January
o3-mini now available
January 31st, 2025
o3-mini is now available on Humanloop.
The OpenAI ‘o’ model series is trained with large-scale reinforcement learning to reason using chain of thought, providing advanced reasoning capabilities and improved safety and robustness. The o3-mini model brings state-of-the-art performance on key benchmarks, and excels in areas of STEM such as math and coding.
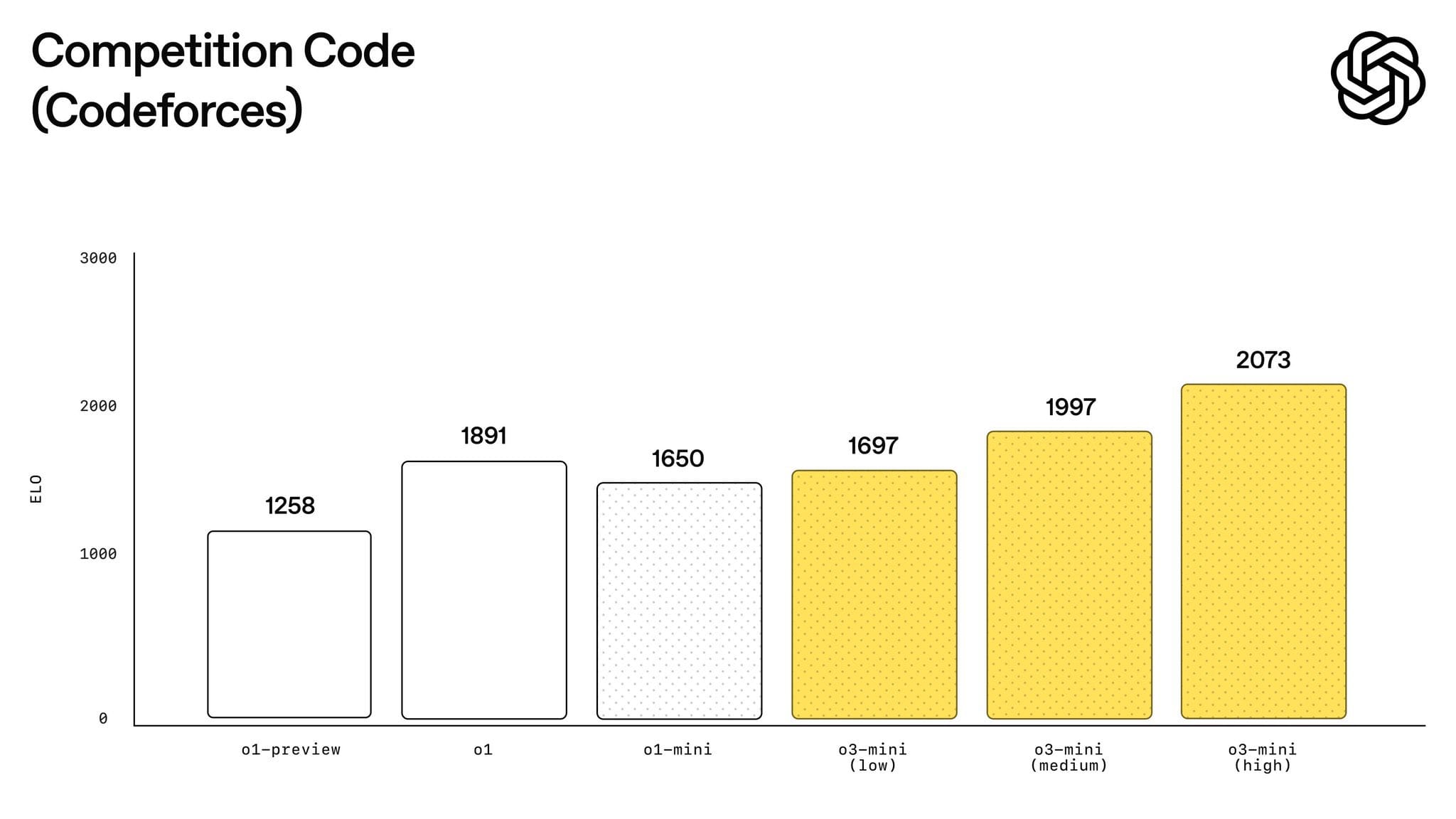
o3 has 200,000 token context length, with 100,000 output tokens and it can show superior performance to o1, but for 9x cheaper and 4x faster.
To try it, update your model parameter to o3-mini in the Prompt Editor.
Filter by Evaluator error in Review tab
January 31st, 2025
You can now filter Logs by whether an Evaluator errored in the Review tab of an Evaluation. This feature allows you to quickly retrieve Logs with errored judgments for debugging, or only consider judgments that did not error while reviewing.
