Prompt Caching
Prompt Caching: Reducing latency and cost over long prompts
How often do you send a query to an AI agent or chatbot and find that the response time is too slow? Or find that there’s a trade-off between the speed and accuracy of responses? This has long been an issue for large language model (LLM) applications - as models get larger, they require more compute to generate completions, resulting in longer response times and higher costs.
Prompt caching can solve this by intelligently storing and reusing previous responses to identical prompts, allowing AI engineers to dramatically reduce the processing required for repetitive tasks and resulting in faster, more efficient AI applications.
Model providers like OpenAI and Anthropic use Prompt Caching to reduce costs by up to 90% and latency by 80%, primarily over large-context prompts.
This guide will help you understand how prompt caching works, the difference between prompt caching using OpenAI and Anthropic, its benefits and challenges, and how it can be applied in AI applications.
What is Prompt Caching?
Model prompts often contain repetitive content, like system prompts and common instructions. Prompt caching is an optimization technique used in large language model (LLM) applications to temporarily store this frequently used context between API calls to the model providers.
This significantly reduces cost and latency, making it more practical to provide the LLM with additional background knowledge and example outputs.
How Does Prompt Caching Work?
The goal of prompt caching is to improve efficiency and performance by storing and reusing the LLM's responses to specific prompts, reducing the need for the model to process identical prompts multiple times.
This is achieved by assessing the similarity between inputs, storing context that appears most frequently in cache and updating the cache management as the pattern of inputs changes.
Anthropic, OpenAI and other model providers/frameworks have varying methods for prompt caching which differ in terms of requirement and limitations. If you’re using either Anthropic or OpenAI, this guide will help you ensure that you still capture the benefits of both.
Prompt Caching with OpenAI
OpenAI states that prompt caching can reduce latency by up to 80% and cost by 50% for long prompts using its gpt-4o and o1 models.
Prompt caching on OpenAI is enabled automatically for prompts that are 1024 tokens or longer. When you make an API request, it is routed to servers that recently processed the same prompt, and the following steps occur:
- Cache Lookup: The system checks if the initial portion (prefix) of your prompt is stored in the cache.
- Cache Hit: If a matching prefix is found, the system uses the cached result. This significantly decreases latency and reduces costs.
- Cache Miss: If no matching prefix is found, the system processes your full prompt. After processing, the prefix of your prompt is cached for future requests.
Cached prefixes generally remain active for 5 to 10 minutes of inactivity. However, during off-peak periods, caches may persist for up to one hour.

Prompt caching with OpenAI is enabled on the following models:
- gpt-4o
- gpt-4o-mini
- o1-preview
- o1-mini
Pricing: Prompt caching is free to use with OpenAI and is done automatically with the gpt-4o and o1 models. Cached input tokens represent a 50% reduction over uncached input tokens Depending on the size and frequency of your cache hits, this can result in significant savings.
