Why you should take a data first approach to AI
Machine learning systems are born through the marriage of both code and data. The code specifies how the machine should learn and the training data encapsulates what should be learned. Academia mostly focuses on ways to improve the learning algorithms, the how of machine learning. When you come to build practical AI systems though, the dataset you're training on has at least as much impact on performance as the choice of algorithm.
Although there are a lot of tools for improving machine learning models, there are very few options when it comes to improving your data set. At Humanloop, we've given a lot of thought to how you can systematically improve data sets for machine learning.
Improving your dataset can dramatically improve AI performance
In a recent talk, Andrew Ng, shared a story from a project he worked on at Landing AI, building a computer vision system to help find defects in steel. Their first attempt at the system had a baseline performance of 76%. Humans could find defects with 90% accuracy so this wasn't good enough to put into production. The team working on the project then split in two. One team worked on trying different model types, hyper-parameters and architecture changes. The other team looked to improve the quality of their data set. After a few weeks of iteration, the results came in. The modeling team despite huge effort had not been able to improve performance at all. The data team on the other hand were able to get a 16% performance improvement. Improving the dataset actually led to super-human performance on this task.
By fixing errors in their data set the data-team was able to take their algorithm from worse than human to super-human.
This story isn't at all unique. I've had a similar experience at Humanloop. We worked with a team of lawyers from one of the big-4 accountancy firms to train a document classifier on legal contracts. Similar to finding defects in steel, the task was subtle and required domain expertise. After the first round of labeling and training was complete, the model still wasn't good enough to match Human level performance. Within Humanloop, there's a tool to investigate data points where there is disagreement between the AI model and the human annotators. Using this view the team were able to find around 30 misclassifications in a data set of 1000 documents. Fixing just these 30 mistakes was enough to get the AI system to match human-level performance.
What do "data bugs" look like?
There's a lot of discussion of "data prep" and "data cleaning" but what actually differentiates high quality data from low quality?
Most machine learning systems today are still using supervised learning. That means that the training data consists of (input, output) pairs and we wish the system to be able to take the input and map to the output. For example, the input may be an audio clip and the output could be the transcribed speech. Or the input might be an image of a damaged car and the output could be the locations of all the scratches. At Humanloop we focus on NLP so an example input for us might be a customer service message and the output could be a templated response. Building these training datasets usually requires having humans manually label the inputs for the computer to learn from.
If there's ambiguity in the way data is labeled then the ML model will need much more data to get to high performance. There are a few different ways that data collection and annotation can go wrong:
-
Simple misannotations The simplest type of mistake is just a misannotation. This is when an annotator, perhaps tired from lots of labeling, accidentally puts a data point in the wrong class. Although it's a simple error, it's surprisingly common and can have huge negative impact on AI system performance. A recent investigation of benchmark datasets in computer vision research found that over 3% of all data points were mislabeled. Over 6% of the ImageNet validation data set is mislabeled. How can you expect to get high performance when the benchmark data is wrong?!

-
Inconsistencies in annotation guidelines There is often subtlety in the correct way to annotate a piece of data. For example, imagine that you are instructed to read social media posts and annotate whether or not they are product reviews. This seems like a straightforward task but once you start annotating you quickly realize that "product" is a remarkably vague instruction. Should you include digital media like podcasts or movies as products? If one annotator says "yes" and another annotator says "no", your AI system will inevitably have lower performance. Similarly if you're asked to put bounding boxes around pedestrians in images for driverless cars, how much of the background should you include?

