Why I changed my mind about weak labeling for ML
When I first heard about weak labeling a little over a year ago, I was initially skeptical. The premise of weak labeling is that you can replace manually annotated data with data created from heuristic rules written by domain experts. This didn't make any sense to me. If you can create a really good rules based system, then why wouldn't you just use that system?! And if the rules aren't good then won't a model trained on the noisy data also be bad? It sounded like a return to the world of feature engineering that deep learning was supposed to replace.
Over the past year, I've had my mind completely changed. I worked on numerous NLP projects that involved data extraction and delved a lot deeper into the literature surrounding weak supervision. I also spoke to ML team leads at companies like Apple, where I heard stories of entire systems being replaced in the space of weeks - by combining weak supervision and machine translation they could create massive datasets in under-resourced languages that previously were just not served!
Since I now have the zeal of a convert, I want to explain what weak supervision is, what I learned and why I think it complements techniques like active learning for data annotation.
Weak Supervision is a form of programmatic labeling
The term "weak supervision" was first introduced by Alex Ratner and Chris Re who then went on to create the Snorkel open source package and eventually the unicorn company Snorkel AI. It's a three-step process that lets you train supervised machine learning models starting from having very little annotated data. The three steps are:
1. Create a set of "labeling functions" that can be applied across your dataset
Labeling functions are simple rules that can guess the correct label for a data point. For example, if you were trying to classify news headlines as "clickbait" or "legitimate news" you might use a rule that says:
"If the headline starts with a number predict that the label is clickbait and if not don't predict a label."
or in code:
def starts_with_digit(headline: Doc) -> int:
"""Labels any headlines which start with a digit.""
if headline.tokens[0].is_digit():
return 1
else:
return 0
It's clear that this rule won't be 100% accurate and won't capture all clickbait headlines. That's ok. What's important is that we can come up with a few different rules and that each rule is pretty good. Once we have a collection of rules, we can then learn which ones to trust and when.
2. Use a Bayesian model to work out the most likely label for each data point
The good news for a practitioner is that a lot of the hardest math is taken care of by open-source packages.
It's helpful to keep an example in mind, so let's stick to thinking about classifying news headlines into one of two categories. Imagine that you have 10000 headlines and 5 labeling functions. Each labeling function tries to guess wether the headline is "news" or "clickbait". If you wanted to visualize it, you could put it together into a large table with one row per headline and one column for each labeling function. If you did that you'd get a table like this with 10,000 rows and 5 columns:
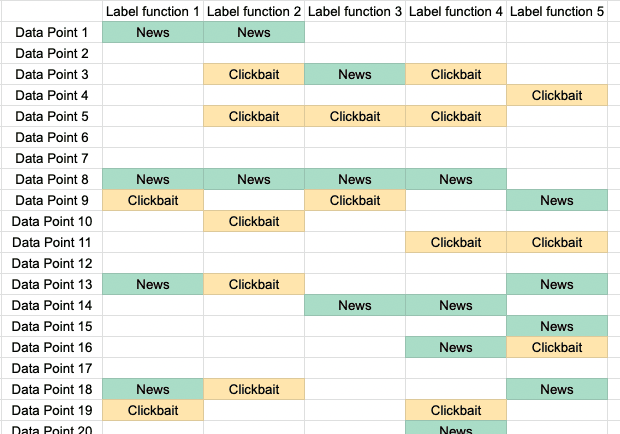
Labeling functions for clickbait detection. Each rule can vote for "News", "Clickbait" or abstain.
The goal now is to work out the most likely label for each data-point. The simplest thing you could do would be to just take the majority vote in each row. So if four labeling functions voted for clickbait, we'd assume the label is clickbait.
The problem with this approach is that we know that some of the rules are going to be bad and some are going to be good. We also know that the rules might be correlated. The way we get around this is to first to train a probabilistic model that learns an estimate for the accuracy of each rule. Once we've trained this model we can calculate the distribution for each of our data-points. This is a more intelligent weighting of all the 5 votes we get for each data-point.
Intuitively a model can tell that a rule is accurate if it consistently votes with the majority. Conversely a rule that is very erratic and only sometimes votes with the majority is less likely to be good. The more approximate rules we have, the better we can clean them up.
There is a lot of freedom in what model you choose to clean up the labels, and how you train it. Most of the research in the early days of weak supervision was in improving the model used and the efficiency of training. The original paper used a naive Bayes model and SGD with Gibbs sampling to learn the accuracy of each rule. Later methods were developed that can learn the correlations between labeling functions too and recent work has used matrix completion methods to efficiently train the model.
