Humanloop is the LLM Evals Platform for Enterprises
Humanloop enables product teams to build robust AI features with LLMs, using best-in-class tooling for Evaluation, Prompt Management, and Observability.
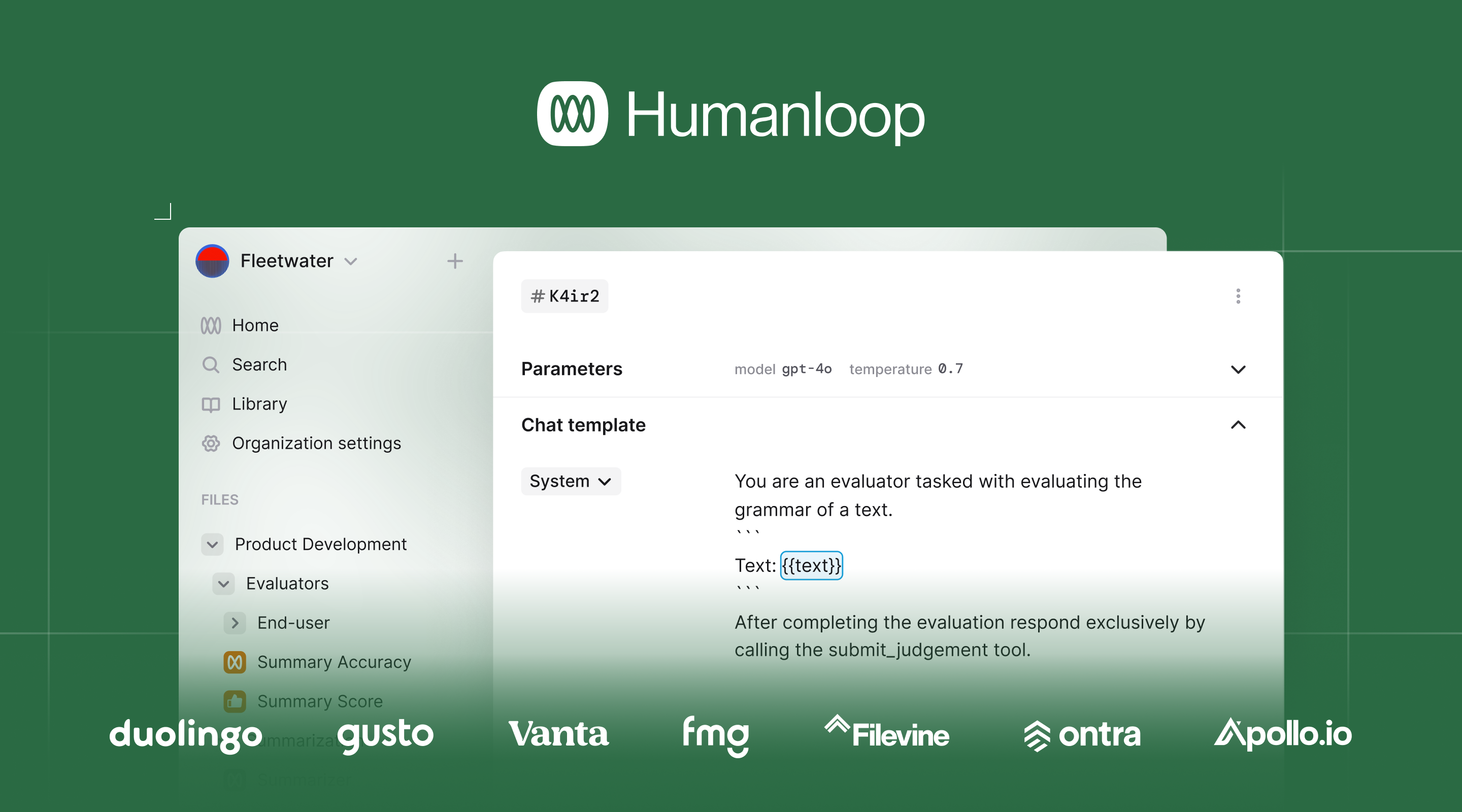
The most successful AI teams focus on two best practices:
Evals-driven development
They put evals at the heart of product development, continuously refining and enhancing AI features through feedback and iteration.
Collaborative development
They enable non-technical domain experts and PMs to work seamlessly with engineers on prompt engineering and evaluation.
Get started with Humanloop
Humanloop enables you to adopt these best practices. Our evals, prompt engineering and observability are designed to work together in a fast feedback loop. It works both UI-first and code-first so that the experience is great for developers and subject matter experts (SMEs).
Get started with evals in code
Get started with prompt engineering in our UI
Get started with the guides above or learn more about Humanloop’s key concepts and customer stories.