Both of these examples might seem reasonable to a human annotator but if there's inconsistency between annotators then model performance will inevitably suffer. Teams need ways to quickly find sources of confusion between annotators and the model and fix this,
-
Imbalanced data or missing classes How we collect our data has a big impact on the composition of our datasets and that in turn can affect the performance of models on specific classes or subsets of data. In most real world datasets the number of examples found in each category we want to classify, the class balance, can vary wildly. This can cause worse performance but also exacerbates problems of fairness and bias.
For example, Google AI's face recognition system was famously poor at recognizing people of color and this was in big part a result of having a dataset that didn't have diverse enough examples. (Amongst many other problems)
Tools like active learning help find rare classes in larger datasets and so make it easier to produce rich balanced datasets.
Data quality matters even more in small datasets
Most companies and research groups don't have access to the internet scale datasets that Google, Facebook and other tech giants have. When the dataset is that large you can get away with some noise in your data. However, most teams are operating in domains where they have hundreds to thousands of labeled examples. In this small data regime, data quality becomes even more important.
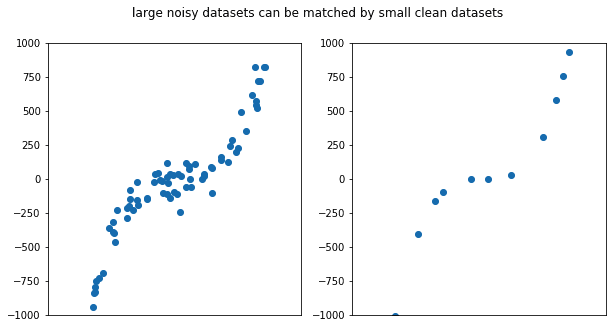
To get some intuition as to why data quality matters so much, consider the very simple 1-dimensional supervised learning problem shown above. In this case we're trying to fit a curve to some measured data points. On the left we see a large noisy dataset and on the right a small clean data set. It's clear that a small number of very low noise data points shows the same curve of a large but noisy dataset. The corollary of this is that noise in small datasets is particularly harmful. Though most machine learning problems are very high dimensional they operate on the same principles as curve fitting and are affected in analogous ways.
Intelligent tooling can make a huge difference to improving data quality
There are lots of tools for improving machine learning models but how can we systematically improve machine learning datasets?
Data Cleaning Tools
A workflow that some teams are beginning to adopt is to iterate between training models and then correcting "data bugs". Tools are emerging to facilitate this workflow such as label noise in context, Aquarium learning, and Humanloop.
The way these tools work is to use the model being trained to help find "data bugs". This can be done by looking at areas where the model and humans have high disagreement or at classes where there is high disagreement between different annotators. Various different forms of visualization can help find clusters of mistakes and fix them all at once.
Weak Labeling
Another approach to improving datasets is to embrace noise but use heuristic rules to scale annotation.
As we saw in the curve-fitting example above, you can get good results either through very small datasets that are clean or very large datasets that are noisy. The idea behind weak labeling is to automatically generate a very large number of noisy labels. These labels are generated by having subject-matter experts write down heuristic rules.
For example, you may have a rule for an email classifier that says "mark an email as job application if it contains the word 'cv'". This rule will not be very reliable but can be automatically applied to thousands or millions of examples.
If there are lots of different rules then their labels can be combined and denoised to produce high quality data.
Active Learning
Data cleaning tools still rely on humans to manually find the mistakes in data sets and don't help us address the problems of class imbalance described above. Active learning is an approach that trains a model as a team annotates and uses that model to search for high value data. Active learning can automatically improve the balance of data sets and help teams get to high performing models with significantly less data.
Data first approaches lead to better team collaboration
As we've written about recently, one of the big advantages of adopting a data-first approach to machine learning is that it allows for much better collaboration between all the different teams involved. Improving datasets forces collaboration between the subject-matter experts who are annotating data and the data scientists who are thinking about how to train models.
The increased involvement of non-technical subject-matter experts in training and improving machine learning models is one of the most exciting aspects of machine learning software compared to traditional software. At Humanloop we've been working on incorporating machine teaching into the normal workflows of non-technical experts so that they can automate tasks with much less dependence on machine learning engineers. In our next blog, we'll share some of our lessons on how machine learning will be incorporated into many people's daily jobs.
Andrew Ng describes how a data-centric approach improved performance by more than 16% while a model-centric approach failed to achieve any improvement in this talk.
- Misannotations: Incorrect labels. Even widely-used benchmark datasets have these! Check out this website with examplesand the accompanying paper.
- Inconsistencies in annotation guidelines: The difference between label classes is often extremely subtle. For example, what exactly is or isn't a "product" when classifying "Product reviews"?
- Imbalanced data or missing classes: Real world datasets often containing different number of examples for each category being classified. This can cause worse performance but also exacerbates problems of fairness and bias.
- Data cleaning tools such as Label Noise in Context, Aquarium learning, and Humanloop can improve your workflows by highlighting can improve your workflows by highlighting where the model and humans have high disagreement and by creating visualizations that help spot common mistakes.
- With weak labeling, you can embrace noise and use heuristic rules to scale annotation. With lots of different rules, the labels can be combined and denoised to produce high quality data at massive scale.
- Active learning improves data balance and helps teams get to high performing models with significantly less data.
About the author

- 𝕏@RazRazcle










