Prompt Engineering 101
In this post, we'll explore the fundamentals of prompt engineering. We'll explain how Large Language Models (LLMs) interpret prompts to generate outputs, and provide tips and tricks to get you started prototyping and implementing LLMs quickly.
The recent rise of Large Language Models (LLMs) such as GPT-3, ChatGPT, AI21's Jurassic, and Cohere has revolutionized what can be achieved with AI. These models, trained on vast amounts of text, can answer questions, generate marketing content, summarize meeting notes, write code, and much more -- if used correctly.
Interacting with LLMs is very different from traditional ML models. We provide a textual prompt as instructions to the LLM to complete a specific task, relying on its pre-training on large datasets to give us an accurate answer.

An example of a prompt (non-highlighted text) to an LLM (GPT-3 in this case) asking it to translate a sentence from English to Turkish with the output of the LLM highlighted in green.
These instructions are called prompts. Prompts are the input to an LLM and their purpose is to tell the LLM what to do or how to think about a problem to get the best and most accurate output to a task possible. Adjusting a prompt to get more specific/usable responses from an LLM is called prompt engineering and is a key skill; it’s the biggest part of the effort of using LLMs.
Prompt engineering can be a difficult task but is essential to get the most out of an LLM. In this article, we’ll cover best practices for creating prompts so you can start building effective LLM applications.
Include direct instructions in prompts
For simple tasks (at least simple for GPT-3) the best prompt is a clear, direct, and concise one that tells the LLM the exact task we are trying to solve. Let’s take a simple example asking GPT-3 (which is instruction tuned) to translate a sentence from English to Spanish. Our prompt will consist of three elements:
- A clear, concise, and direct instruction: “Translate.”
- The English phrase we want translated preceded by “English: ”
- A clearly designated space for the LLM to answer preceded by the intentionally similar prefix “Spanish: ”
These three elements are all part of a direct set of instructions with an organized answer area. By giving GPT-3 this clearly constructed prompt, it will be able to recognize the task being asked of it and fill in the answer correctly.

If in doubt, just ask. Here's an example of a translation task using GPT-3 where the prompt includes a direct instruction “Translate.” followed by a clear area for the model to respond.
Without clear instructions, LLMs are likely to behave erratically and be more likely to give an answer we were not expecting. Let’s take the same prompt and remove the one word instruction preceding the English sentence: “Translate.”. We can see how just one word being removed from our prompt makes GPT-3 misinterpret the task entirely and instead responds to the question “How do you reset your password” with a generic customer support response in Spanish.

