What is human-in-the-loop AI?
Human-in-the-loop AI is an automation approach, which removes the many problems of machine learning development and deployment
Most AI projects fail. 80% never reach deployment. Even more never make a return on the investment. The problem is that AI development is a process of experimenting, yet the traditional approach ignores this.
Many teams are now adopting an approach called human-in-the-loop AI (HITL). It means you can quickly deploy a working model, with less data and with guaranteed quality predictions. That sounds magical, but in this post we'll explain what HITL is and how you can make use of this approach in your own AI projects.
At a high level, HITL involves an AI system and a team of people working in collaboration to achieve a task.
There are two main modes of HITL: offline (humans helping to train the model) and online (humans helping the model make predictions). Both modes should be considered for the type of machine learning problem you are tackling. This enables you to iterate to get to a working model quickly and create an overall system architecture with guaranteed performance.
I learned the lessons of how to build these systems working on the training pipelines of Alexa, but they're equally applicable to the large self-driving car AI pipelines (as they do at Tesla) as they are to a small automation of a back office task.
We'll start by discussing the traditional approach to machine learning, adapted from the waterfall software development process before explaining the much better HITL training and HITL deployment approaches.
The typical waterfall process for training a machine learning model results in slow model iteration cycles and false starts
The typical process for training a machine learning model is a waterfall process, with the next step starting once the previous one has finished:
- you identify a task and define the project
- you collect and manually label the data, often with a team of people
- data scientists try a handful of different model architectures and training techniques, ranging from the simple to the powerful to see what works
- if it seems to perform well, it is deployed on a server behind an inference API
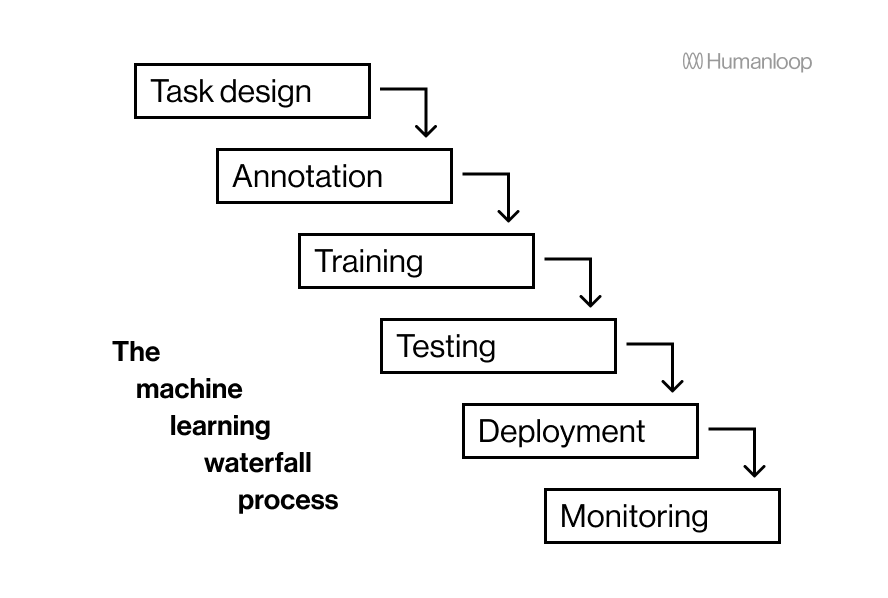
In the typical machine learning development process one step occurs after the other like a waterfall. The big downside is that it takes a long time to get feedback on the early stages, meaning iteration cycles are very slow and steps have to be repeated.
The approach seems straightforward and wonderful but it sneakily disguises the many pitfalls:
The task at the beginning is often not well defined.
It is incredibly hard to predict ahead of time how to best structure an AI project. For example, how should you formulate the task (classification, extraction, segmentation etc.), what features or constraints are needed, should any preprocessing be applied? and so on. It is typically only after the initial model's performance is inspected that the task can be refined into something likely to work well.
Creating the guidelines for annotation is an iterative process.
Similarly, it is hard to know ahead of time how the data should be annotated. It is through arguing over difficult data points after they are surfaced that the Annotation guidelines form a good working document. This data collection can take weeks or several months, especially if it is outsourced.
Test data ≠ live data, and you only find this out at the end.
In this approach, the model is worked on until it meets the performance criteria on the test data and only then does it get deployed. However, real world data can differ considerably to that initially collected. Unless you have a monitoring system in place, it may be many months before these issues are uncovered.
Data annotation and model training needs to be repeated.
AI companies have established that model training is almost never only done once and then forgotten about. It is more like an ongoing operational expense as you have to continuously annotate more data to track current model performance and improve the system. This is because the data changes over time and new features are wanted. Managing and maintaining this data will likely be the principal responsibility of an AI team.
