December
Improved TypeScript SDK Evals
December 18th, 2024
We’ve enhanced our TypeScript SDK with an evaluation utility, similar to our Python SDK.
The utility can run evaluations on either your runtime or Humanloop’s. To use your local runtime, you need to provide:
- A callable function that takes your inputs/ messages
- A Dataset of inputs/ messages to evaluate the function against
- A set of Evaluators to use to provide judgments on the outputs of your function
Here’s how our evals in code guide looks in the new TypeScript SDK:
SDK Decorators in Typescript [beta]
December 17th, 2024
We’re excited to announce the beta release of our TypeScript SDK, aligning with the Python logging utilities we introduced last month.
The new utilities help you integrate Humanloop with minimal changes to your existing code base.
Take this basic chat agent instrumented through Humanloop:
Using the new logging utilities, the SDK will automatically manage the Files and logging for you. Through them you can integrate Humanloop to your project with less changes to your existing codebase.
Calling a function wrapped in an utility will create a Log on Humanloop. Furthermore, the SDK will detect changes to the LLM hyperparameters and create a new version automatically.
The code below is equivalent to the previous example:
This release introduces three decorators:
-
flow(): Serves as the entry point for your AI features. Use it to call other decorated functions and trace your feature’s execution. -
prompt(): Monitors LLM client library calls to version your Prompt Files. Supports OpenAI, Anthropic, and Replicate clients. Changing the provider or hyperparameters creates a new version in Humanloop. -
tool(): Versions tools using their source code. Includes ajsonSchemadecorated to streamline function calling.
Function-calling AI Evaluators
December 15th, 2024
We’ve updated our AI Evaluators to use function calling by default, improving their reliability and performance. We’ve also updated the AI Evaluator Editor to support this change.
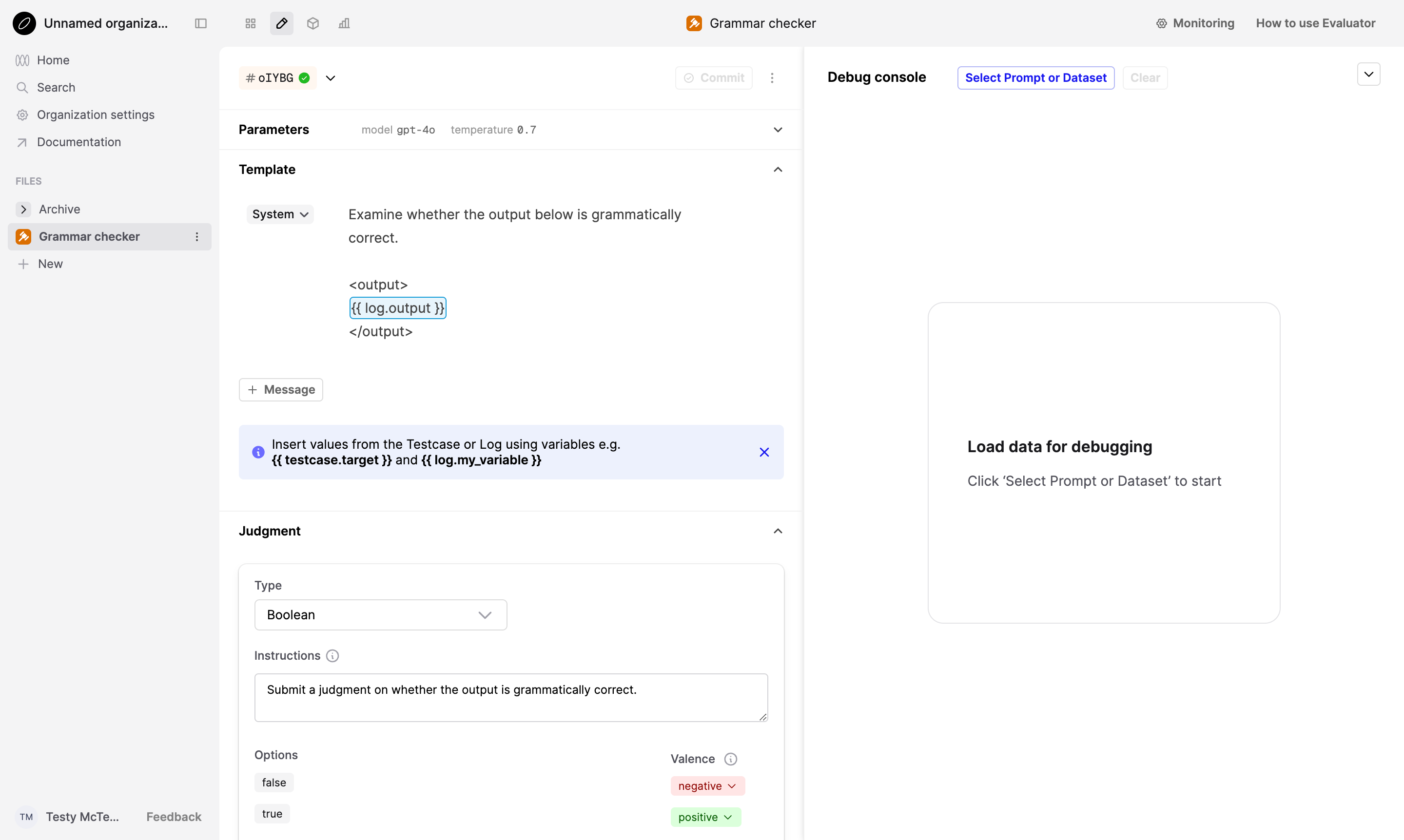
New AI Evaluators will now use function calling by default.
When you create an AI Evaluator in Humanloop, you will now create an AI Evaluator with a submit_judgment(judgment, reasoning) tool that takes judgment and reasoning as arguments.
When you run this Evaluator on a Log, Humanloop will force the model to call the tool. The model will then return an appropriate judgment alongside its reasoning.
