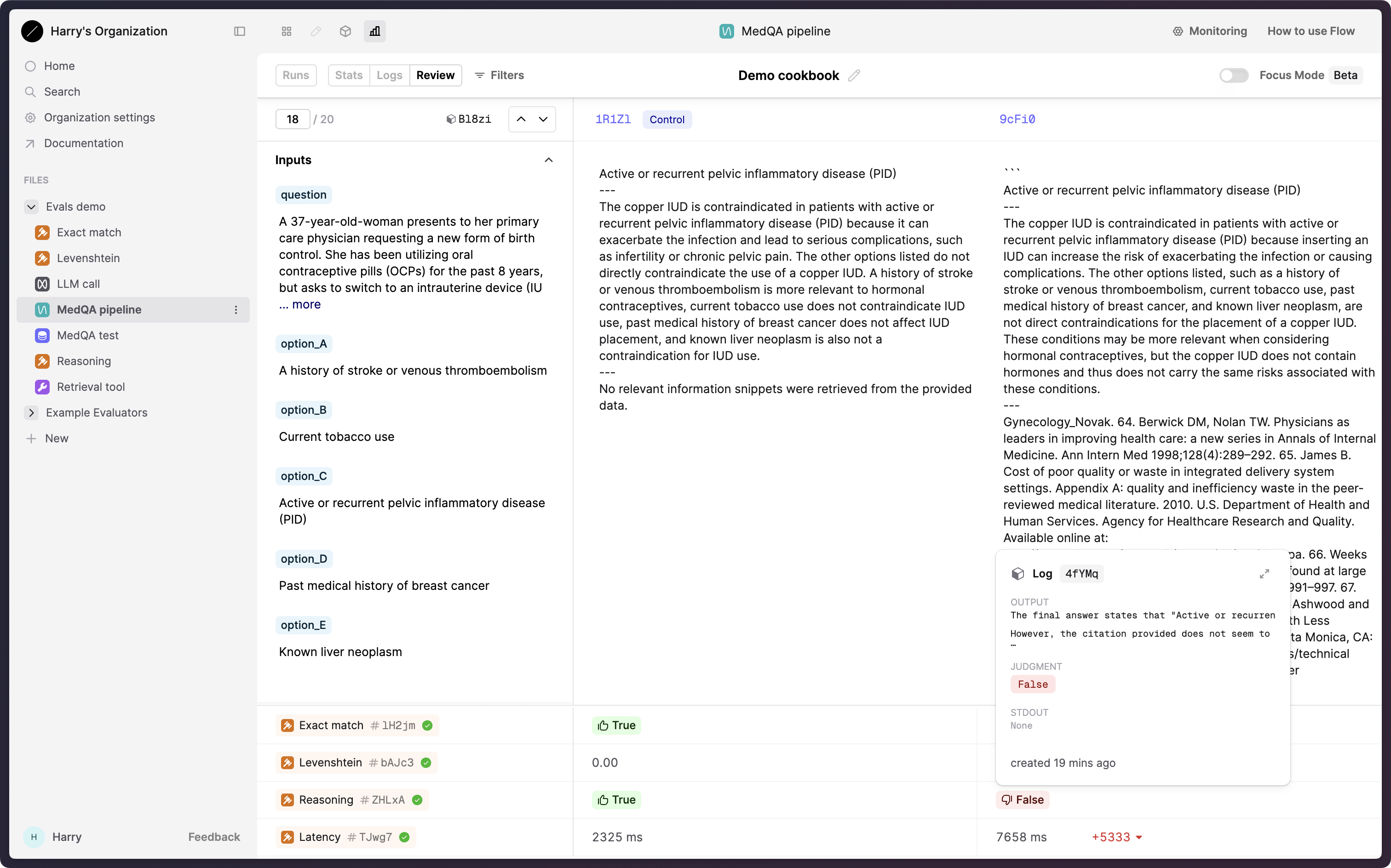
Perhaps surprisingly, gpt-4o performs worse according to our “Reasoning” Evaluator.
Logging with the API
Above, we’ve let the SDK handle logging and versioning for us. However, you can also log data to Humanloop using the API directly. This can be useful if you want to perform some post-processing on the data before logging it, or if you want to include additional metadata in the logs or versions.
We’ll now demonstrate how to extend your Humanloop logging with more fidelity; creating Tool, Prompt, and Flow Logs to give you full visibility.
We add additional logging steps to our ask_question function to represent the full trace of events on Humanloop.
(Note that the run_id and source_datapoint_id arguments are optional, and are included here for use in the Evaluation workflow demonstrated later.)