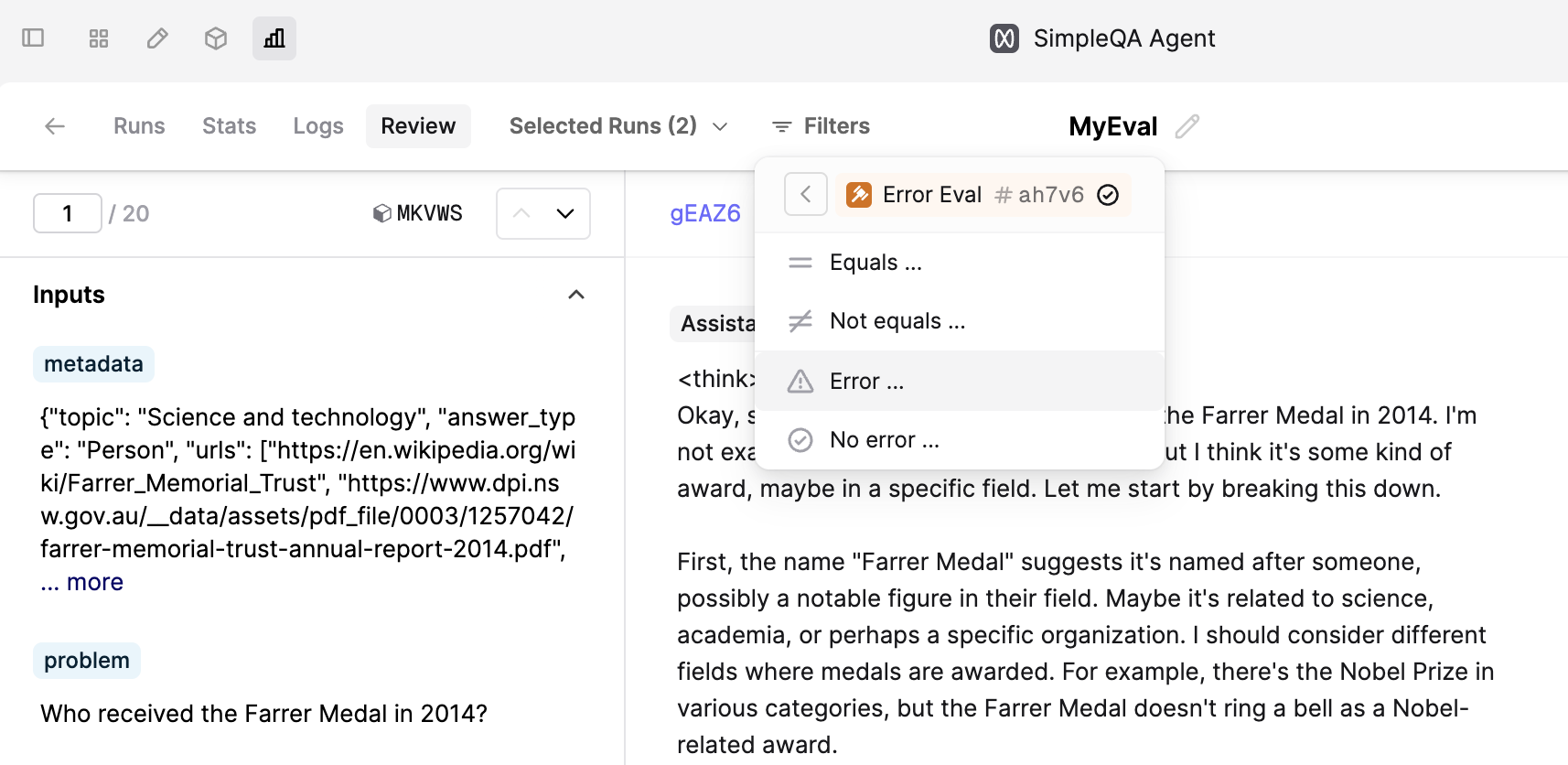
To filter Logs, click on the Filter button on the Review tab to set up your first filter.
DeepSeek Integration Available
January 29th, 2025
We’ve added support for the DeepSeek API to Humanloop — now you can use DeepSeek V3 and R1 (non-distilled) directly!
Add your API key to your organization’s API Keys page to get started.
Note on usage:
- DeepSeek’s API (status) has suffered from degraded performance over the past few days, so requests may fail or take longer than expected.
- DeepSeek R1 does not support temperature control, top p, presence penalty, or frequence penalty.
max_tokenswill default to 4K, and the API supports up to 64K context length. - This provider’s servers are located in China.
