How to Improve GPT‑3 with Human Feedback
GPT‑3 is a game-changing technology that is ushering in a new era of how we work with computers. Developers can now integrate language-understanding AI in their applications with only a couple lines of code and some creative prompting.
However, the off-the-shelf GPT‑3 models can struggle with more specialized tasks that require domain knowledge, or a specific style. OpenAI have introduced the process of fine-tuning to help solve that.
Fine-tuning is where GPT‑3 is updated using a specific dataset. By doing this, you can eliminate long prompts – speeding your model up and reducing the cost – and get dramatically better performance on the task.
Before expanding on fine-tuning, let’s clarify how GPT‑3 is currently used.
Prompt engineering is not all you need
GPT‑3 is a Large Language Model (LLM) that has learnt from the Internet. When provided a prompt, it can generate a completion.
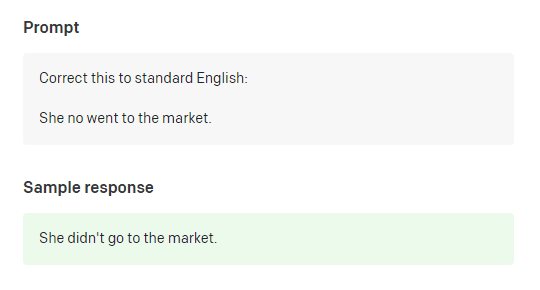
Grammar correction with GPT‑3. Example from OpenAI
To get GPT‑3 to achieve a specific task, the common practice is to manually select a few examples to show to the model and insert them into the prompt.
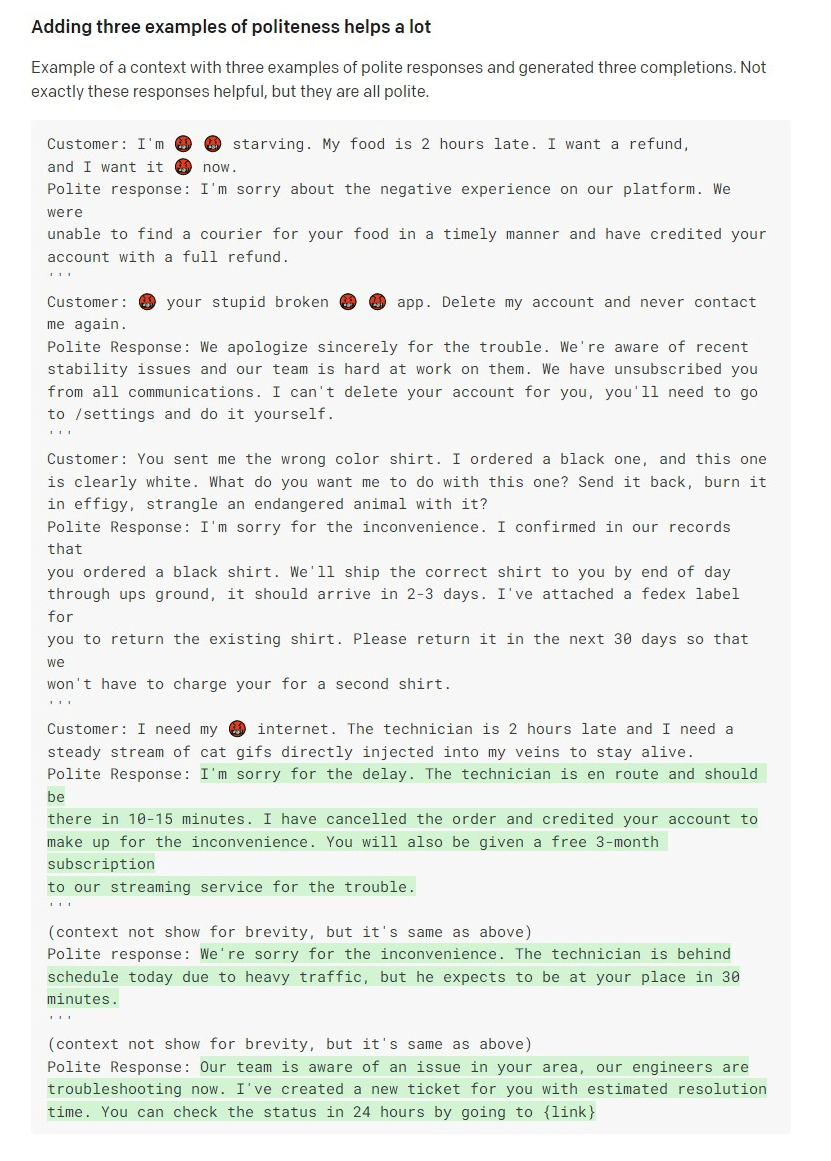
A prompt containing three examples from OpenAI’s docs. This is not feasible in many real-world cases. How do you choose which three examples to insert? What if they’re too long and don’t fit in the length limit?
