How good is GPT-3 in practice?
When OpenAI first released GPT-3, their 175B parameter language model, it dominated tech-twitter for weeks with impressive demos and genuine disbelief at its performance. Last week OpenAI quietly released a new API endpoint that makes it possible to fine-tune GPT-3 on your own data. This raises the question: if you're building a language AI application today, should you be using GPT-3?
The full answer is complicated and will require some explanation. The short answer is that GPT-3 is almost never the best option for practical problems other than text generation. GPT-3 is a remarkable milestone in our quest to build general purpose language technologies and much of the excitement is warranted. The scaling performance of GPT-3 almost guarantees more powerful general purpose models even without significant algorithmic innovation. This makes it likely that huge pre-trained language models will become an integral part of AI applications in the near future.
What exactly is a language model and why is GPT-3 important?
A language model is a statistical model on sequences of words. Language models take as input a sequence of words and return how probable that sequence would be in ordinary language. They can also be used to sample new sentences from the probability distribution over words. Machine learning researchers have been interested in language modeling for a long time, because it has practical applications like predictive text or improving machine translation, but also because it's a task that can capture useful aspects of language without needing any manually annotated data.
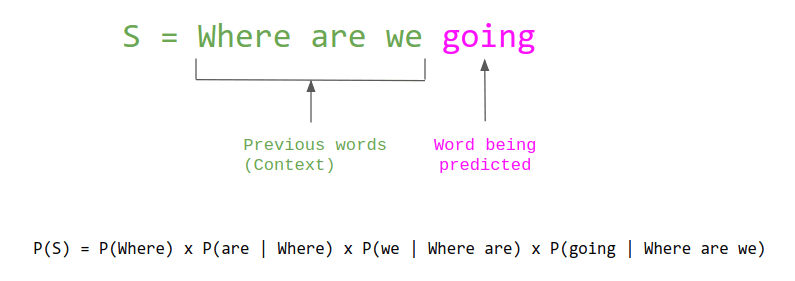
In 2018 there was a remarkable series of new papers (e.g ULMFiT, GPT-1, BERT) on language model pretraining. These papers showed for the first-time that you could practically train a language model on a large corpus of unlabeled data and then quickly specialize or "fine-tune" that model to many different tasks such as classification or question answering and get state-of-the-art performance. Because language model pre-training only requires unannotated text, this is unlocking many applications where previously we needed masses of human labels.
Before language model pre-training, you needed huge amounts of new annotated data for every single task.
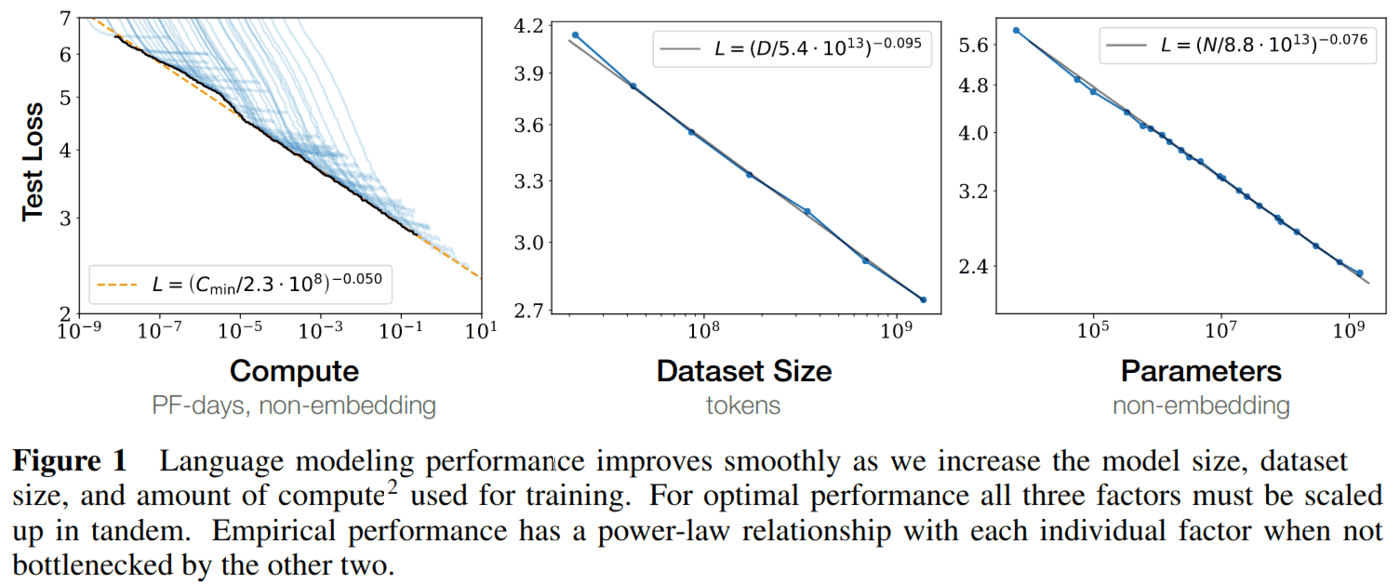
In 2018 OpenAI began exploring the limits of how good these pre-trained language models could be made if the size of the model (measured in number of parameters) and the size of the unlabeled dataset were simply increased enormously. They discovered a simple scaling law between size and performance that covers several orders of magnitude and motivated by this, trained the largest neural language model ever, GTP-3. Prior to GPT-3 the most performant pre-trained language models had 5 Billion parameters, GPT-3 is a 175 Billion parameter model and so represents almost two orders of magnitude in scale increase.