DeepSeek-R1-Distill-Llama-70B on Groq
January 27th, 2025
You can now access DeepSeek-R1-Distill-Llama-70B on Humanloop. Note that this model is a preview model on Groq and may be discontinued at short notice. As such, it should not be used in production environments.
To try it, update your model parameter to deepseek-r1-distill-11ama-70b.
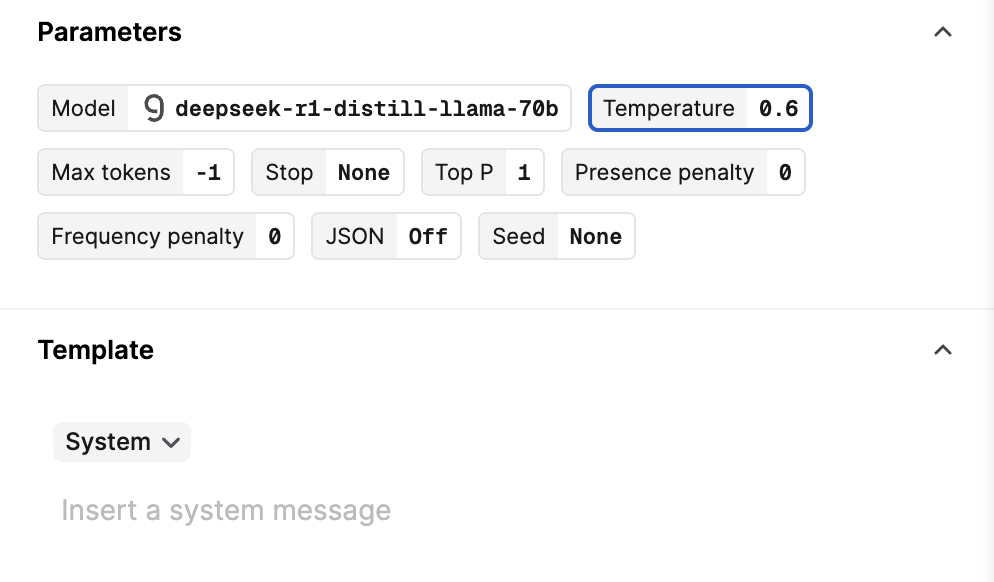
The DeepSeek team recommends using the R1 models in the following way:
- Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
- Avoid adding a system prompt; all instructions should be contained within the user prompt.
