Why you should be using active learning to build ML
Why you should be using Active Learning
Data labeling is often the biggest bottleneck in machine learning — finding, managing and labeling vast quantities of data to build a sufficiently performing model can take weeks or months. Active learning lets you train machine learning models with much less labeled data. The best AI-driven companies, like Tesla, already use active learning. We think you should too.
In this post we'll explain what active learning is, discuss tools to use it in practice, and show what we're doing at Humanloop to make it easier for you to incorporate active learning in NLP.
The conventional approach vs active learning - creating a spam filter
Imagine that you wanted to build a spam filter for your emails. The conventional approach (at least since 2002) is to collect a large number of emails, label them as "spam" or "not spam" and then train a machine learning classifier to distinguish between the two classes. The conventional approach assumes all the data is equally valuable, but in most datasets there are class imbalances, noisy data and lots of redundancy.
The conventional approach wastes time labeling data that doesn't improve your model's performance. And you don't even know if your model is useful until you've finished labeling all the data.
Humans don't require thousands of randomly labeled examples to learn the difference between spam and legitimate email. If you were teaching a human to solve this task you'd expect to be able to give them a few examples of what you want, have them learn quickly and ask questions when they were unsure.
Active learning operates using the same intuition, using the model you're training to find and label only the most valuable data.
In active learning, you first provide a small number of labeled examples. The model is trained on this "seed" dataset. Then, the model "asks questions" by selecting the unlabeled data points it is unsure about, so the human can "answer" the questions by providing labels for those points. The model updates again and the process is repeated until the performance is good enough. By having the human iteratively teach the model, it's possible to make a better model, in less time, with much less labeled data.
So how can the model find the next data point that needs labeling? Some commonly used methods are:
-
select the data points where the model's predictive distribution has highest entropy
-
pick data points where the model's favored prediction is least confident
-
train an ensemble of models and focus on the data points where they disagree
At Humanloop we actually use custom methods that leverage Bayesian deep learning to get better uncertainty estimates.
Three Benefits of Using Active Learning
1. You spend less time and money on labeling data
Active learning has been shown to deliver large savings in data labeling across a wide range of tasks and data sets ranging from computer vision to NLP. Since data labeling is one of the most expensive parts of training modern machine learning models this should be enough justification on its own!
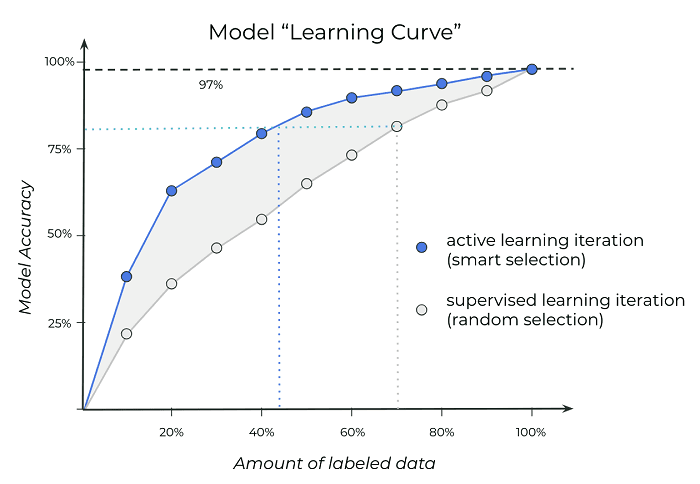
Using active learning gets to higher model accuracies with less labeled data
2. You get much faster feedback on model performance
Usually people label their data before they train any models or get any feedback. Often, it takes days or weeks of iterating on annotation guidelines and re-labeling only to discover that model performance falls far short of what is needed, or different labeled data is required. Since Active Learning trains a model frequently during the data labeling process, its possible to get feedback and correct issues that might otherwise be discovered much later.
3. Your model will have higher final accuracy
People are often surprised that models trained with active learning not only learn faster but can actually converge to a better final model (with less data). We're told so often that more data is better, that it's easy to forget that the quality of the data matters just as much as the quantity. If the dataset contains ambiguous examples which are hard to label accurately this can actually degrade your final model performance.