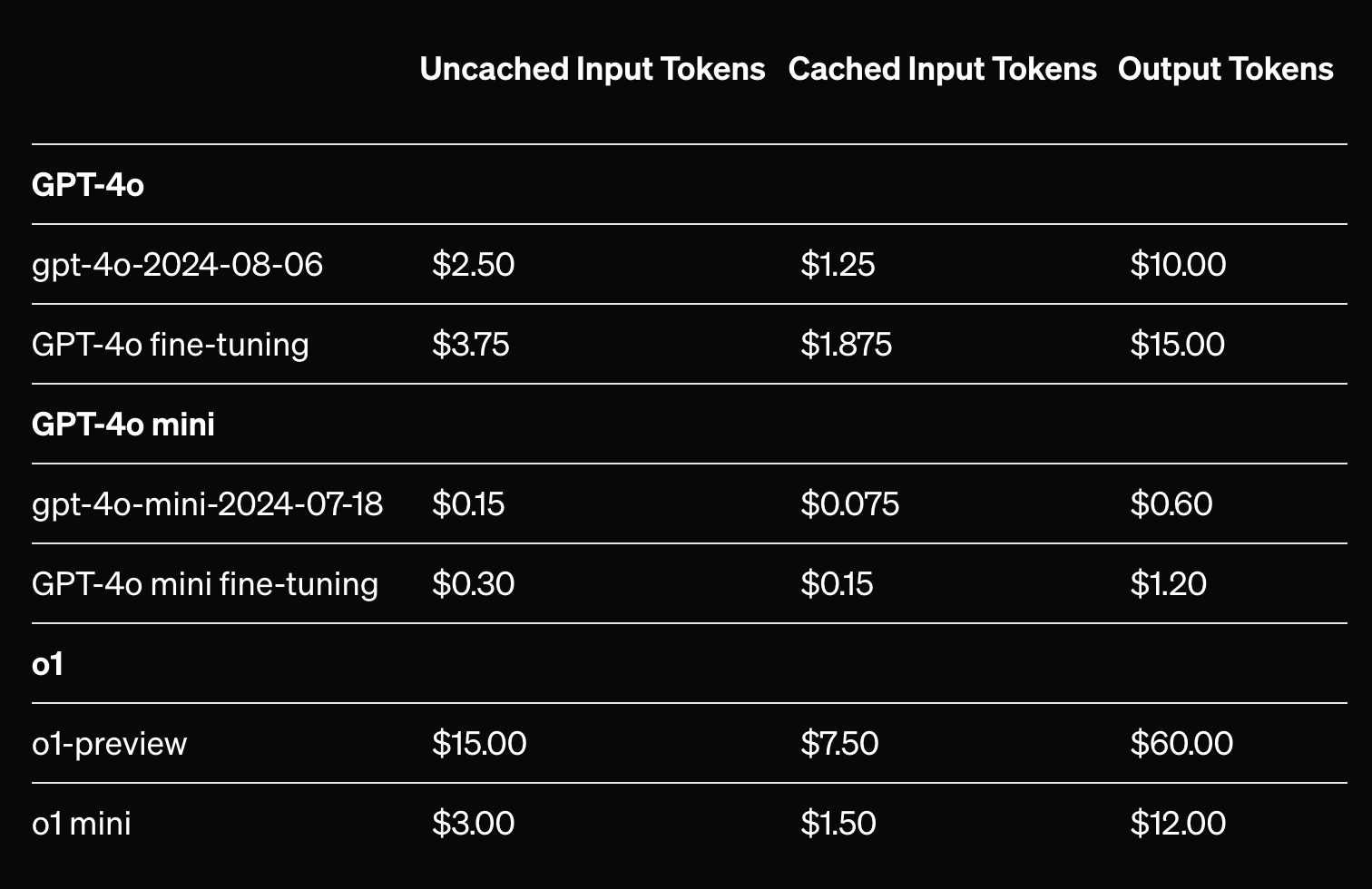
What can be cached using OpenAI?
- Messages: The complete messages array, encompassing system, user, and assistant interactions.
- Images: Images included in user messages, either as links or as
base64-encoded data. Multiple images can be sent. Ensure the
detailparameter is set identically, as it impacts image tokenization. - Tool use: Both the messages array and the list of available tools can be cached, contributing to the minimum 1024 token requirement.
- Structured outputs: The structured output schema serves as a prefix to the system message and can also be cached.
How to Structure your Prompt for OpenAI Prompt Caching
The cache operates based on exact prefix matches within a prompt, meaning that static content like instructions and few-shot prompt examples will be cached, but any inputs that vary by a single character will not.
OpenAI advises putting static content at the beginning and variable content at the end of your prompt to realize prompt caching’s full benefits.
For example:
[
{
"role": "system",
"content": "You are a professional translator fluent in English and French. Translate the following English text into French, maintaining the original meaning and tone."