Without a direct instruction (such as “Translate”), GPT-3 then incorrectly interprets the task.
Give examples in prompts to get the best response
If clear and direct instructions aren’t enough for a task to be solved consistently and accurately, it is usually a good idea to give the LLM a few examples. This can be as simple as giving an LLM a single example of our task and letting the model figure out the rest.
Let’s see an example on our English to Spanish translation task. We’ll replace the instruction, “Translate.”, with a single example of an English to Spanish translation instead. We should format the example in the exact same way as the final pair except the Spanish translation will be filled in for our example to tell the LLM what we are trying to do.
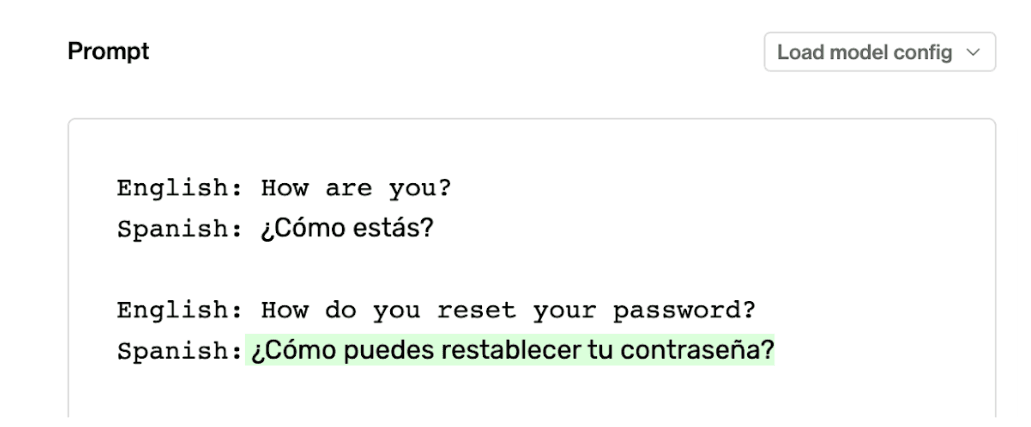
Few-shot learning can help clarify the task, and especially help with things like tone, syntax or style. Here a single example of translation is enough for the the model respond correctly.
We can see that by giving the model an example of what we want, the model can figure out the task as if we gave it a direct set of instructions. Including examples in prompts is called few-shot learning. This is such a breakthrough capability with GPT-3, that it was the main focus in the the title of its research paper: “Language models are few-shot learners”. The creators of GPT-3 knew that few-shot learning was so powerful that it would be one of the dominant ways people interacted with their model.
By using few-shot learning, we can provide an LLM with an understanding of our task without explicitly providing instructions. This can be especially helpful when the task is specific to a certain field or when the response language must be tailored to a particular organization (e.g. using P1, P2, and P3 instead of High, Medium, and Low priority).
Align prompt instructions with the task’s end goal
When engineering a prompt, we need to put ourselves in the shoes of the LLM and ask: what will the model think the end goal of my task is?
For example, if we want the model to respond to a customer with a single response in a friendly way, we might write a prompt like:
"This is a conversation between a customer and a polite, helpful customer support service agent."
This provides a clear and direct instruction to the model. However, we must consider what GPT-3 will think the task actually is.

GPT-3 will take things literally. Saying “this is a conversation” in the prompt makes GPT-3 makes GPT-3 generate a full dialogue (the most likely continuation) rather than just giving a single response
We can see that GPT-3 thought the task was to create an entire conversation transcript given the customer’s initial input and not simply to just respond once to the customer. GPT-3 was not wrong necessarily but it was misaligned with the original specific task intention. Let’s instead change our prompt to “Respond to a customer as a polite, helpful customer service agent.”.
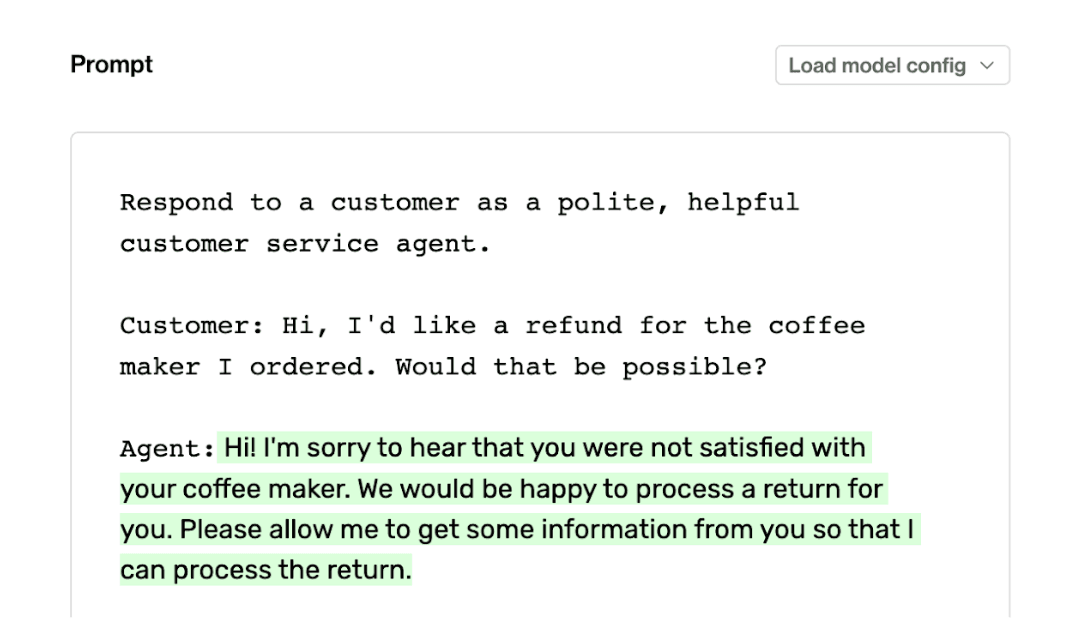
Changing the prompt to say “Respond to ...” is more aligned with the end goal of what we wanted from the LLM.
The small change from "this is a conversation..." to "respond to a..." aligned GPT-3's response with our desired outcome. Prompts must be both direct and tailored to the task; when they are not, the model will respond with what it believes is the correct task, regardless of our intention.
Use personas to get more specific voices
In our last example, we wanted GPT-3 to respond to a customer as a polite and helpful customer service agent. The use of the terms "polite" and "helpful" guide the model's response style, prompting it to respond as a certain persona. We can experiment with these terms to see how it affects the model's response. Let's change "polite, helpful" to "rude" and observe the model's response.