You can customize the AI Evaluator in its Editor tab. Here, Humanloop displays a “Parameters” and a “Template” section, similar to the Prompt Editor,
allowing you to define the messages and parameters used to call the model.
In the “Judgment” section below those, you can customize the function descriptions and disable the reasoning argument.
To test the AI Evaluator, you can load Logs from a Prompt with the Select a Prompt or Dataset button in the Debug console panel. After Logs are loaded, click the Run button to run the AI Evaluator on the Logs. The resulting judgments will be shown beside the Logs. If reasoning is enabled, you can view the reasoning by hovering over the judgment or by clicking the Open in drawer button next to the judgment.
New models: Gemini 2.0 Flash, Llama 3.3 70B
December 12th, 2024
To support you in adopting the latest models, we’ve added support for more new models, including the latest experimental models for Gemini.
These include gemini-2.0-flash-exp with better performance than Gemini 1.5 Pro and tool use, and gemini-exp-1206, the latest experimental advanced model.
We’ve also added support for Llama 3.3 70B on Groq, Meta’s latest model with performance comparable to their largest Llama 3.1 405B model.
You can start using these models in your Prompts by going to the Editor and selecting the model from the dropdown. (To use the Gemini models, you need to have a Google API key saved in your Humanloop account settings.)
Drag and Drop in the Sidebar
December 9th, 2024
You can now drag and drop files into the sidebar to organize your Prompts, Evaluators, Datasets, and Flows into Directories.
With this much requested feature, you can easily reorganize your workspace hierarchy without having to use the ‘Move…’ modals.
This improvement makes it easier to maintain a clean and organized workspace. We recommend using a Directory per project to group together related files.
Logs with user-defined IDs
December 6th, 2024
We’ve added the ability to create Logs with your own unique ID, which you can then use to reference the Log when making API calls to Humanloop.
This is particularly useful for providing judgments on the Logs without requiring you to store Humanloop-generated IDs in your application.
Flow Trace in Review View
December 3rd, 2024
We’ve added the ability to see the full Flow trace directly in the Review view. This is useful to get the full context of what was called during the execution of a Flow.