3. Train a normal machine learning model on the dataset produced by steps one and two
Once you have your estimates for the probability of each label, you can either threshold that to get a hard label for each data-point or you can use the probability distribution as the target for a model. Either way, you now have a labeled dataset and you can use it just like any other labeled dataset!
You can go ahead and train a machine learning model and get good performance, even though you might have had no annotated data when you started!
A big weakly-supervised dataset is just as good as a small labeled dataset
One of the cool proofs in the original paper shows that the performance of weak labeling gets better the more unlabeled data you have at the same rate that supervised learning gets better the more data you have!
The above sentence is a bit of a mouthful and is easy to miss but is really profound. It's something that I didn't appreciate when I first read about weak supervision. Understanding this properly is one of the reasons I've become a weak labeling advocate.
What it means is that once you have a good set of labeling functions, the more unlabeled data you add the better the performance will be. Compare that to supervised learning where to get better performance you have to add more labeled data which might require expert time.
Normally when you train a machine learning model like logistic regression you can predict that your expected test-set error will shrink the more labeled data you have. You can say even more than this though. The size of your test set error gets smaller at rate that is , for n labeled data points. So if you want to reduce your test error you have to label a lot of data and each extra data-point (selected at random) improves the model less and less.
When you train a machine learning model with weak supervision your expected test-set error still goes as but now n is the number of unlabeled data points! This is fantastic because you can use a small amount of expert annotator time to come up with good rules and then apply it to a huge dataset.
Intuitively a small but very clean dataset is equivalent to a large noisy data set. Weak supervision gives you a very large but slightly noisy dataset.
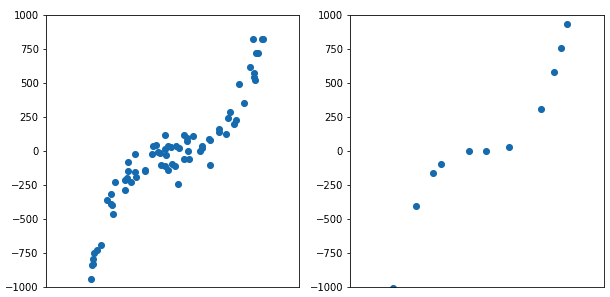
A large noisy dataset can match the performance of a small clean dataset.
Training a model on weakly labeled data gives a huge uplift in performance
One thing that isn't immediately obvious is why training a model on the data that came from rules will give better performance. Won't the model just learn to replicate the rules?!
The answer here is no and the reason is that the features that a discriminative model uses don't need to be the same ones that are used as inputs to your heuristics or rules. This means that:
-
The model can generalize beyond the weak rules because it extracts features that are more general.
E.g. A weak rule for sentiment might use a bunch of keywords. The discriminative model trained on the data from the weak rule doesn't see those keywords and instead learns a more general feature about word order and other word occurrences.
-
You can use inputs and features for your rules that may not be available at prediction time.
E.g. Say that you have a dataset of medical images and accompanying doctor's notes and you want to train a classifier just on the images. You can write a set of rules that takes the textual notes and produces labels for the images. The rules are not useful for the image classifier but the output of the rules is.
In practice, there have been a lot of case-studies now that prove this out. For example this paper achieved was able to do medical extraction with no labeled data and still come within 2% of state-of-the-art fully supervised models.
Training the discriminative model on the denoised rules, almost always adds a very significant bump in performance. As much as 10 f1 points is not uncommon.
Remember that after the first two steps, you just have a labeled dataset. Asking why a discriminative model can generalize on the rules is entirely equivalent to asking how any model can generalize beyond hand labeled data. In both cases you provide a model with a (noisily) annotated dataset and hope it can learn to generalize to new instances.
Weak Supervision makes much better use of expert time
In NLP it's often the case that you need domain expertise to provide the annotations and its also often the case that you just can't get a lot of domain expert time.
For example if you want to extract information from legal documents, you somehow need to persuade lawyers to annotate data. Often the domain gets so specific that you don't just need any lawyer but a lawyer from a specific practice. Persuading that lawyer to give up even a few hours of time can be extraordinarily difficult. If you're doing manual annotation, even with tools like active learning, you might still need hundreds of labels. In this case you can't throw more money at the problem. You need to be able to get more labels from a fixed amount of expert time. Weak supervision provides an answer for this. In a short session with a domain expert it is possible to brainstorm a lot of heuristic rules and then rely on the availability of unlabeled data to solve your problem.