- For mathematical problems, it is advisable to include a directive in your prompt such as: “Please reason step by step, and put your final answer within \boxed.”
- When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Duplicate Datapoints
January 23rd, 2025
You can now duplicate Datapoints from the UI Editor. This is useful if creating lots of variations of an existing Datapoint.
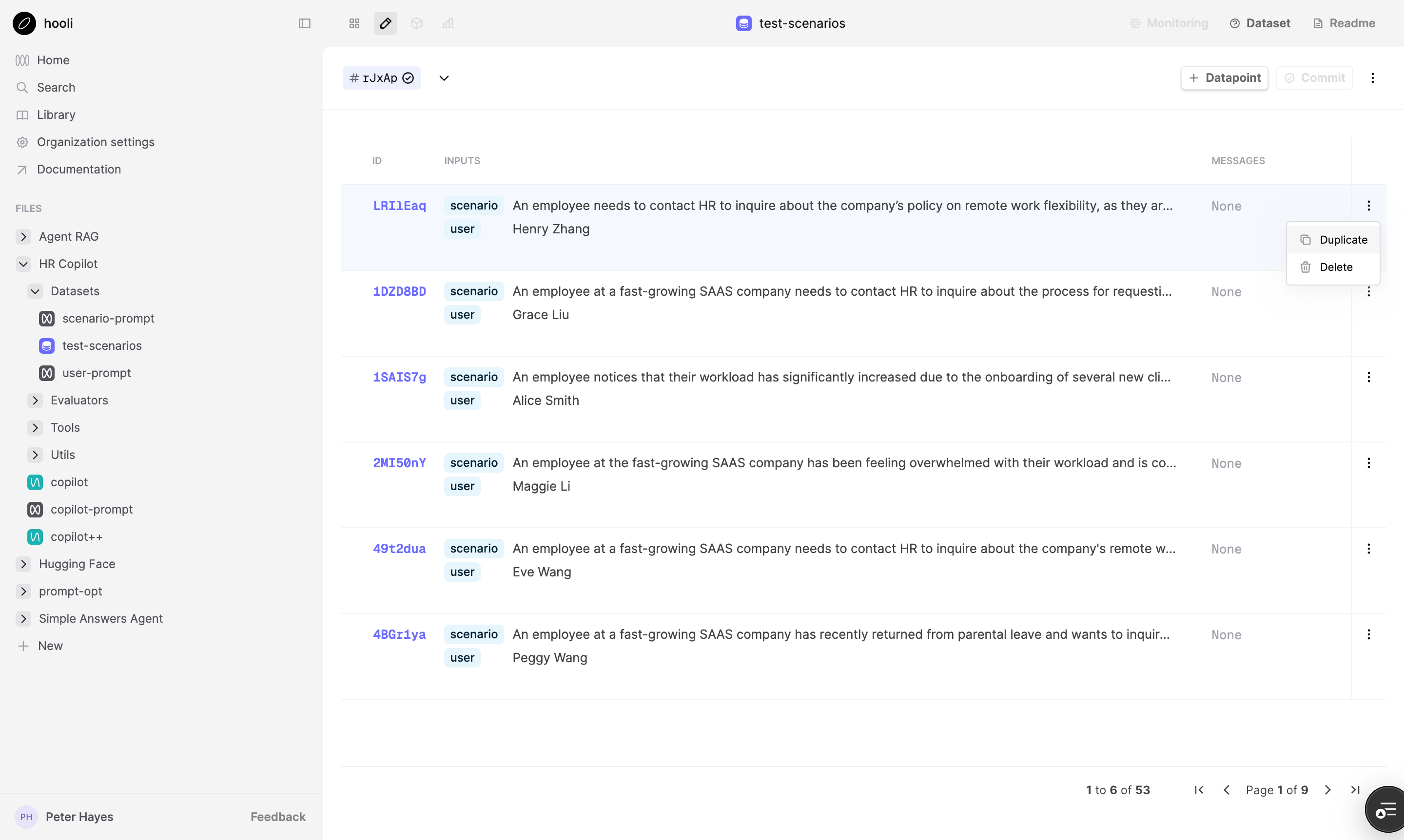
Alternatively, you can use the .csv upload feature to create multiple Datapoints at once.
Aggregate stats for Eval Runs
January 18th, 2025