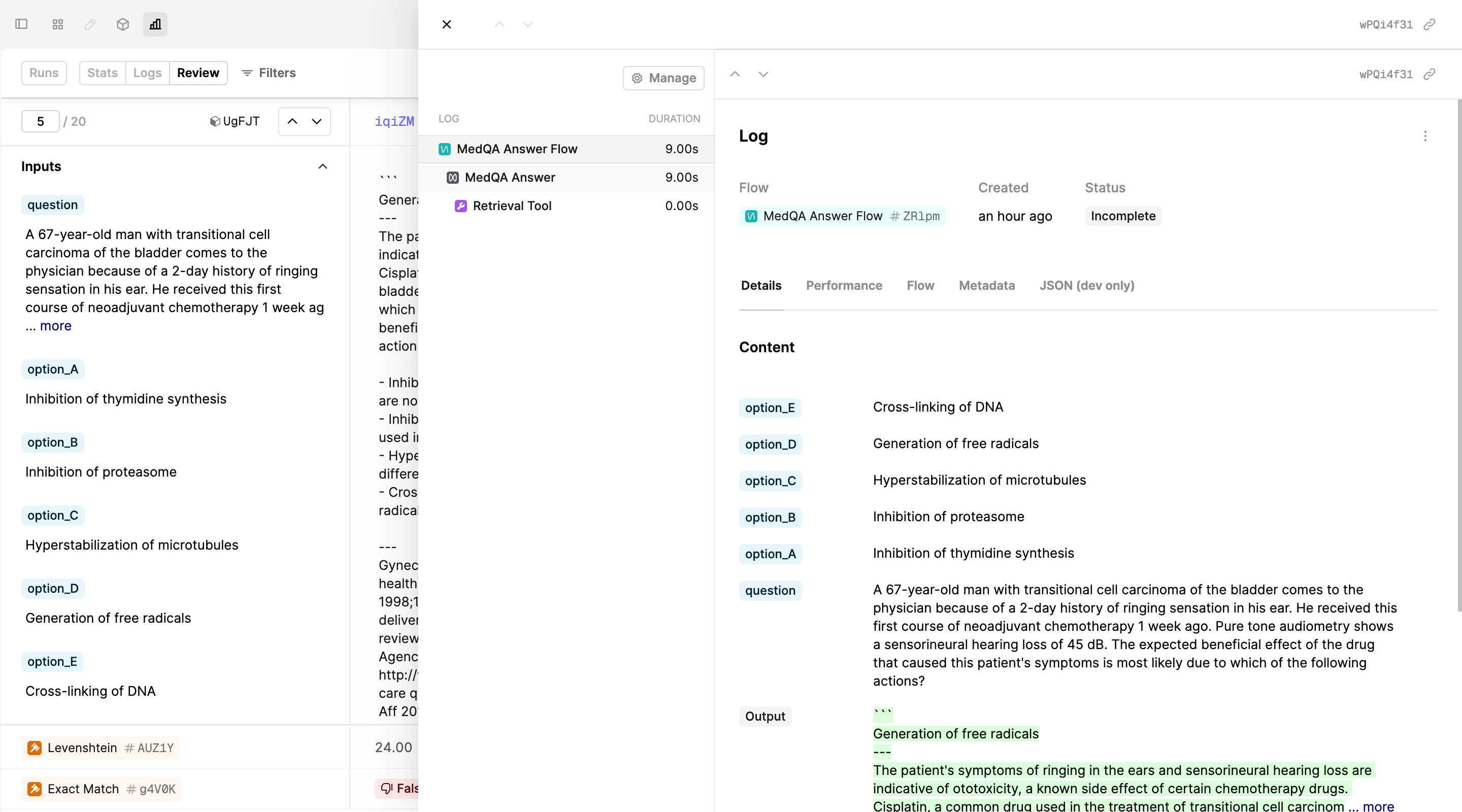
To open the Log drawer side panel, click on the Log ID above the Log output in the Review view.