Here, OpenAI advised to include three examples in the crafted prompt to steer GPT‑3 into being polite. If we consider real-world use cases, the limited number of examples you’re allowed to include in a prompt is often not enough – a different approach to model adaptation is required.
OpenAI has created an API for fine-tuning their models. By providing a collection of prompt/completion pairs and get a new custom version of GPT‑3 specific to your data.
Fine-tuning makes GPT-3 faster, cheaper, more reliable
By training a custom version of GPT‑3 on your data, you get a version that performs better for your use-case. Instead of cramming some carefully-selected examples into a prompt, a fine-tuned model uses all available examples to make a more informed decision. Additionally, a fine-tuned GPT‑3 model doesn’t need examples in the prompts anymore. This means you get significantly shorter inputs, saving cost and enabling lower-latency requests.
I need my 🤬 internet. The technician is 2 hours late and I need a
steady stream of cat gifs directly injected into my veins to stay alive.
##
I understand that internet is important to you. I'll have someone working
on this in the next 24 hours.
Fine-tuning promises to move us beyond the limitations of prompt engineering. In practice, things aren’t so straightforward.
Fine-tuning without a principled process leads to pitfalls
Before you start fine-tuning, there are a host of important questions to answer:
- What sort of data should I provide for fine-tuning?
- How do I collect this data?
- How much data do I need?
- What hyper-parameters should I set for fine-tuning? Number of epochs? Learning rate?
If you do successfully trigger fine-tuning you are then left with the tricky question of how do you evaluate whether your new GPT‑3 model is any good?
Get good results with a data-centric approach
It is clear from these challenges that one of the most important aspects of GPT‑3 fine-tuning (and subsequent evaluation) is access to high quality data.
This is why we believe developers should be taking a data-first approach to this problem.
Of particular importance for fine-tuning is curating feedback data. Feedback could be sourced directly from your users interacting with the GPT‑3 completions, or later by expert annotators.
GPT‑3 completions that receive positive feedback can be used for fine-tuning and those that received negative feedback can be corrected, improving the quality of the data and future models.
Humanloop helps you fine-tune GPT-3
Humanloop provides the infrastructure to collect your data and evaluate how GPT‑3 is performing. This acts as the foundation for GPT‑3 fine-tuning and evaluation with the following simple steps:
Easily collect your GPT-3 generations and feedback in one place
Humanloop provides a simple SDK for developers to log their data and provide feedback from their users. All the data is added to a Humanloop dataset.
log_id = humanloop.log(
prompt="Equation of gravity"
completion="F = G \frac{m_1 m_2}{r^2}"
)
humanloop.feedback(log_id, label="👍")
Curate and annotate your data for fine-tuning
Humanloop’s annotation interfaces with team support enable domain experts to explore the data, provide feedback and validate the feedback provided by users.