We’ve added aggregate statistics to the Runs table to help you quickly compare performance across different Evaluators. You can view these statistics in the Runs tab of any Evaluation that contains Evaluators.
For boolean Evaluators, we show the percentage of true judgments. For number Evaluators, we display the average value.
For select and multi-select Evaluators, we display a bar chart showing the distribution of the judgments.
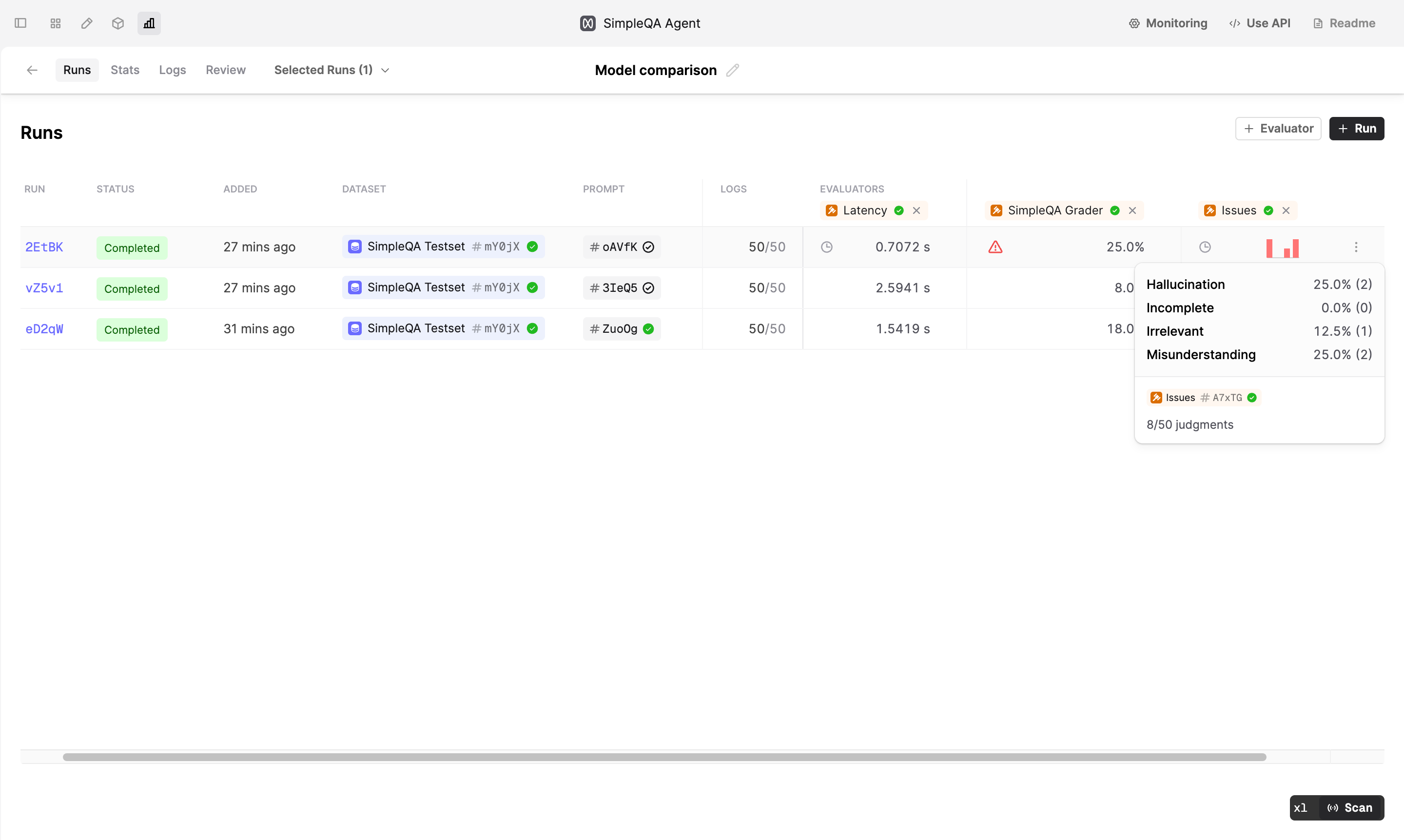
Additional icons indicate the status of the Run, relevant to the aggregate stat:
- A spinning icon indicates that not all Logs have judgments, and the Run is currently being executed. The displayed aggregate statistic may not be final.
- A clock icon shows that not all Logs have judgments, though the Run is not currently being executed
- A red warning icon indicates errors when running the Evaluator
Hover over these icons or aggregate statistics to view more details in the tooltip, such as the number of judgments and the number of errors (if any).
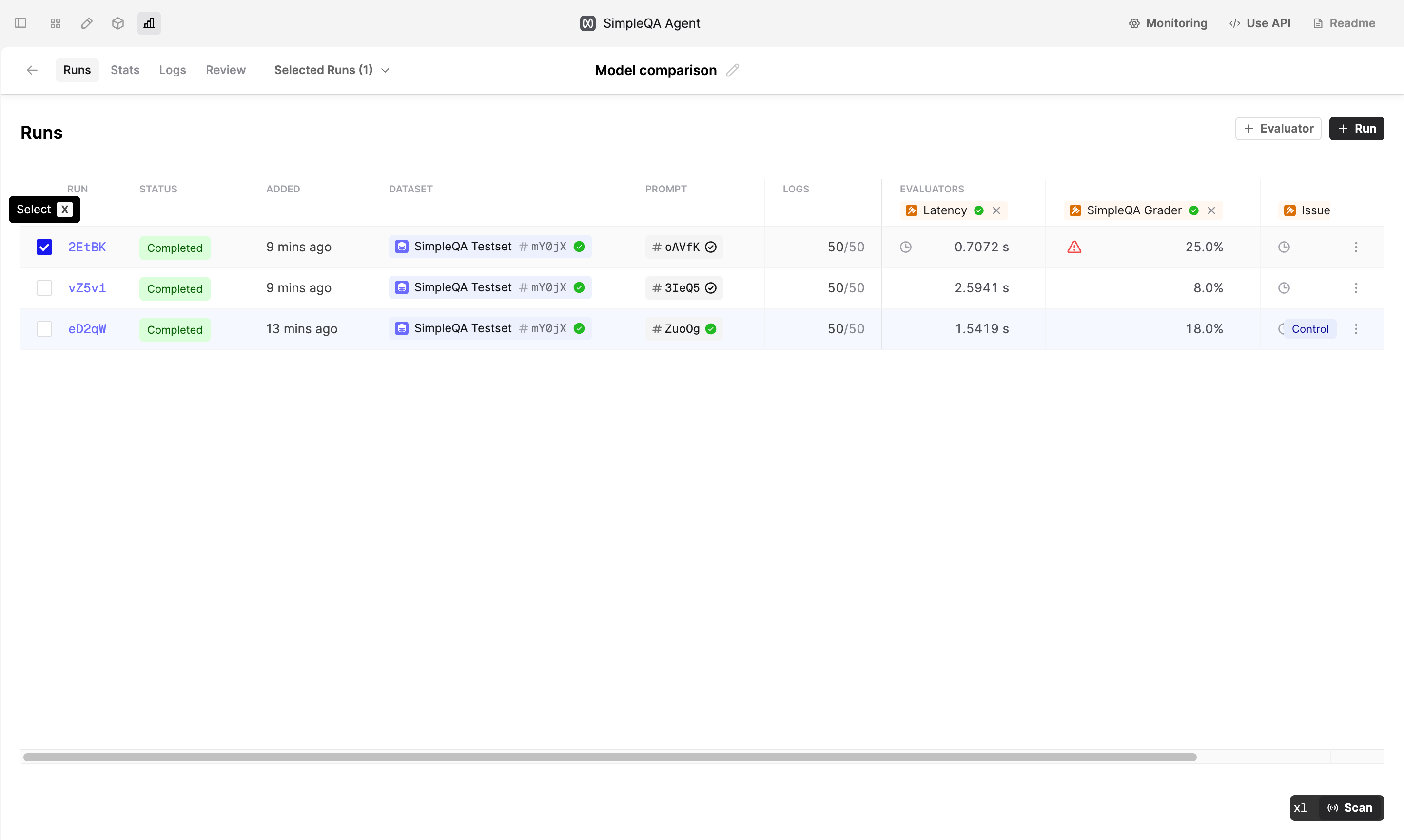
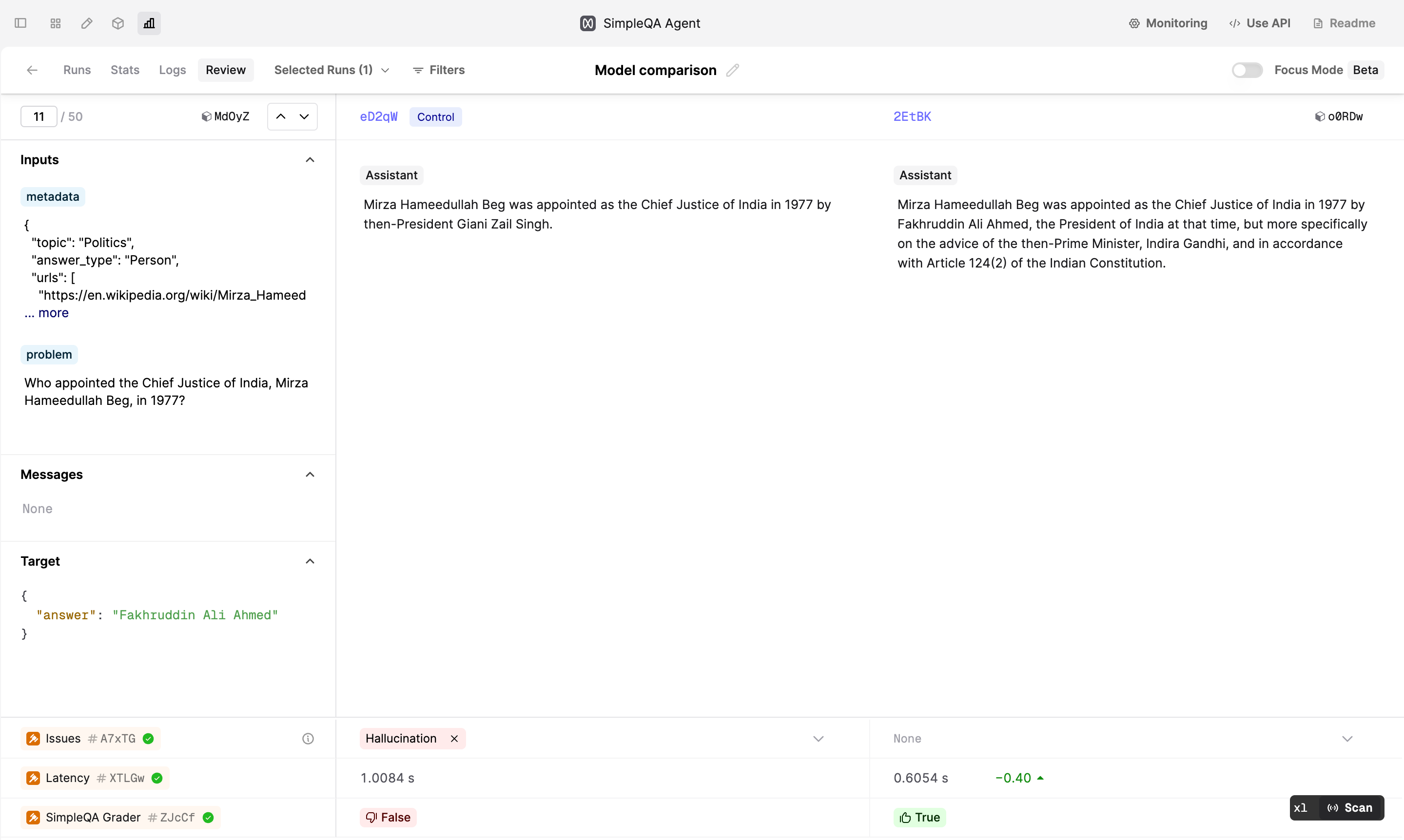
Filter Eval Runs
January 14th, 2025
You can now more easily compare your relevant Runs by selecting them in the Runs tab.