The order the model sees examples also matters. There's an entire sub-field of machine learning, called curriculum learning, which studies how you can improve model performance by first teaching about simple concepts before teaching complex ones. Think "arithmetic before advanced calculus". Active learning naturally enforces a curriculum on your models and helps them achieve better overall performance.
If active learning is so great, then why doesn't everyone use it?
Most of our tools and processes for building machine learning models weren't designed with Active Learning in mind. There are often different teams of people responsible for data labeling vs model training but active learning requires these processes to be coupled. If you do get these teams to work together, you still need a lot of infrastructure to connect model training to annotation interfaces. Most of the software libraries being used assume all of your data is labeled before you train a model, so to use active learning you have to write a tonne of boiler plate. You also need to figure out how best to host your model, have the model communicate with a team of annotators and update itself as it gets data asynchronously from different annotators.
On top of this, modern deep learning models are very slow to update, so frequently retraining them from scratch is painful. Nobody wants to label a hundred examples then wait 24 hours for a model to be fully re-trained before labeling the next 100. Deep learning models also tend to have millions or billions of parameters and getting good uncertainty estimates from these models is an open research problem.
If you read academic papers on active learning, you might think active learning will give you a small saving in labels but for a huge amount of work. The papers are misleading though because they operate on academic datasets that tend to be balanced/clean. They almost always label one example at a time and they forget that not every data-point is equally easy to label. On more realistic problems with large class imbalances, noisy data and variable labeling costs, the benefits can be much bigger than the literature suggests. In some cases there can be a 10x reduction in labeling costs.
How to use Active Learning today
Many of the biggest hurdles to using active learning are just a question of having the right infrastructure. Just as tools like Keras and PyTorch dramatically reduced the pain of deriving gradients, new tools are emerging to make active learning much easier.

There are open source Python libraries such as
modAL that take away much of the
boilerplate. ModAL is built on top of scikit-learn and lets you combine
different models with any active learning strategy you like. It takes much of
the work out of implementing different uncertainty measures, is open source and
modular. The pros of ModAL are the range of methods it provides out of the box
and the fact that it's open source. The downside of libraries like modAL is they
don't include any annotation interfaces and still leave the work of hosting a
model and connecting it to annotation interfaces up to you.
That brings us to annotation interfaces:
Probably the most popular tool for individual data scientists is Prodigy. Prodigy is an annotation interface built by the makers of SpaCy and so can naturally be combined with their fantastic NLP library to use basic active learning. It's not open-source but you can download it as a pip wheel and install it locally. Whilst Prodigy is a good tool for individuals, it hasn't been designed to support teams of annotators and only implements the most basic forms of Active Learning. To make this work with teams, still requires you to host prodigy yourself and can be a lot of work to set up.
Labelbox provides interfaces for a variety of image annotations and has recently added support for text as well. Unlike Prodigy, Labelbox has been designed with teams of annotators in mind and has more tools for ensuring that your labels are correct. They don't have any native support for active learning or model training but do allow you to upload predictions from your model to the annotation interface via API. This means that if you have implemented an active learning acquisition function and are training a model, you can set up an active learning loop. Though the most of the work is left to you.
Humanloop provides an annotation interface that uses active learning out of the box
We built humanloop to solve many of the problems of existing tools. Our goal is to make deploying and maintaining natural language models faster and easier then ever before.
Humanloop provides an annotation interface for NLP tasks that lets you train a model as you annotate and uses active learning out of the box. We support teams of annotators and have incorporated state of the art techniques for active learning and quality assurance. This makes it possible to get real time feedback during training, even when using modern deep models. We also make it easy to deploy to an optimized model run-time immediately after training and to even update your data post deployment.
In Summary
Active learning:
- reduces how much data you need to label, dramatically reducing one of your biggest costs.
- gives you faster feedback on your model's performance.
- producer higher performing models.
At Humanloop we think that active learning should be a standard tool for data scientists. We also believe that good tools should make this easy.
There's more to Humanloop than active learning though. We're building infrastructure for AI models and human teams to work alongside each other so that anyone can quickly augment their team with AI assistance.
If you're interested in finding out more, send us a message or book a demo!
About the author

- 𝕏@RazRazcle










