Retrieval Augmented Generation (RAG): Explained
Retrieval Augmented Generation (RAG): Explained
Retrieval-Augmented Generation (RAG) is a prevalent technique in generative AI for building applications using custom data and pre-trained models. It has gained popularity due to its effectiveness and relative ease of implementation. If you’re developing tools or products with Large Language Models (LLMs) like GPT-4 or Claude 3, it’s important to familairaize yourself with RAG so you know how and when to use it.
This blog explains what RAG is, how it works, and why it’s important.
What is Retrieval Augmented Generation?
Retrieval-Augmented Generation (RAG) is a method in Large Language Model (LLM) application development that dynamically integrates data from external sources into an LLM's context window to enhance the generation process.
As this data can be external to the model’s training data, it can include proprietary, time-sensitive, or domain-specific data, which may contain more accurate, relevant and/or improved content for a wide range of LLM applications.
RAG is most commonly used in LLM applications which require access to new context or specific data in order to perform a task. We see RAG being used everyday in applications like:
• ChatGPT web-search
• Internal enterprise chatbots
• “Chat to PDF” services
How Does Retrieval Augmented Generation Work?
A RAG pipeline is designed to give additional context to an LLM which can be used to augment its completions. Below is a breakdown of the anatomy of a RAG application: When a user query is submitted, the content of the query is passed through a retrieval process which pulls relevant information from a specified data source (knowledge base). This information, along with the user query, is then incorporated into a prompt template which contains respective placeholders and instructions for the LLM. The LLM then processes the enriched template and generates a contextually enhanced response which is returned to the user.
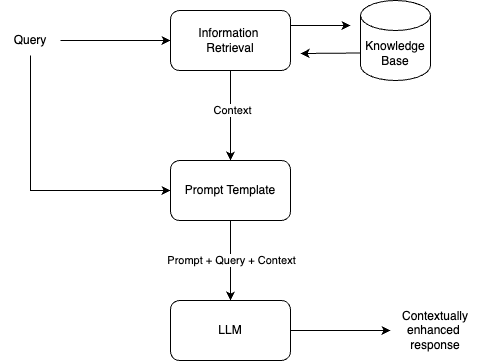
When developing a RAG application, the objective is to engineer the various components such that for a given user query, relevant information is retrieved and the LLM has clear guidance, enabling it to generate desirable output. Here are the important steps necessary to achieve this:
1. Build a knowledge base
To get started with RAG, an external database is required. Typically, this database should contain information not already present in the LLM's training data. For instance, in an enterprise chatbot, this may be internal company information from documentation or proprietary databases.
The most common approach in RAG for building a knowledge base is using text data, embedding models and vector databases like Pinecone or ChromaDB. In this approach, the text data is converted into vectors (numerical representations) using an embedding model like OpenAI’s text-embedding-3-large, and then stored on a vector database. Vector storage is designed to capture complex, high-dimensional data. This provides a representation of semantics, contextual relevance, conceptual similarity and more within the text data.
2. Information Retrieval
The retrieval component takes the user query as a basis for its search. For example, if your external data source/knowledge base was Google search, and a user query was “What is the weather like today in London?”, this would be run on Google and the top search results would be given to the LLM as context to respond to the query. This example can easily be implemented using Humanloop Tools.
In a RAG pipeline built on a vector database, when a user inputs a query, the text is embedded into vectors in real-time (using the same embedding model as before). These vectors are then matched with those stored in the database, and the ones most similar to the query are retrieved. This process is called vector search, and since it enables the capture of a broader context within the embedded text, the relevance of the information retrieved should be significantly enhanced.
Getting the retrieval process working effectively is crucial as it will determine the reliability of the RAG pipeline. There is room for experimentation here between how you prepare your data, choose the database and select a retrieval method. Our guide to optimizing LLM applications covers when to use RAG and how you should set it up.
3. Augment the Prompt Template
The prompt template contains the instructions you provide to the LLM. Here, you describe the task step-by-step and create dynamic inputs for the user’s query and retrieved context (as known as chunks). The LLM will see something which resembles the following:
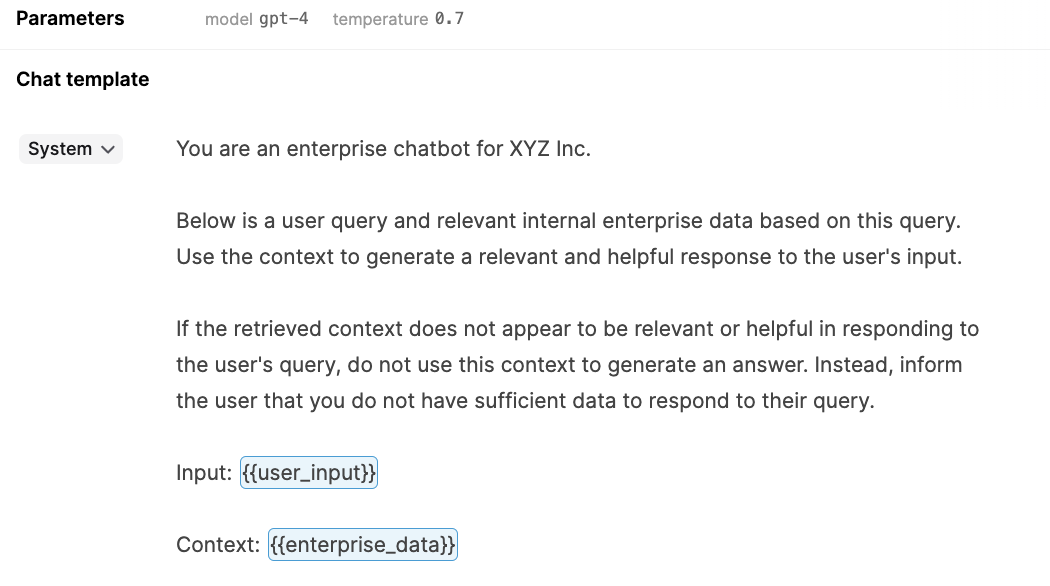
Based on the combined information in the prompt template, the LLM generates a response. The prompt template is by far the most powerful component of the RAG framework, and it’s imperative that the model understands its task and consistently performs.