The logging we’ve added here is similar to the SDK decorators we used earlier.
Run an Evaluation using the API
To orchestrate your own Evaluations, you can pass in run_id and source_datapoint_id to the humanloop.flows.log(...) call to associate Logs with a specific Run and Datapoint.
The following is an example of how you can manually create an Evaluation and Run, and log data to Humanloop using the API, giving you full control over the Evaluation process.
You can then similarly view results on the Humanloop UI.
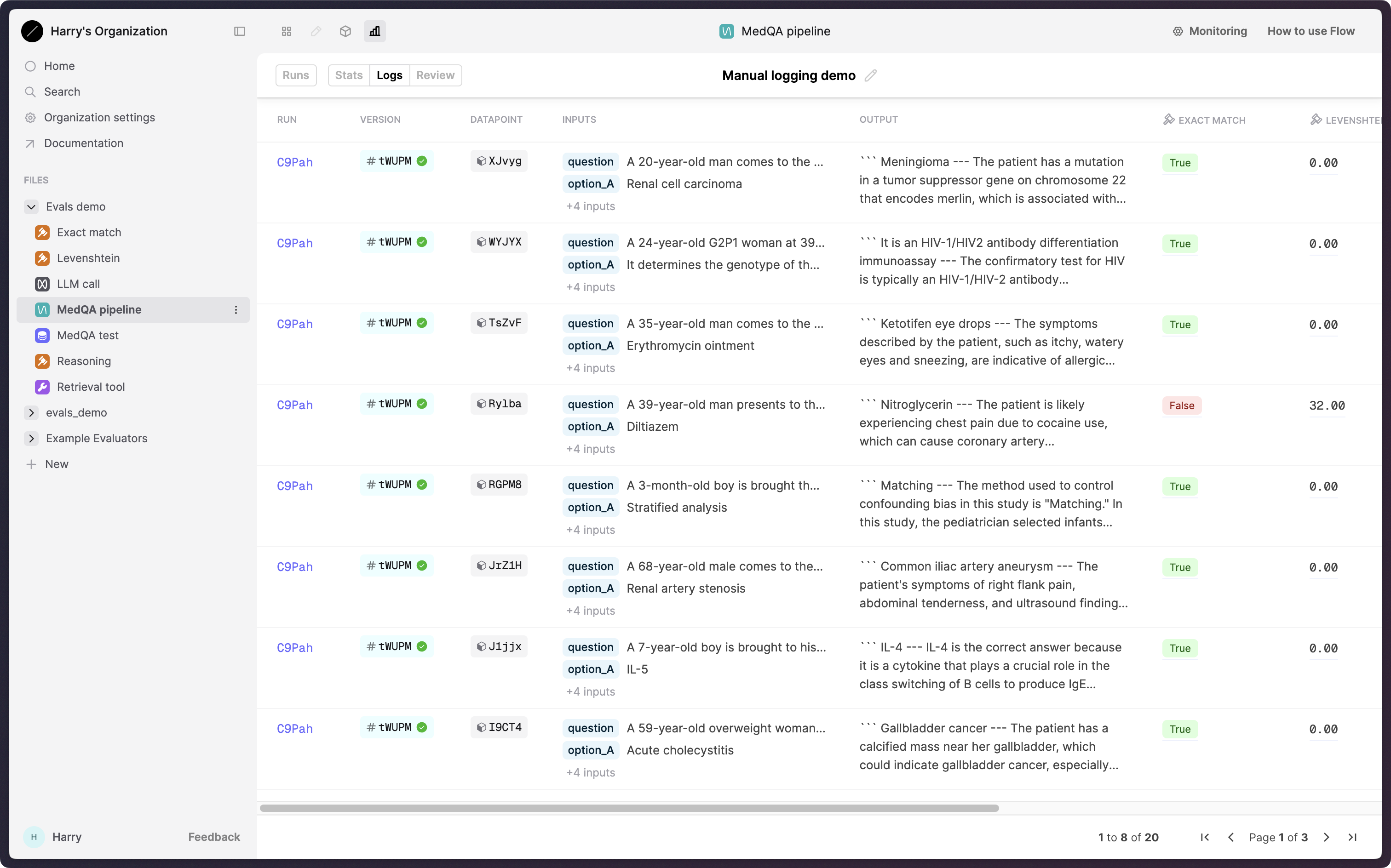
This concludes the Humanloop RAG Evaluation walkthrough. You’ve learned how to integrate Humanloop into your RAG pipeline, set up logging, create Datasets, configure Evaluators, run Evaluations, and log the full trace of events including Tool and Prompt steps.