To filter to a subset of Runs, go to the Runs tab and select them by clicking the checkbox or by pressing x with your cursor on the row.
Then, go to the Stats or Review tab to see the comparison between the selected Runs. Your control Run will always be included in the comparison.
Filter by Judgement in Review tab
January 9th, 2025
You can now filter Logs by Evaluator judgments in the Review tab of an Evaluation. This feature allows you to quickly retrieve specific Logs, such as those marked as “Good” or “Bad” by a subject-matter expert, or those with latency below a certain threshold.
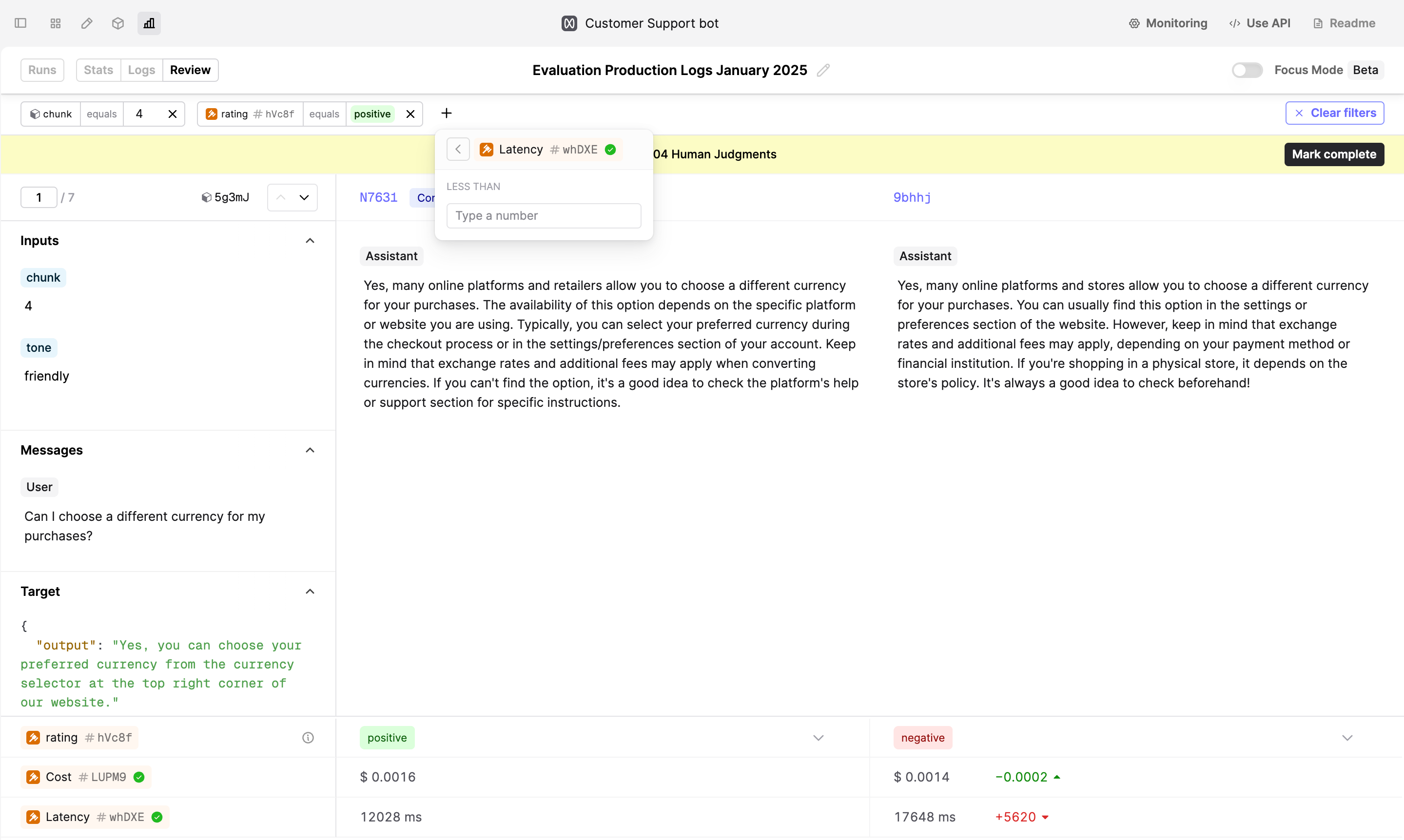
To filter Logs, click on the Filter button on the Review tab to set up your first filter.
