OpenAI Fine-tuning: GPT-3.5-Turbo
OpenAI now allows fine-tuning for GPT-3.5 Turbo, the model behind ChatGPT.
This gives GPT-3.5 capabilities which can reach or exceed GPT-4 performance, increase model speed by up to 10x and reduce cost per token by over 70%.
Here’s a brief overview of fine-tuning, why it’s significant, how it works on OpenAI and how Humanloop can help you to fine-tune your own custom models.
What is fine-tuning?
In the context of large language models, fine-tuning refers to the process of taking a model that has been pre-trained on vast amounts of text data and subsequently training it further on a narrower, domain-specific, textual dataset.
This subsequent training aims to adapt the model's behaviour, making it more suitable for specific applications and tasks that require more specialised knowledge.
How does this differ to prompt engineering?
Currently prompt engineering is the most common method to get OpenAI’s models like GPT-4 to production. This differs from fine-tuning in a couple of key areas:
- Training
Fine-tuning provides additional training to the model which makes domain knowledge part of its intelligence.
Prompt engineering does not train the model but instead places relevant information within the input context, where it appears as new information to the model each time it’s called.
- Data
When fine-tuning, data quality is weighted heavily as once a model is fine-tuned it cannot be redacted to its original version.
Data provided in a prompt does not change the underlying model, allowing prompt engineering to be highly iterative. This is more ideal for experimentation.
- Operations
Fine-tuning has slightly more technical operations to it such as data cleaning, setting the number of epochs (training cycles) and testing on a validation set. These begin to crossover into the role of a machine learning engineer.
Prompt engineering is still quite novel and uses qualitative techniques which are more accessible and don't necessarily require knowledge of machine learning.
For those exploring the potential of prompt engineering to tailor GPT models to specific tasks without the technical overhead of fine-tuning, resources like Prompt Vibes AI can be valuable. It has example prompts and tools to help you generate more effective prompts, making the model's output more relevant, without the need for deep technical expertise in machine learning or model training.
Why is fine-tuning significant?
Fine-tuning GPT-3.5 allows for improvement over prompt engineering GPT-4 in a few key areas:
Price
Replacing a large model like GPT-4 with a smaller fine-tuned model such as GPT-3.5 allows for a reduction in cost per token as larger models tend to be more expensive.
Assuming a fine-tuned model can match the performance of GPT-4 for a task. Cost reduction could look as follows:
| Model | Input | Output |
|---|---|---|
| Fine-tuned GPT-3.5 | $0.012 / 1K Tokens | $0.016 / 1K Tokens |
| GPT-4 (8k context) | $0.03 / 1K Tokens | $0.06 / 1K Tokens |
If the average prompt (input) is 500 Tokens (375 words) and completion (output) is 1K Tokens (750 words):
Fine-tuned GPT-3.5 = 0.006 + 0.016 = $0.022 per API call.
Base GPT-4 (8k context) = 0.015 + 0.06 = $0.075 per API call.
Resulting in a 70.67% cost reduction.
Fine-tuning can also reduce the number of input tokens necessary, further driving down costs.
Speed
At current levels of processing time, base GPT-3.5 can already be up to 10 times faster than GPT-4. A fine-tuned GPT-3.5 could significantly improve latency in applications using GPT-4.
Capabilities
The combination of broad pre-training and task-specific fine-tuning can lead to better generalisation as the model becomes capable of striking a balance between general and domain knowledge.
It’s important to note however that the benefits of fine-tuning vary significantly depending on the model’s task.
Good use cases for fine-tuning a model:
Generally good candidates for fine-tuning are those which can be comprehensively explained to the model using a sample set of user inputs and desirable model outputs.
For example, fine-tuning a model with sample of successful outbound sales emails will allow the model to understand the tone, structure and other elements which go into delivering quality outreach, creating a reliable business development assistant.
However, fine-tuning a model on a sample of tax related Q&As will not adequately train the model on the broad, nuanced scope of tax legislation, making it an unreliable tax assistant.
Some other good fine-tuning use cases might be:
- Setting a consistent tone:
- Brand voice & style used in marketing copy.
- Guiding creativity:
- Script writer tailored towards classic films.
- Formatting output structure:
- JSON used to trigger an API.
- Enterprise Assistant:
- Customer service agent designed to handle a fixed range of queries.
- Guard railing:
- Establishing appropriate output for a storyteller.
Data for fine-tuning
To fine-tune GPT-3.5, it’s recommended that you provide a dataset of at least 10 prompt/completion examples. Performance is generally best when provided with 50-100 examples.
Training datapoints should be formatted as follows:
{
"messages": [
{ "role": "system", "content": "Message" },
{ "role": "user", "content": "Prompt" },
{ "role": "assistant", "content": "Completion" }
]
}
It’s important that the training data used is a close as possible to the desired behaviour. Therefore it’s advisable to analyse a dataset to ensure it doesn’t contain any anomalies as these will derail the model’s performance.
How Humanloop helps
Humanloop makes it easy to collect examples for fine-tuning by logging all of your model data along with feedback and evaluation. This way you can filter for preferable output and fine-tune the model based on this, within a few clicks.
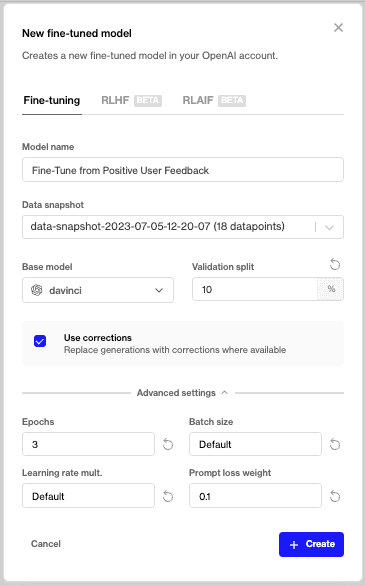
A solution for GPT-3.5 fine-tuning will be released on Humanloop soon, message us on chat if you’d like early access.
Summary
OpenAI’s release of fine-tuning for GPT-3.5 allows for enhanced performance speed and capabilities while reducing costs.
If a fine-tuned version of GPT-3.5 can replace that of GPT-4, it’s possible to reduce costs by over 70% while lowering latency significantly.
The benefits of fine-tuning are case specific. Good candidates are ones which can be conveyed to the model in a dataset of Q&A examples, such as tone and completion format. OpenAI recommends 50-100 of such examples.
About the author

- 𝕏@conorkellyai