...it takes a really long time
This is probably the biggest issue. This process requires different teams, from data scientists to subject-matter experts to infrastructure engineers and the whole cycle can take months.
Given all this, if you take this approach, you'll probably take far too long to finish your AI project.
Well what do all the successful AI projects do? Well, truth be told, many have big budgets and they use them to plow through with this approach, despite the wasted time, effort and cost. They'll end up investing significantly into their monitoring and data pipelines to make up for these shortcomings and enable weekly/monthly retraining loops through the whole process.
Practical companies will start with an ok solution and iterate quickly. Whether this is through HITL training to iterate on the model and data, or a form of HITL deployment so they get the benefit from these systems far sooner than before the models are perfect.
Human-in-the-loop training is the agile process for building machine learning
Rather than expecting things to progress smoothly and linearly, human-in-the-loop training takes an iterative approach to model building. It is analogous to the concepts of agile software development.
A working model is trained from the first bit of data. As more data is added, it is frequently updated. The model and the subject-matter experts work together to build, adapt and improve the model through annotating the data, or through a changing the task as the requirements and performance become clearer.
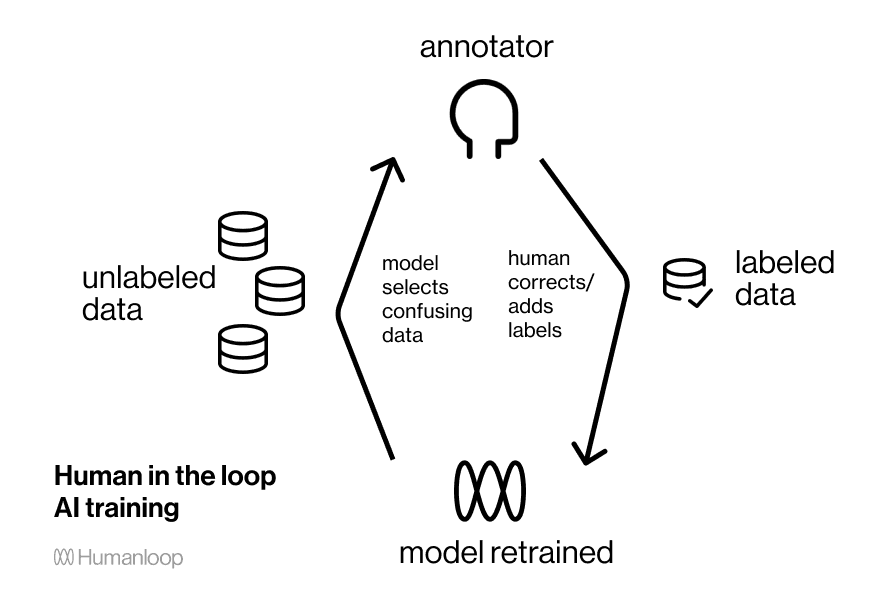
Active learning is a form of human-in-the loop training where the data to be annotated is selected by the model. By focusing on the most informative data you can drastically reduce the amount of labeled data needed but you also iterate on the task and model much faster.
There are many benefits to this dramatically quicker feedback cycle from human in the loop training:
Rapid model iteration.
You get real time feedback on how the model performs. You can then infer whether the task needs adapting, or where more data would be helpful.
Actionable feedback on how to improve the data quality.
Data is more impactful on end performance than the model in nearly all cases. The model can indicate where it thinks data has been mislabeled as part of a wider data debugging effort.
Up to a 10x reduction in data annotation requirements.
Through active learning the model can select the data points which are most informative, drastically reducing the amount of annotation needed.
Faster annotation.
By having a model in the loop you can also pre-annotate the data. Enabling a workflow where annotation becomes a quick confirm/reject decisions on the AI suggestions.
Combined, this makes a strong case to be a better way to train models. The biggest blocker to its adoption is that it's challenging to set up. Most annotation interfaces don't work alongside a trainable model and it takes considerable effort to make the training process fast enough for rapid feedback within the active learning loop. It's also hard to do active learning well. Simplistic model uncertainty-based data selection approaches can bias the model or tend to surface uninformative but noisy data points, which can do more damage than random selection.
A human-in-the-loop training platform should take these issues into consideration. With Humanloop, for example, there is diversity based sampling and confidence-calibrated models to make active learning work well. And there is a rapid bayesian model update to get immediate feedback while training deep learning models.
HITL deployment is where humans give feedback to help the model make predictions
Machine learning is really good at partially solving just about any problem. The problem lies in getting it to solve the complete problem.
Deep learning excels at unlocking the creation of impressive early demos of new applications using very little development resources.
— François Chollet (@fchollet) March 20, 2021
The part where it struggles is reaching the level of consistent usefulness and reliability required by production usage.
Efforts to improve suffer from diminishing returns. The real world is full of surprises and handling it requires the ability to adapt.