The most remarkable thing about GPT-3 is how well the model can be made to perform without any new training and with only tiny amounts of example data. Ordinarily, model "fine-tuning" works by collecting labeled data specific to a task and then adjusting the parameters of the model for that task. Amazingly, GPT-3 is able to do "few-shot" learning: given only a handful of examples and with no updates to the model's parameters at all GPT-3 can produce quite good performance on many tasks.
GPT-3 is able to adapt to new tasks without any task specific training.
For most traditional NLP tasks the remarkable thing about GPT-3 isn't its final performance which is usually significantly less good than a model trained specifically for that system. The remarkable thing is that GPT-3 is able to solve these tasks at all, without any parameter updates.
The performance of GPT-3 on specific tasks still lags specialized models but it's surprising that it can work at all without task specific training.
The one area where GPT-3 is very successful is in text generation or sentence completion (which is exactly what it was trained to do). GPT-3 can produce humor, solve simple programming puzzles, imitate famous writers, generate dialogues or even produce ad copy. All tasks that previous models weren't able to do well.
The creative writing tasks are poorly measured by quantitative metrics and this may explain some of the gap in excitement between academic researchers and members of the general public who have played with the OpenAI API. The numerical scores on standard benchmarks don't faithfully capture what's possible with GPT-3 because much of the new improvement is in the subjective quality of the text it can generate.
GPT-3 isn't practical for most applications yet
For most applications other than text generation (sentiment analysis, classification, summarization etc) the performance of GPT-3 without fine-tuning is significantly worse than a model trained specifically for that task. In the "few-shot" learning mode, GPT-3 is restricted to less than 2000 characters of context and tends to produce unreliable results.
Anecdotally, the model can be sensitive to how you input the training examples and best practice is poorly understood. The way GPT-3 is used for few-shot learning is to provide a prompt: a small number of data point and label pairs alongside a description of the task that are provided to the model as a string. You then ask the model to predict what sentence would come next. For example to train a sentiment classifier the initial training prompt might look like this:
The following is a sentiment classifier
I enjoyed the movie, the acting was great. # positive
I hated the movie. # negative
I would never watch something like that again. # negative
The story was truly magnificent. # positive
To test the model performance you then enter the sentence you want classified and ask it to predict what characters should come next. My experience playing with the model has been that the choice of examples affects the quality of prediction in difficult to anticipate ways. Sometimes the model doesn't make a prediction at all and can instead degenerate into repeating existing text.
For most of these tasks you would almost certainly be better off fine-tuning an existing model. Until recently that meant you couldn't consider GPT-3 for your task at all because OpenAI only let you use it without fine-tuning. Open-AI has made it possible to fine-tune now but only on smaller versions of the full model.
There is little information about the performance of GPT-3 after fine-tuning and OpenAI don't specify the exact details of the models you can interact with. We can make some educated guesses though. In their original paper, the GPT-3 authors trained a series of models with 2.6B, 6.7B, 13B and 175B parameters. Since OpenAI don’t let you fine tune the largest model, we can assume that the best model you can fine-tune with GPT-3 is the 13B parameter model. Looking at other large scale studies of language model fine-tuning such as Google's T5 it seems unlikely that using OpenAI's API will give significant performance improvements over other alternatives at these model sizes.