},
{
"role": "user",
"content": "[VARIABLE CONTENT]"
}
]
In this example, the system content will be cached whereas the user input is expected to change on each request and won’t be cached.
Requirements and Limitations
Caching is available for prompts containing 1024 tokens or more, with cache hits occurring in increments of 128 tokens.
All requests, including those with fewer than 1024 tokens, display the
usage.prompt_tokens_details chat completions object indicating how many of the
prompt tokens were a cache hit.
Best Practices for OpenAI Prompt Caching
-
Structure prompts so that static or repeated content is at the beginning and dynamic content is at the end. For example, if you’re doing RAG, place retrieved context at the end of the prompt and instructions above.
-
Monitor metrics such as cache hit rates, latency, and the percentage of tokens cached to optimize your prompt and caching strategy.
-
To increase cache hits, use longer prompts and make API requests during off-peak hours, as cache evictions (the removal of prompts from cache management) occur more frequently during peak times.
-
Prompts that haven't been used recently are automatically removed from the cache. Try to avoid changing the prompt prefix where possible to minimize evictions.
Prompt Caching with Anthropic
Anthropic’s approach to prompt caching is largely similar to OpenAI's, but there are some distinctive differences which will affect how you make use of it. Anthropic temporarily stores a prefix (specific point) from a previously used prompt. Then, when future requests are sent to the model:
- The system checks if the prompt prefix is already cached from a recent query.
- If found, it uses the cached version, reducing processing time and costs.
- If not found, it processes the full prompt and caches the prefix for future use.
However, rather than automatically caching prompts, Anthropic defines up to 4
cache breakpoints which allow users to have finer control over which sections of
the prompt are cached. This can be adjusted using the cache_control parameter.
Anthropic caches the prefix for 5 minutes and refreshes it each time the cached content is used.
Prompt Caching is currently supported on the Claude model series:
- Claude 3.5 Sonnet
- Claude 3 Haiku
- Claude 3 Opus
Pricing: Anthropic's caching has a specific pricing structure where writing to the cache is more expensive than base input tokens (+25% cost), but reading from the cache is significantly cheaper (90% cost reduction).
This is different to OpenAI, where cache writes are free, but the discount on cache reads is only 50%.
If most of your API requests involve static content, Anthropic’s 90% discount on input tokens will likely be more cost effective. However if your content frequently changes, Anthropic’s cache write fees may actually cost you more. In this case, OpenAI will be cheaper as they don't charge for cache writes.
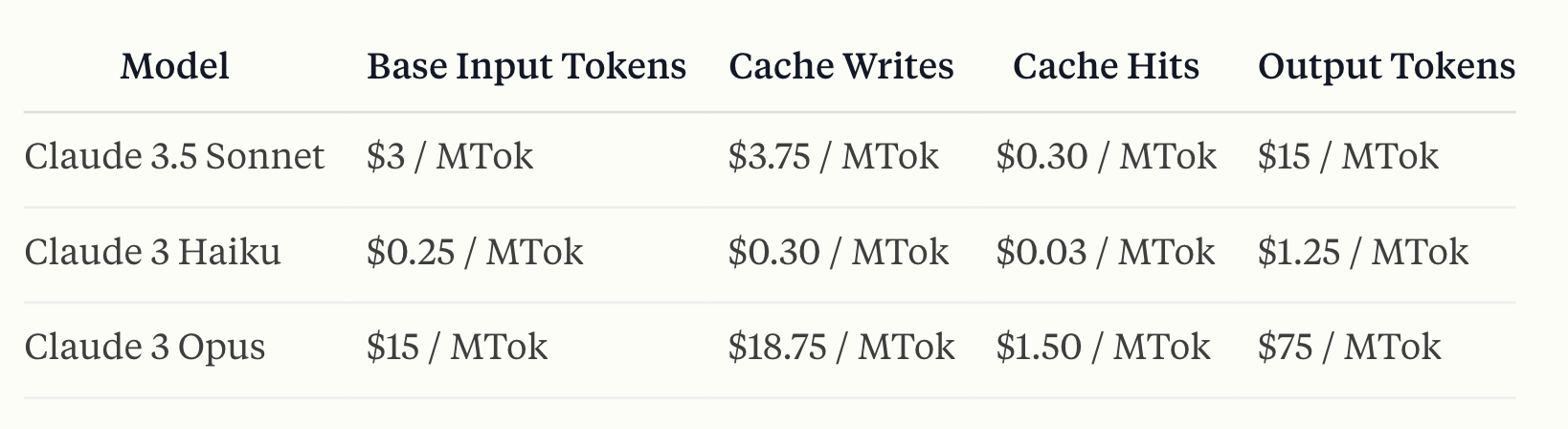
What can be cached using Anthropic?