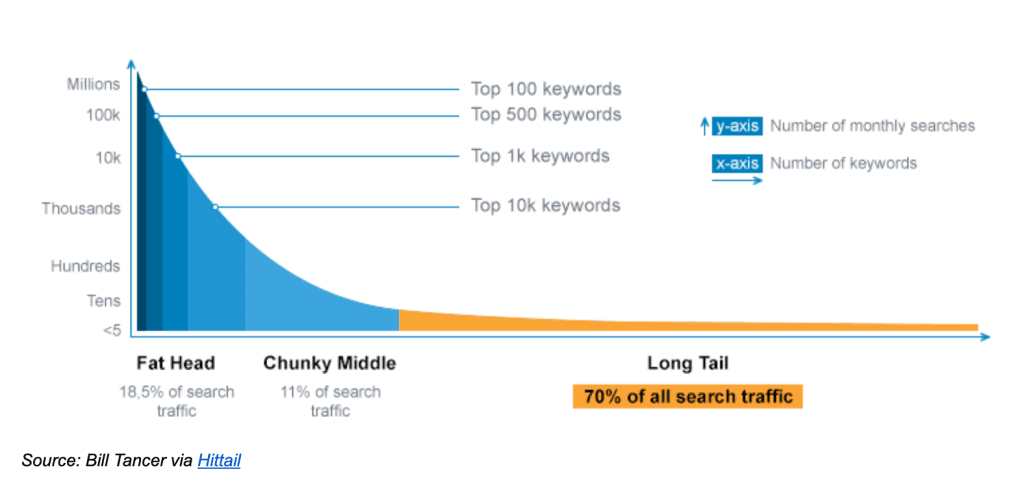
The long tail - here shown for search traffic – can make up the majority of the data. Performance on these individually-rare events can determine overall performance but it's hard to get enough training data to cover it all.
You could spend indefinite time, resources and money trying to label more data to improve the model performance until it reaches the required accuracy. Or, you could come up with a system design where perfect model performance is not required. It is this latter approach where HITL can be used.
To make a fault-tolerant UX you look for ways to make the overall system not depend on perfect model predictions, typically by getting the user to steer the AI system and form part of the feedback loop.
Alternatively, you can have a fallback mechanism such as a worker in the loop, who verifies the predictions when the model is unsure.
Users-in-the-loop is a fault tolerant UX for many AI systems
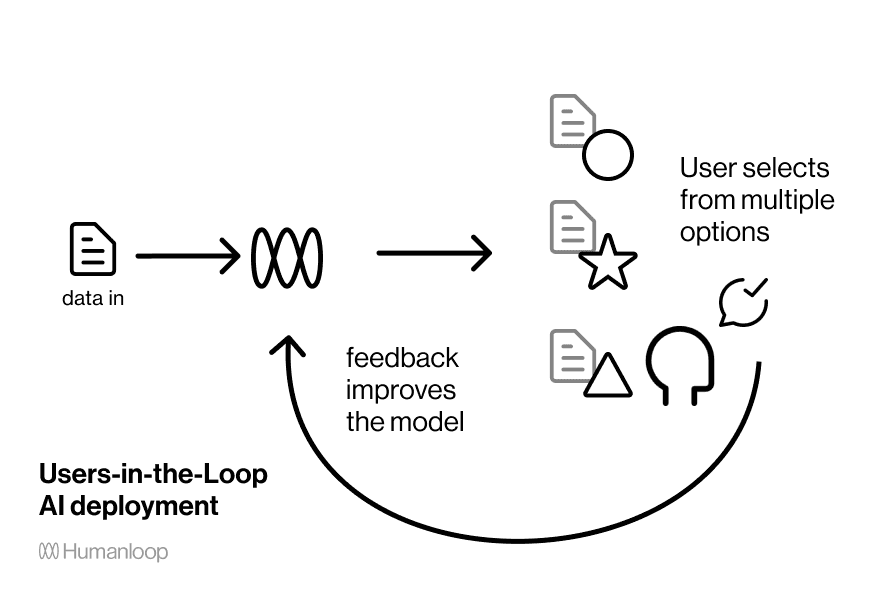
A user-in-the-loop system design puts more control into the hands of the user to make up for the shortcomings of the model's performance.
A solution to having an imperfect model is to make that matter less. This paradigm is everywhere when you start to see it. Recommendation systems show you a ranked list rather than the best choice and your choice improves the algorithm in the future. Google search itself is an example of this – it presents a page of links for you to choose between, rather than taking you straight to the first result. Gmail's Smart Reply is a fault tolerant UX – it doesn't expect to know the perfect response, but instead presents a few options for you to either select or dismiss.