With even a few hundred data points, you can fine-tune models like BERT to impressive levels of performance and libraries like Hugging Face or SpaCy make the fine-tuning itself easy. At least for now, it also seems to be more convenient to fine-tune using SpaCy or Hugging Face. If you already have a well specified problem, good labeled data and are willing to use a third party API then it's hard to imagine that the OpenAI API gives much benefit over Hugging Face's inference API.
The main use case where you might genuinely want to use the OpenAI API is if your task requires the generation of text. For example if you'd like to automatically generate ad copy or summarize long documents then the largest GPT-3 model is still likely to produce excellent results. Care must be taken even here though because it's been documented that the model may have memorized offensive or sexist language from the training data. It's also possible for the model to leak private information by producing text it has seen in training that contains names, phone numbers or other PII.
The model isn't usually the problem anyway
As we've written about recently, our experience at Humanloop has been that in most real world AI applications the choice of model is rarely the problem. By the time a team has gotten to the point that a task is well defined and they have high quality data, most of the work has already been done. The models are largely becoming commoditized so the ability to curate high quality datasets, collaborate across teams and keep data/models up-to-date is where most of the challenge lies.
The OpenAI API still takes a model-centric view to building AI applications, where the data is viewed as static and where it's assumed a model will be trained once and then used many times.
We believe that there is a better approach. The right tools for building AI will be data-centric and model backed, will make it easy for domain experts to contribute knowledge and will recognize that models need continuous retraining.
What might we expect from GPT-4?
Ultimately OpenAI's mission is not to produce the best AI products but rather "to ensure that artificial general intelligence benefits all of humanity". GPT-3 is a scientific milestone on their attempted path to building safe general purpose AI. Their research agenda suggests that they subscribe to the "scaling hypothesis" which supposes that we largely have all of the pieces needed to produce very powerful AI systems if we simply continue scaling in both data and compute. It's rumored that they are working on a new version of GPT that may be 100 or even 1000 times larger in size. If they do produce such a model what could we expect from it's performance?
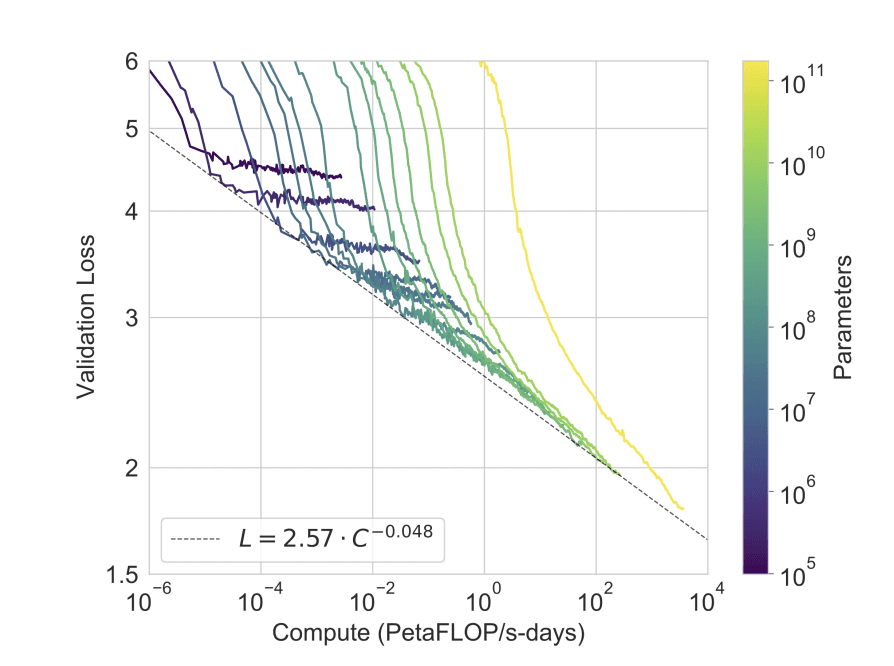
If the scaling law that seems to govern the performance of language models continues to hold then a 100x increase in model size will likely result in a near halving of the testing score of GPT-3. It's difficult to know exactly how such a change in the loss function would translate into real world performance but we can speculate about the kinds of things that GPT-4 would have to learn to achieve such a low loss value.
GPT-3 improves its testing score by getting increasingly good at predicting the rest of a randomly selected sentence. Early in training it can make good progress simply by learning basic things like how to assemble characters into words and grammar. As the model gets better it needs to encode more information about the world to get marginal gains. For example, to reliably complete sentences like: "The trophy won't fit in that bag because the bag is too ...", a model needs to have captured the common sense notion that larger objects can't fit inside smaller ones.