Anthropic allows every block in an API request to be cached:
- Tools: Tool definitions in the
toolsarray. - System messages: Content blocks in the
systemarray. - Messages: Content blocks in the
messages.contentarray, for both user and assistant turns. - Images: Content blocks in the
messages.contentarray, in user turns. - Tool use and tool results: Content blocks in the
messages.contentarray, in both user and assistant turns.
These can be designated for caching using cache_control.
How to Structure your Prompt for Anthropic Prompt Caching
Similarly to OpenAI, you need to place static content (tool definitions, system
instructions, context, examples) at the beginning of your prompt. However,
Anthropic requires that you mark the end of the reusable content for caching
using the cache_control parameter and advises that you match the cache prefix
order of: tools, system, then messages.
Example prompt:
{
"tools": [
{
"name": "get_weather",
"description": "Get the current weather in a given location",
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature, either 'celsius' or 'fahrenheit'"
}
},
"required": ["location"]
}
},
{
"name": "get_time",
"description": "Get the current time in a given time zone",
"input_schema": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "The IANA time zone name, e.g. America/Los_Angeles"
}
},
"required": ["timezone"]
},
"cache_control": {
"type": "ephemeral"
}
}
],
"system": [
{
"type": "text",
"text": "You are an AI assistant tasked with providing weather and time information.",
"cache_control": {
"type": "ephemeral"
}
}
],
"messages": [
{
"role": "user",
"content": "What's the weather and time in New York?"
}
]
}
In this example, the static content is placed at the beginning of the prompt,
following the order: tools, system, then messages. The cache_control parameter
is used to mark the end of reusable content for caching and is set to
{"type": "ephemeral"}, which corresponds to a 5-minute cache lifetime.
Requirements and Limitations
The minimum cacheable prompt length is:
- 1024 tokens for Claude 3.5 Sonnet and Claude 3 Opus
- 2048 tokens for Claude 3 Haiku
Shorter prompts won’t be cached even if marked with cache_control. You can see
if a prompt was cached by checking the usage
fields.
Best Practices for Anthropic Prompt Caching
- Cache stable, reusable content like system instructions, background information, large contexts, or frequent tool definitions.
- Aim to place cotent you wish to cache towards the top of your prompt to maximize cache hits.
- Use cache breakpoints strategically to separate different cacheable prefix sections.
- Regularly analyze cache hit rates and adjust your strategy as needed.
Prompt Caching with CacheGPT
In other frameworks like GPTCache, the mechanics may look different. In the below example, an LLM adapter is used to dynamically choose the more appropriate model to complete a request. User input is turned into a vector embedding, where a similarity search is performed on the cache storage. If there’s a match (“cache hit”), this cache is used to generate the response. If not, the LLM generates a new response and this is stored in the cache manager, where it can be retrieved if a similar request should reoccur.