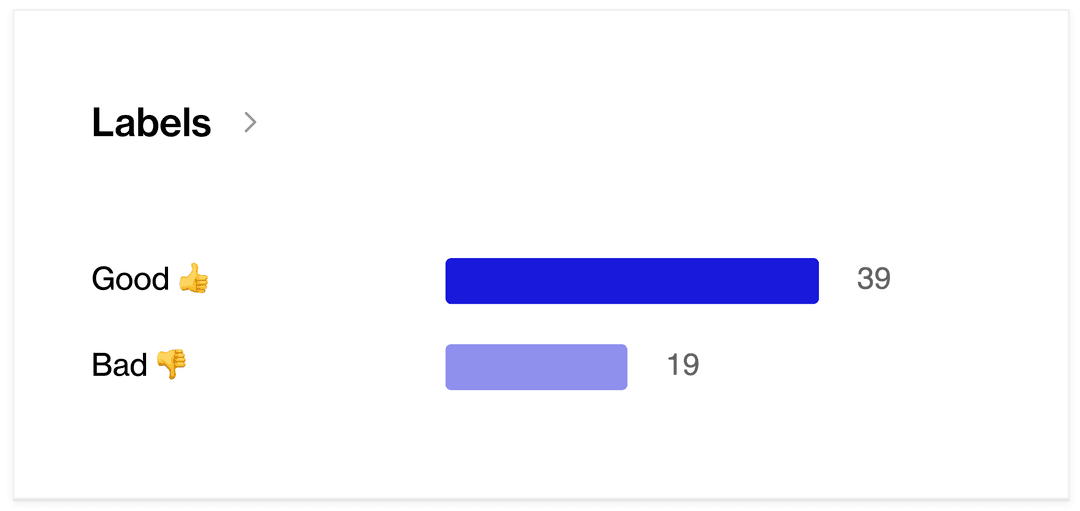
The Humanloop Annotation Platform enables you to collect feedback from your users and your team
The data export is optimized for OpenAI’s fine-tuning process to enable a seamless process.
humanloop export > openai api fine_tunes.create -m davinci
Evaluate your model against your users’ preferences
As feedback is added on Humanloop, in the background a model learns these human preferences – we call this a Preference Model. This model can monitor which completions your users see (helping to select better responses) and can help you evaluate whether a new prompt or fine-tuned version of GPT‑3 is better.
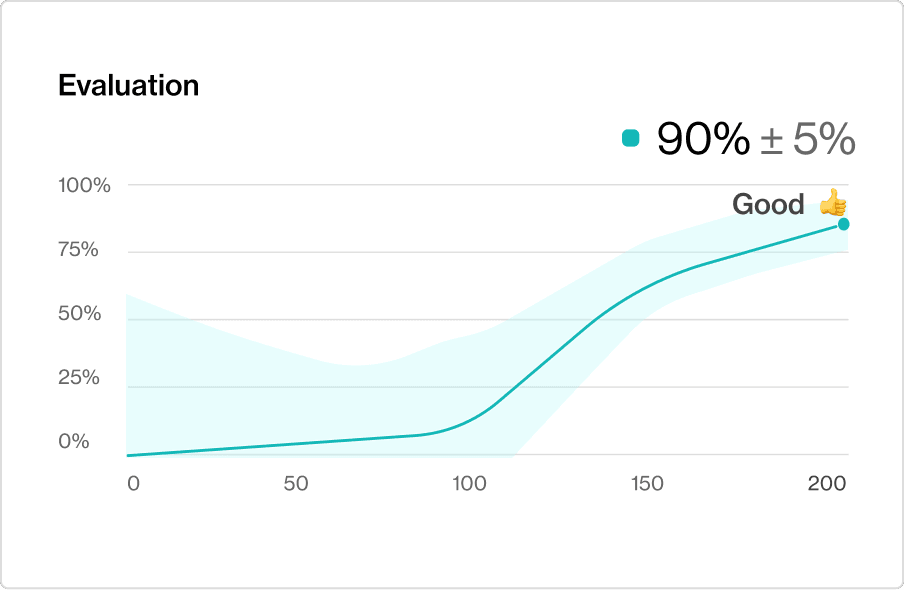
A Preference Model is trained to predict your user’s feedback on the GPT‑3 generations. You can use this to evaluate changes to the prompt or new fine-tuned versions.
With Humanloop’s best-in-class annotation tooling and easy model training, you can easily create a systematic process for improving GPT‑3 for challenging language tasks. This unlocks the value from your data that becomes your competitive advantage amongst peers leveraging this same technology.
Sign up for the closed beta
If you’re building with GPT‑3, we’d love to help you on your fine-tuning journey. Please fill out this quick form, or email us at gpt3@humanloop.com for access to the Humanloop platform for GPT‑3 fine-tuning.