Similar issues with expert availability come up in the medical domain, where again the only people who can do the annotation may be working full-time jobs. If you can only get a few hours a week of someone's time, weak labeling is a better use of that time than pure manual annotation. In this paper, a single expert in 1 day was able to match the performance of a team of labelers working across several weeks.
How to use weak supervision today?
The easiest way to access weak supervision at the moment is to use the open source packages Snorkel or Skweak.
Snorkel was originally actively supported by the researchers who developed these techniques. It has useful helper functions for both creating, applying and evaluating labeling rules. It also has support for applying data transformations: like flipping an image, or replacing synonyms in text. The only model supported is one that assumes all of your labeling functions are independent of each other. If you produce correlated labeling functions or are working with sequence data, it won't work as well. The library isn't under active development but does seem to be accepting community contributions.
Skweak is a more recent academic project that is focused on weak labeling for NER on text. The model it uses to denoise the data is based on a hidden Markov model and so can do a better job of handling correlations between data points (but still not labeling functions). Skweak is more opinionated about being for text sequences and so operates on top of spaCy Doc objects. This has a lot of nice advantages when working with text because you can utilize the parts-of-speech and other tags that spaCy models apply to your data. The library is fairly new but definitely one to watch.
What's missing from existing weak labeling options?
The existing open source packages are focused on the mathematical tools needed to go from noisy labeling functions to cleaned up datasets. This is definitely one of the hardest parts so it makes a lot of sense that they started there. When I started using weak labeling for the first time though, I realized that you need a lot more than this.
Coming up with the labeling functions is a highly iterative process, that needs feedback. You come up with a rule, see how good it is and then iterate till you have a a good set of rules. "seeing how good it is" is hard though. I found I had to write a lot of boilerplate code to apply my labeling functions and then code to display the results. The feedback/debug cycle was really long and so what should have been 15 minutes of work expanded into hours.
Access to external resources like dictionaries of keywords or knowledge bases accelerates rule creation too. Some of the most effective rules use external resources. For example, if you wanted to do NER to find mentions of drugs in health records you could use a dictionary of known drug names. This won't cover all examples but it makes for a great labeling function. Organizing these resources and incorporating them into your weak labeling platform is a bit of yak shaving that adds a lot of friction.
Having a small amount of ground truth data still helps a lot. You still need to be able to evaluate any models you've trained, so ultimately you do need an annotated test set. Having some labeled validation data before you create your rules also makes it much easier to know how good the rules are and to iterate faster.
Weak labeling overcomes cold starts, Active Learning goes the last mile
At Humanloop, we've been working on tools to make it easier for domain experts to teach AI models fast.
The first set of tools we built focused on making it much easier to use active learning. Active learning uses your model to find the most valuable data to annotate so you can get results with less labeled data. It's a great technique and it becomes increasingly important when you're trying to go from a model that is ok for a proof-of-concept, to one that is good enough for production.
However to get active learning going, you need some initial seed data that can start the process. You have to over come a cold start. This is where weak labeling is particularly powerful. It gets you the data you need for a first model in the space of minutes to hours.
We've recently started building a new weak labeling tool, to complement the active learning platform we've built so far. What we're building is designed from first principles to be something data scientist's love: You can run it locally so you don't have to worry about data privacy; its fully scriptable with sensible defaults and it plays nicely with packages like SpaCy and Hugging Face.
Preview of Humanloop Programmatic
We're currently running a closed beta with a small number of data science teams in the NLP space. If you're working on an NLP project where getting annotated data has proved challenging, we'd love to help you out.
Sign up here to join our closed beta.
- Create "labeling functions" that can be applied across your dataset.
- Use a Bayesian model to work out the most likely label for each datapoint.
- Train a machine learning model on the dataset produced by steps 1 and 2.
- A big weakly-supervised dataset is just as good as a smaller manually labeled dataset.The more datapoints you have in your dataset, the better weak supervision performs!
- Training a model on weakly labeled data gives a huge uplift in performance.The model will not learn to simply replicate your rules, but can generalize beyond the weak rules.
- Weak supervision makes much better use of expert timeIf you can only get a few hours a week of someone's time, weak labeling is a better use of that time than pure manual annotation. In this paper, a single expert in 1 day was able to match the performance of a team of labelers working across several weeks.
- Snorkel was originally actively supported by the researchers who developed these techniques. However, the library is no longer under active development.
- Skweak is a more recent academic project that is focused on weak labeling for NER on text, and uses spaCy Doc objects.
At Humanloop, we've built Programmaticto allow you to rapidly iterate on your labeling functions and get fast feedback, all while keeping your data private.
Get it for free here.
About the author

- 𝕏@RazRazcle