At this step, it’s crucial to ensure that your prompt engineering approach is applied appropriately, enabling the model to discern when (and when not) to utilize the retrieved data. For this purpose, using a larger model, such as GPT-4 or Claude 3 is advisable, as their enhanced reasoning capabilities will significantly improve performance.
4. Evaluate performance
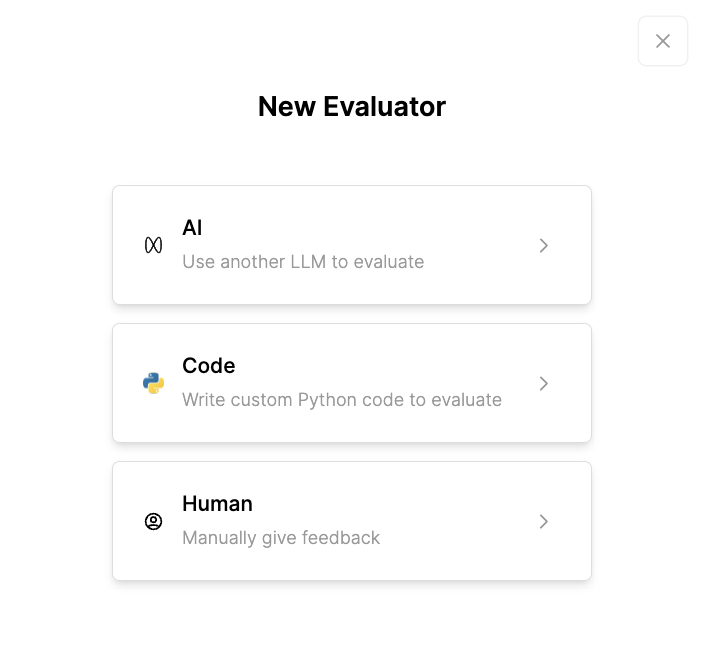
Comprehensive testing and evaluation of the RAG system should be consistently undertaken during development and whilst in production. Humanloop’s evaluation features support this process for each stage of the development lifecycle.
By using Humanloop, you can develop test sets of inputs and automatically run evaluations of prompts and tools (in this case, your retriever), whose performance can then be scored based on the evaluation metrics you set. Humanloop offers flexibility to accommodate the full spectrum of complexity in the judgments required for providing evaluation scores, enabling you to create evaluators using AI, code (Python), or human review. To learn more, read about our approach to evaluating LLM applications.
Why is Retrieval Augmented Generation Important?
RAG is crucial for applications that require awareness of recent developments or specific domain knowledge. It represents a straightforward, cost-effective approach to provide an LLM with new context without the need for retraining or fine-tuning, enabling teams to quickly iterate during the development of AI applications built on their own data.
Benefits of Retrieval Augmented Generation
Speed
RAG frameworks can be relatively quick to build, allowing teams to promptly develop custom AI applications. Building a RAG pipeline on a pre-trained model significantly outpaces the time required to train a custom model. It is also quicker and easier to make real-time interventions and updates to RAG pipelines, compared to that of custom-trained or fine-tuned models.
Cost Effective
Compared to the cost of training an LLM for an enterprise application, RAG is a vastly cheaper alternative. The set-up cost is minimal and pricing is based on token usage per API call to the models being used.
Information is Current
Popular LLMs like GPT-4 and Claude 3 are static, meaning their knowledge cuts off after their training date, which trails a few months behind their release date. RAG can be used to overcome this by containing current information in the knowledge base.
Increased User Trust
Developers can label chunks with their original source before storing them in the knowledge base. This way when they’re retrieved, the LLM has the context of the data source and can reference this its completions, allowing a user to verify the source themselves. Known as grounding the LLM, this enhances data visibility and is useful in LLM applications in legal, healthcare, financial and other critical settings.
Retrieval Augmented Generation with Humanloop
Humanloop is a collaborative enterprise platform for developing and evaluating LLM applications. We solve the most critical workflows around prompt engineering and model evaluation, which allows product managers and engineers to work together to find, manage, and measure prompts. Coupled with this are tools for rigorously monitoring and evaluating performance, both from user feedback and automated evaluations. Using Humanloop, you can develop the different components of your RAG system with a dedicated environment for prompts and tools (retrievers) where you can test, evaluate, and track performance. This makes it easier for your teams to work together to get AI from playground to production. To learn more, you can book a demo.
About the author

- 𝕏@conorkellyai