Template Library
January 4th, 2025
We’ve introduced the first version of our Template Library, designed to help you get started with example projects on Humanloop.
This new feature allows you to browse and search for relevant templates using tags. You can then clone templates into your workspace to help overcome the cold-start problem.
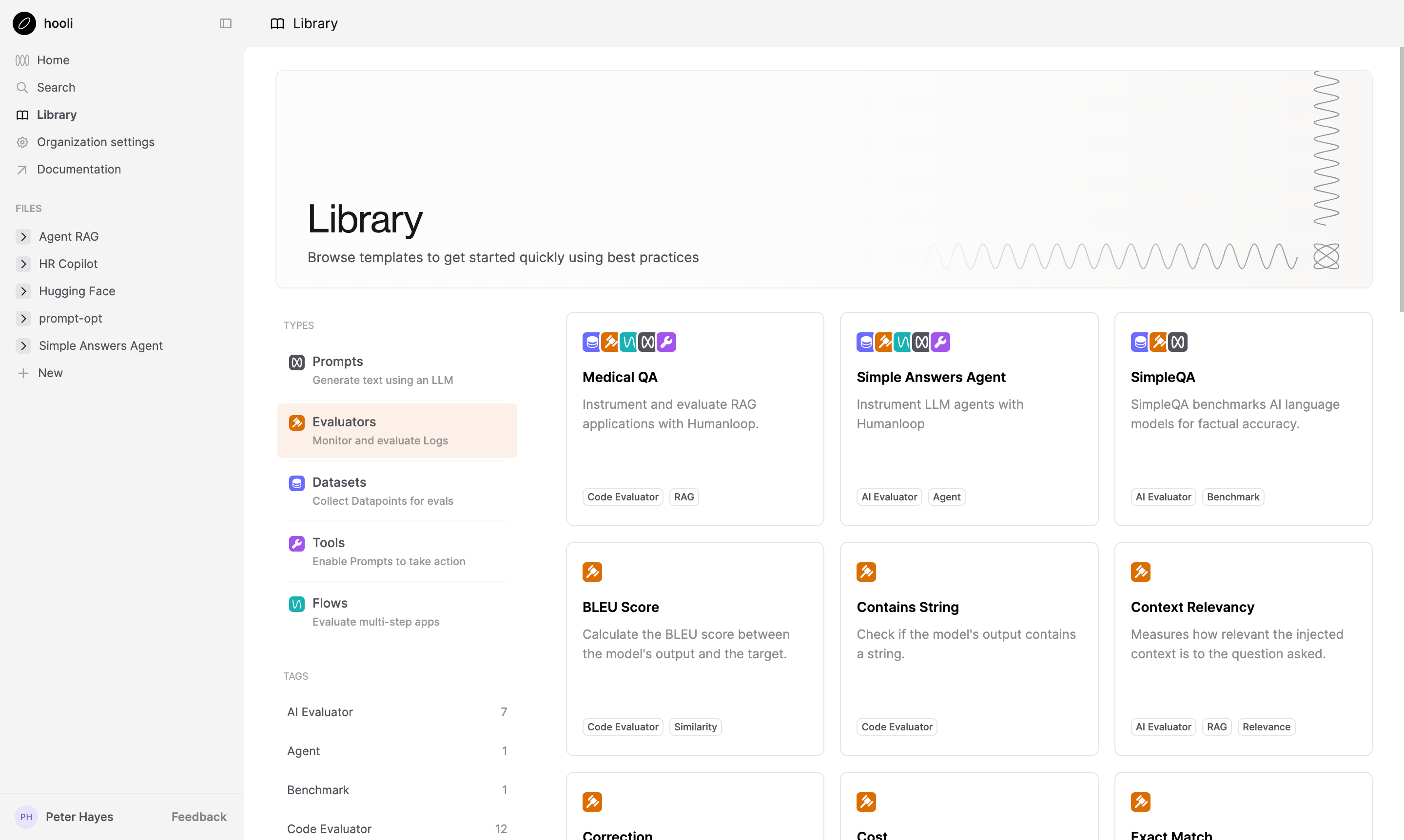
This first release focuses on providing useful Evaluator examples alongside a set of curated datasets from Hugging Face. In upcoming releases, we plan to expand the library with additional Agent and RAG templates for a wide range of use cases. Stay tuned for more updates!