Gmail's reply suggestions still leave something to be desired 😡 pic.twitter.com/bKW3f6xc7L
— Crescent Moon Games🌛 (@CM_Games) February 2, 2019
Gmail's smart reply is a user-in-the-loop system. The model makes three suggestions, which the user can use or ignore. The early prototype of auto replying with the first choice presumably got shut down by legal.
To make this work, the AI system should hand over some control to the user, and the system should record the response to help improve the model in future.
Workers-in-the-loop ensures high quality predictions that increasingly automate over time
Human-in-the-loop deployment is where you have a team of humans reviewing and correcting the predictions when the model is unsure.
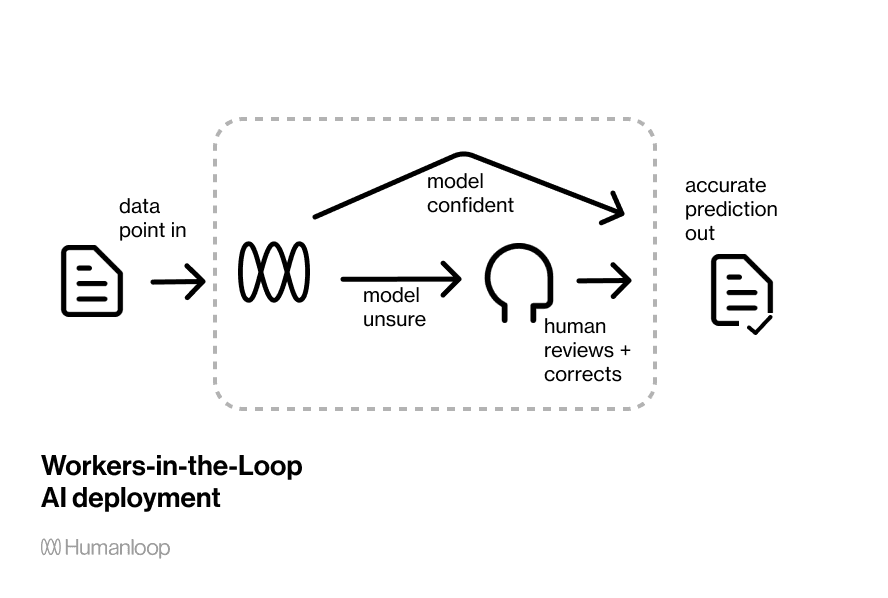
A worker-in-the-loop deployment allows a process to be automated gradually with with precise control over the quality of the results. You can specify the threshold of model confidence you require a human review step, and each intervention will improve the model over time.
A worker-in-the-loop deployment allows you to optimally tradeoff between quality, cost and speed, while automating a process.
Imagine you have a slider with 'speed' at one side and 'quality' at the other. Set it to 'speed' and you solely use the model's predictions, maximizing throughput and minimizing costs, but maybe the quality isn't so great. This is how many AI systems are architected at the moment. Set the slider to the other end, and you can transition to an entirely people-based operation. You can think of this structure as a wrapper around a human workflow. This guarantees human-level quality, but would be more expensive and far slower.
A worker-in-the-loop deployment platform allows you to set that slider wherever you see fit. This slider will set the threshold for model confidence, below which you fallback to a human team. The system will get better with every single intervention.
You can ensure the output is high quality. For most deployments, you want the bulk of data to be automatically processed. Only for rare data points do you want the fallback mechanism of human be used. Alternatively you can set the threshold very high to always have a review step. This can be required in mission-critical software such as medical diagnosis.
You can launch a working system immediately, and automate gradually over time. A purely human operated process is a high-cost service model. An automation strategy is needed if these things are to scale. Many startups start out with workers and scramble to transition to partial automation. This is why it makes sense to integrate HITL infrastructure from the start.
The same systems that make HITL training work, can also enable HITL deployment. You need machine learning models with well-calibrated uncertainty measures so you can rely on them to know when they don't know. Unfortunately most deep learning systems tend to be overly confident in their predictions which can lead to negative consequences.
How to use HITL AI
To conclude, HITL systems solve many of the problems of machine learning, from making to practically using the model. To learn how to include it in your system design you can read the excellent book on Human-in-the-loop Machine Learning. However, the simplest approach is to use an AI development platform built specifically for the HITL process.
Humanloop is an-all-in-one platform for natural language processing built around HITL concepts. We use active learning so you can rapidly train a model, and we enable you to set up a worker-in-the-loop deployment where the model knows when and how to fall back to someone in your team. We have years of experience building these systems at the largest AI companies such as Google and Amazon and have written books on the bayesian machine learning techniques that power this. We'd be delighted to show you a demo of how this can work for you.
Active learning - humans help train the model by labeling data the model is confused by.
Workers in the loop - including a human review step on the model's predictions?
Users in the loop - getting feedback from users on the model's predictions