Specify the tone or persona you wish GPT-3 to emulate. Asking GPT-3 to respond rudely will result in a rude response. Be careful what you wish for.
GPT-3, being the amoral algorithm it is, accurately responds to the question, albeit vaguely, with a tone that better identifies with the word "rude". We can go as far as asking the model to respond as famous people or popular fictional characters. This can be used to our advantage as a shorthand to create a particular tone for the response.
Include acceptable responses in prompts for consistency
Another way to form prompts is as a “complete this sentence” prompt. In this style of prompt, we are asking the LLM to complete a sentence with the answer we are seeking which generally leads to more natural language. Here is an example prompt run through GPT-3 asking for the sentiment of a movie review:

Without specifying the format of the output, you'll likely get a natural language response which can be hard to use for downstream tasks
Technically GPT-3 answered correctly here. The sentiment of the review was that they didn’t like the movie. But If we wanted to narrow down the universe of possible results with prompt engineering to make our response more like a sentiment classifier we could tweak this prompt slightly and give it a list of possible answers directly in the instruction of the prompt. In this case, let’s guide GPT-3 to only respond with either “positive” or “negative”.

Including the options of possible responses in our instruction (in this case a binary choice) nudges GPT-3 to respond only using one of the two options instead of the previously overly natural response
The result is much more aligned with a binary classifier where GPT-3 is now only responding using the two given options. From here we can alter the label names as long as they are semantically appropriate.

LLMs can decipher and assign semantically appropriate labels as long as they make semantic sense
Could we have achieved similar results using few-shot learning? Probably but this prompt is much more concise and we don’t need to spend the time coming up with examples.
Try different prompts to find what works best
We could go on with more tips and tricks on how to engineer prompts but the best way to get you going is to try variations of the same basic prompt to see what works best. For example:
- When attempting few-shot learning, try also including direct instructions
- Rephrase a direct instruction set to be more or less concise (e.g. taking our previous example of just saying “Translate.” and expanding on the instruction to say “Translate from English to Spanish.”
- Try different persona keywords to see how it affects the response style
- Use fewer or more examples in your few-shot learning
At the end of the day, prompt engineering is about finding the right combination of instructions, examples, and formatting to get the best and most consistent responses from an LLM. Make good use of the Playground to find the right prompt structure for you, and then try it out with plenty of examples with tools like Humanloop to see how it performs on real world data.
Summary
We have seen several tips for getting started with prompt engineering. For a quick recap:
- Use clear, direct, and concise instructions
- Try “complete this sentence” prompts for more natural responses
- Use examples (few-shot learning) of the task
- Align prompt instructions with a clear end goal
- Use persona keywords to alter the style and voice of the response
- Constrain the LLM’s responses by listing desired responses in the prompt
- Experiment with variations of the prompt to see what works best for you!
Go on and start engineering prompts with these newfound skills and remember that if at first you don’t succeed, try and try (a different variation of a prompt) again!
About the author

- 𝕏@RazRazcle


About the author