Since GPT-3 already does well on common sense reasoning benchmarks and has captured basic language syntax such a large improvement in its training loss would likely mean a significant improvement in its reasoning ability and knowledge about the world.
We can also try to draw some conclusions about how good the few-shot performance of a 100x bigger GPT model might be by looking at the scaling pattern of performance from the original OpenAI paper.
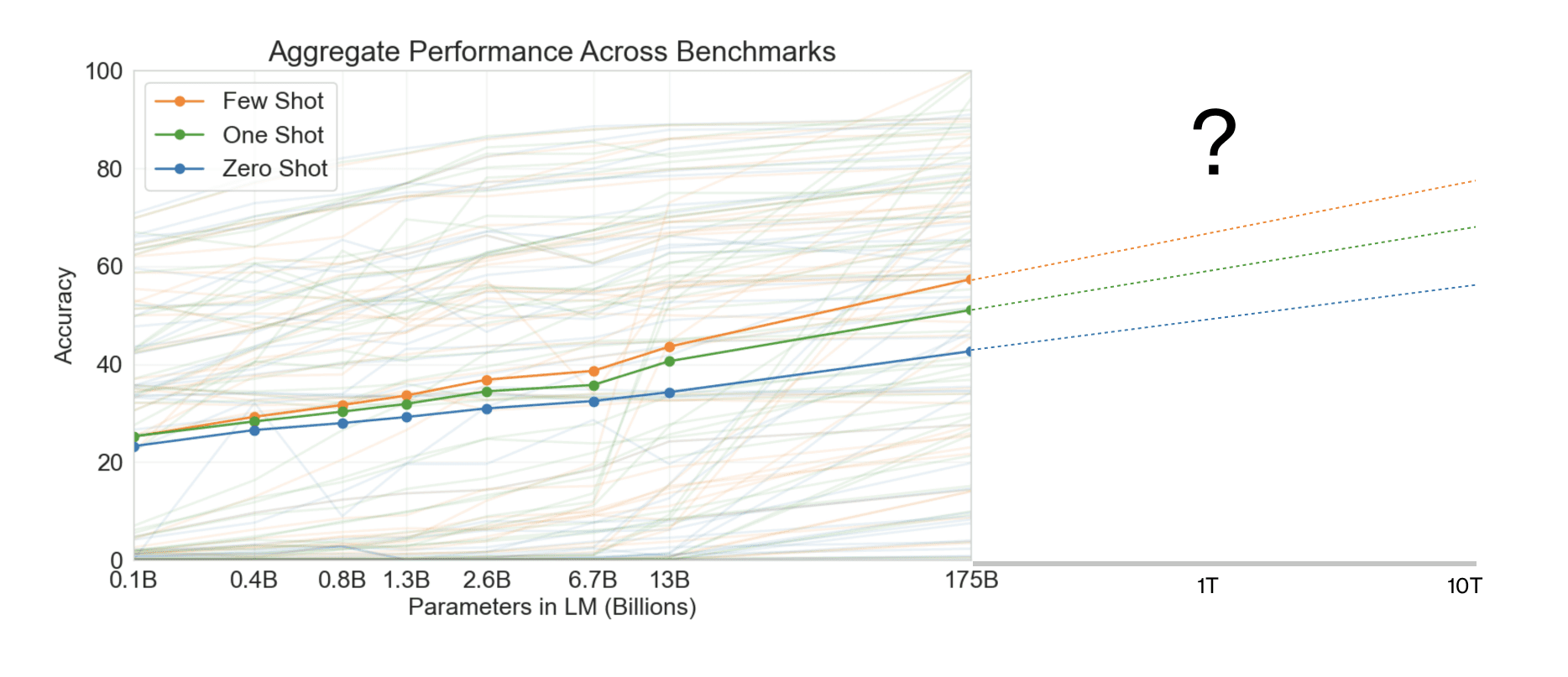
Looking at this graph and naively extrapolating would lead one to conclude that the average few-shot accuracy of the next GPT model could be 10-20% better than the model today and may be competitive with fine-tuning.
If the scaling does continue, it’s hard to imagine a future in which extremely large pre-trained language models don’t eventually become a standard part of most AI applications.
About the author

- 𝕏@RazRazcle