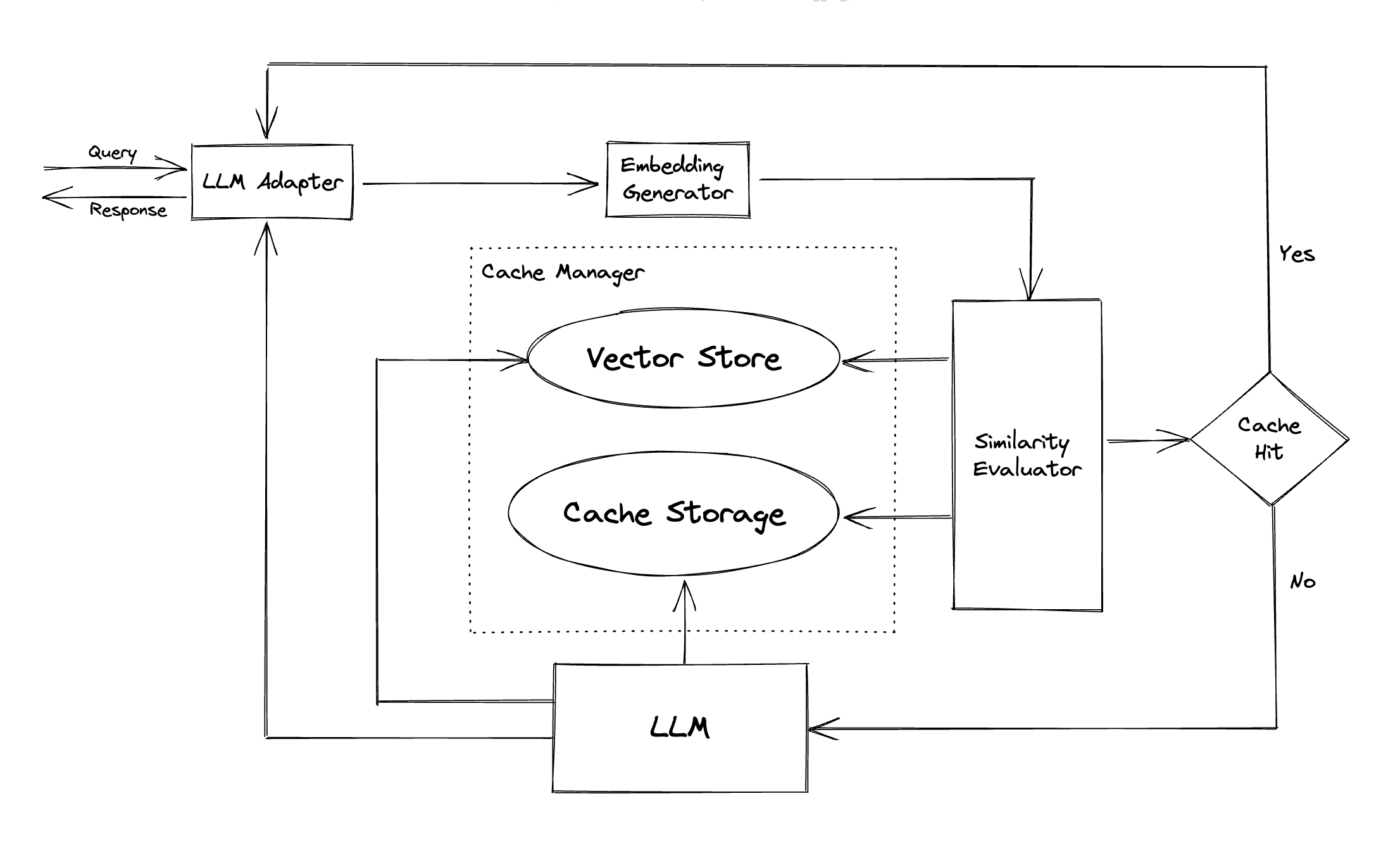
For cache management, GPTCache uses techniques such as Least Recently Used (LRU) and First-In, First-Out (FIFO).
Benefits of Prompt Caching
While improved response times and reduced operational costs are the most recognized advantages, there are additional underlying benefits that prompt caching can have on AI applications.
