How to Build the Right Team for Generative AI
Generative AI and Large Language Models (LLMs) are new to most companies. If you’re an engineering leader building Gen AI applications, it can be hard to know what skills and types of people are needed. At Humanloop we’ve helped hundreds of companies put Large Language Models (LLMs) into production and in this post I’d like to share what we’ve learned about the skills needed to build a great AI team.
You probably don’t need ML engineers
In the last two years, the technical sophistication needed to build with AI has dropped dramatically. At the same time, the capabilities of AI models have grown. This creates an incredible opportunity for more companies to adopt AI because you probably already have most of the talent you need in-house.
Machine learning engineers used to be crucial to AI projects because you needed to train custom models from scratch. Training your own fully bespoke ML models requires more mathematical skills, an understanding of data science concepts, and proficiency with ML tools such as TensorFlow or PyTorch.
Large Language Models like GPT-4, or open-source alternatives like LLaMa, come pre-trained with general knowledge of the world and language. Much less sophistication is needed to use them. With traditional ML, you needed to collect and manually annotate a dataset before designing an appropriate neural network architecture and then training it from scratch. With LLMs, you start with a pre-trained model and can customise that same model for many different applications via a technique called "prompt engineering".
Prompt Engineering is a key skill set
“Prompt engineering” is simply the skill of articulating very clearly in natural language what you want the model to do and ensuring that the model is provided with all the relevant context. These natural language instructions, or “prompts”, become part of your application’s codebase and replace the annotated dataset that you used to have to collect to build an AI product. Prompt engineering is now one of the key skills in AI application development.
To be good at prompt engineering you need excellent written communication, a willingness to experiment and a familiarity with the strengths and weaknesses of modern AI models. You don’t typically need any specific mathematical or technical knowledge. The people most suited for prompt engineering are the domain experts who best understand the needs of the end user - often this is the product managers.
Product Managers and Domain Experts are Increasingly Important
Product managers and domain experts have always been vital for building excellent software but their role is typically one step removed from actual implementation. LLMs change this. They make it possible for non-technical experts to directly shape AI products through prompt engineering. This saves expensive engineering time and also shortens the feedback loop from deployment to improvement.
We see this in action with Humanloop customers like Twain, who use LLMs to help salespeople write better emails. The engineers at Twain build the majority of the application but they’re not well-placed to understand how to write good sales emails because they lack domain knowledge. As a result, they’re not the right people to be customising the AI models. Instead, Twain employs linguists and salespeople as prompt engineers.
Another example is Duolingo, which has built several AI features powered by large language models. Software engineers are not experts in language learning and would struggle to write good prompts for this situation. Instead, the engineers at Duolingo build the skeleton of the application that lives around the AI model and a team of linguists is responsible for prompt development.
Generalist Full-Stack Engineers can outperform AI specialists
The majority of most AI applications are still traditional code. Only the pieces that require complex reasoning are delegated to AI models. The engineering team still build the majority of the application, orchestrate model calls, establish the infrastructure for prompt engineering, integrate data sources to augment the model's context and optimise performance.
When it comes to optimising LLM performance, there are two common techniques which your team will need to be aware of. These are “finetuning” and “retrieval augmented generation” or RAG. Finetuning is when you slightly adjust the model parameters of a pre-trained AI model using example data. RAG is when you augment a generative AI model with traditional information-retrieval to give the model access to private data.
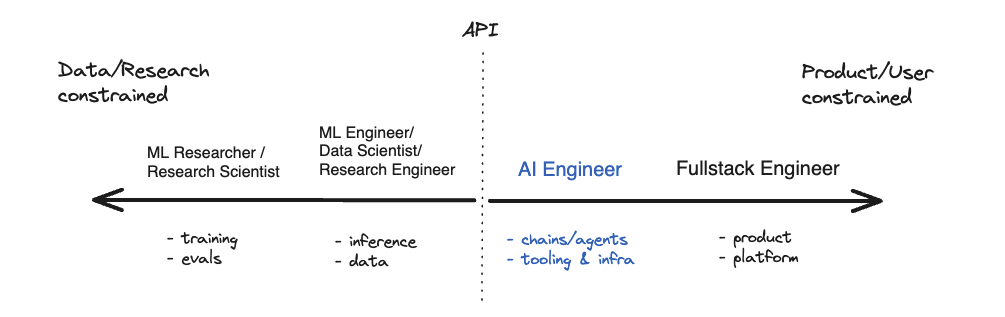
Full-stack engineers with a broad understanding of different technologies, and the ability to learn quickly, should be able to implement both RAG and Finetuning. There’s no need for them to have deep machine-learning knowledge as most models can now be accessed via API and increasingly there are specialist developer tools that make finetuning and RAG straightforward to implement. Compared to Machine Learning specialists, fullstack engineers tend to be more comfortable moving across the stack and are often more product minded. In fact there is a new job title emerging for generalist engineers who have a strong familiarity with LLMs and the tools around them: "The AI Engineer".
Product and engineering teams need to work closely together
One of the challenges of generative AI is that there are a lot of new workflows and most companies lack appropriate tooling. For AI teams to work well, there needs to be an easy way for domain experts to iterate on prompts. However, prompts affect your applications as much as code and so need to be versioned and evaluated with the same level of rigour as code. Traditional software tools like Git are not a good solution because they alienate the non-technical domain experts who are critical to success.
Often, teams end up using a mixture of stitched-together tools like the OpenAI playground, Jupyter notebooks and complex Excel spreadsheets. The process is error-prone and leads to long delays. Building custom internal tools can be very expensive and because the field of AI is evolving so rapidly they’re difficult to maintain.
Humanloop can help here by solving the most critical workflows around prompt engineering and evaluation. We give companies an interactive environment where their domain experts/PMs and engineers can work together to iterate on prompts. Coupled with this are tools for evaluating the performance of AI features in rigorous ways both from user feedback and from automated evaluations.
By providing the right tooling, Humanloop makes it much easier for your existing product teams to become your AI teams.
About the author

- 𝕏@RazRazcle