1. Scalability and Resource Efficiency
Prompt caching makes AI applications more scalable by reducing the computational load per request to the LLM. This enables developers and organizations to support more users and manage increased demand without proportionally expanding infrastructure.
2. Enhanced User Experience
Prompt caching provides a more consistent user experience by reducing respone times.
3. Energy Efficiency
By decreasing the need for repetitive processing, prompt caching also reduces energy consumption, making AI operations more environmentally friendly.
4. Security and Privacy
Reducing the frequency in which sensitive data is processed enhances security. Fewer instances of data processing mean reduced exposure to potential breaches. With prompt caching, sensitive prompts are handled less often, helping to safeguard critical information.
Real-World Applications
Below are three key examples of where prompt caching can be in useful in real-world AI applications:
Conversational Agents
Conversational agents, such as customer service bots, often manage a high volume of similar inquiries. These agents can struggle with maintaining quick response times under heavy load, particularly when dealing with repeated questions. Prompt caching directly addresses this by allowing the agent to instantly retrieve responses to frequently asked questions, ensuring users receive consistent and immediate answers. This boosts the agent’s ability to manage more complex, non-routine queries without delay, improving the overall customer experience and operational efficiency.
Coding Assistants
For coding assistants, efficiency is crucial. Developers frequently ask for the same functions, syntax patterns, or debugging tips. Without prompt caching, these requests would repeatedly consume processing power, slowing down the development workflow. By caching and reusing common code suggestions or error fixes, coding assistants can instantly deliver the necessary information, speeding up the coding process. Prompt caching thus helps maintain a steady development pace, ensuring that repetitive coding tasks don’t become bottlenecks.
Large Document Processing
Processing large volumes of text, such as reviewing legal contracts or analyzing extensive reports, often involves parsing through repetitive sections, like standardized clauses or recurring financial statements. Processing each instance from scratch would be inefficient. Prompt caching enables quicker processing by storing outputs for these repetitive sections, allowing the system to skip reanalysis and directly retrieve the cached data. This significantly accelerates document review times and ensures consistency across multiple documents.
Challenges of Prompt Caching
Implementing and maintaining an effective caching system requires careful consideration of several factors that can impact its performance and overall effectiveness. These challenges highlight the need for thoughtful implementation and ongoing management to fully realize its potential without compromising system performance or security.
1. Cache Management and Invalidation
A major challenge is managing the cache, particularly in ensuring that outdated or irrelevant data doesn't degrade the quality of responses. Cache invalidation—deciding when to update or discard cached data—is crucial. If old data persists, it can lead to inaccurate or misleading responses, undermining the system’s reliability.
2. Resource Constraints
Prompt caching consumes memory and storage, which can be a limiting factor, especially in large-scale deployments. Managing cache size efficiently often requires sophisticated algorithms, such as those that discard the least frequently used data, adding complexity to the system.
3. Implementation Complexity
Integrating prompt caching into existing systems can be complex and requires a deep understanding of the application’s use cases. Designing a cache that effectively stores valuable data without introducing new bottlenecks is challenging. Additionally, ensuring that the cache improves, rather than hampers, system performance requires careful planning and ongoing tuning.
4. Security and Privacy Risks
Caching sensitive data introduces security and privacy concerns. If cached data isn’t properly secured, it could be vulnerable to unauthorized access. Implementing robust encryption and access controls is essential but increases the complexity of the system. Moreover, the risk of inadvertently caching sensitive information adds another layer of concern.
Learn More About Prompt Caching
By leveraging prompt caching, enterprises can unlock new levels of efficiency, scalability, and cost-effectiveness in their AI applications.
At Humanloop, we help enterprises develop AI applications that perform reliably at scale. Prompt caching is one of many tools available to our customers to make their applications faster and more efficient.
To learn more about how our collaborative platform for developing, managing, and optimizing AI applications can support you and your team, book a demo today.
About the author

- 𝕏@conorkellyai










