LLM Benchmarks: Understanding Language Model Performance
LLM Benchmarks: Your Guide to Evaluating Language Model Performance
Enterprises are rapidly adopting large language models (LLMs) to enhance their next generation of applications. Foundational models like GPT-4, Claude 3, and Gemini Ultra are versatile and non-deterministic, which makes evaluating their performance complex.
LLM benchmarks provide a standardized, rigorous framework for comparing the capabilities of LLMs across core language-related tasks. Understanding these benchmarks—and their criteria for assessing skills such as question answering, logical reasoning, and code generation—is crucial for making informed decisions when selecting and deploying LLMs.
In this blog, we will discuss how LLM benchmarks work, the most common
benchmarks used to compare leading models, the importance of evaluation metrics
and how these benchmarks help to choose the right LLM for an
application.
What Are LLM Benchmarks?
LLM benchmarks are collections of carefully designed tasks, questions, and
datasets that test the performance of language models in a standardized process.
Why are benchmarks so important? Benchmarks give us metrics to compare different
LLMs fairly. They tell us which model objectively does the job better. They also
show us the evolution of a single LLM as it learns and improves.
How Do LLM Benchmarks Work?
At their core, LLM benchmarks operate on a fairly straightforward principle: give the model a task, see how it does, and measure the results. However, there are nuances involved in ensuring reliable evaluation.
1. The Setup
The benchmark's creators carefully select tasks directly related to a chosen
aspect of language processing. This may involve generating summaries, continuing
a piece of creative writing, or writing code. A high-quality dataset is then
compiled. This might be a collection of questions with known answers, real-world
chat conversations, or even programming challenges.
The key is that this data must be unbiased and accurately represent how language
is used. The performance of the LLM is graded by choosing metrics like accuracy,
BLEU score, or perplexity(see more below), depending on the type of task.
Sometimes, human experts even get involved to assess nuances like creativity or
coherence.
2. Running the Test
There are a few ways to present a benchmark to an LLM:
- Zero-shot: The model is given the task with no prior examples or hints. This showcases its raw ability to understand and adapt to new situations.
- Few-shot: The LLM is given a few examples of how to complete the task before being asked to tackle similar ones. This reveals how well it can learn from a small amount of data.
- Fine-tuned: In this case, the LLM is specifically trained on data related to the benchmark task with the aim of maximizing its proficiency in that particular domain. If the fine-tuning is effective, it would demonstrate the model’s optimal performance in the task.
3. Making Sense of the Results
The chosen metrics calculate how well the LLM's output aligns with expected answers or 'gold standards’. This is the LLM's 'report card'. These results, whether consistently within a narrow range or displaying variability, offer insights into the model's reliability.
Distinguishing whether one LLM's superior performance over another stems from
mere luck or an actual disparity in skill is crucial. Therefore, upholding
strict statistical integrity is paramount. Given this context, it's vital to
specify whether a model is deployed in a zero-shot, few-shot, or fine-tuned
capacity for a particular task when benchmarking its performance against
competitors.
What Metrics Can Be Used for Comparing LLM Performance?
Before we explain the different benchmarks, it’s important to get an understanding of the common metrics used in these benchmarks and what they tell us:
- Accuracy: A cornerstone of many benchmarks, this is simply the percentage of answers the LLM gets fully correct.
- BLEU Score: Measures how closely the LLM's generated text aligns with human-written references. Important for tasks like translation and creative writing.
- Perplexity: How surprised or confused the LLM seems when faced with a task. Lower perplexity means better comprehension.
- Human Evaluation: SBenchmarks are powerful, but sometimes nuanced tasks call for the expert judgement of LLM output in terms of quality, relevance, or coherence.
No single metric tells the whole story. When choosing an LLM or working to
maximise LLM performance, it's
vital to consider which metrics align with your specific goals.
Types of LLM Benchmarks
Language is complex, which means there needs to be a variety of tests to figure out how truly capable LLMs are. Here is a selection of some of the most common benchmarks used in assessing the performance of LLMs in prevalent applications of AI, how they work and why they’re useful.
LLM Benchmarks for Chatbot Assistance
Chatbots are one of the most popular real-world applications of LLMs. Benchmarks
tailored to chatbots focus on two key areas: conversational fluency and
goal-oriented success.
- ChatBot Arena: A crowdsourced platform where LLMs have randomised conversations rated by human users based on factors like fluency, helpfulness, and consistency. Users have real conversations with two anonymous chatbots, voting on which response is superior. This approach aligns with how LLMs are used in the real world, giving us insights into which models truly excel in conversation.
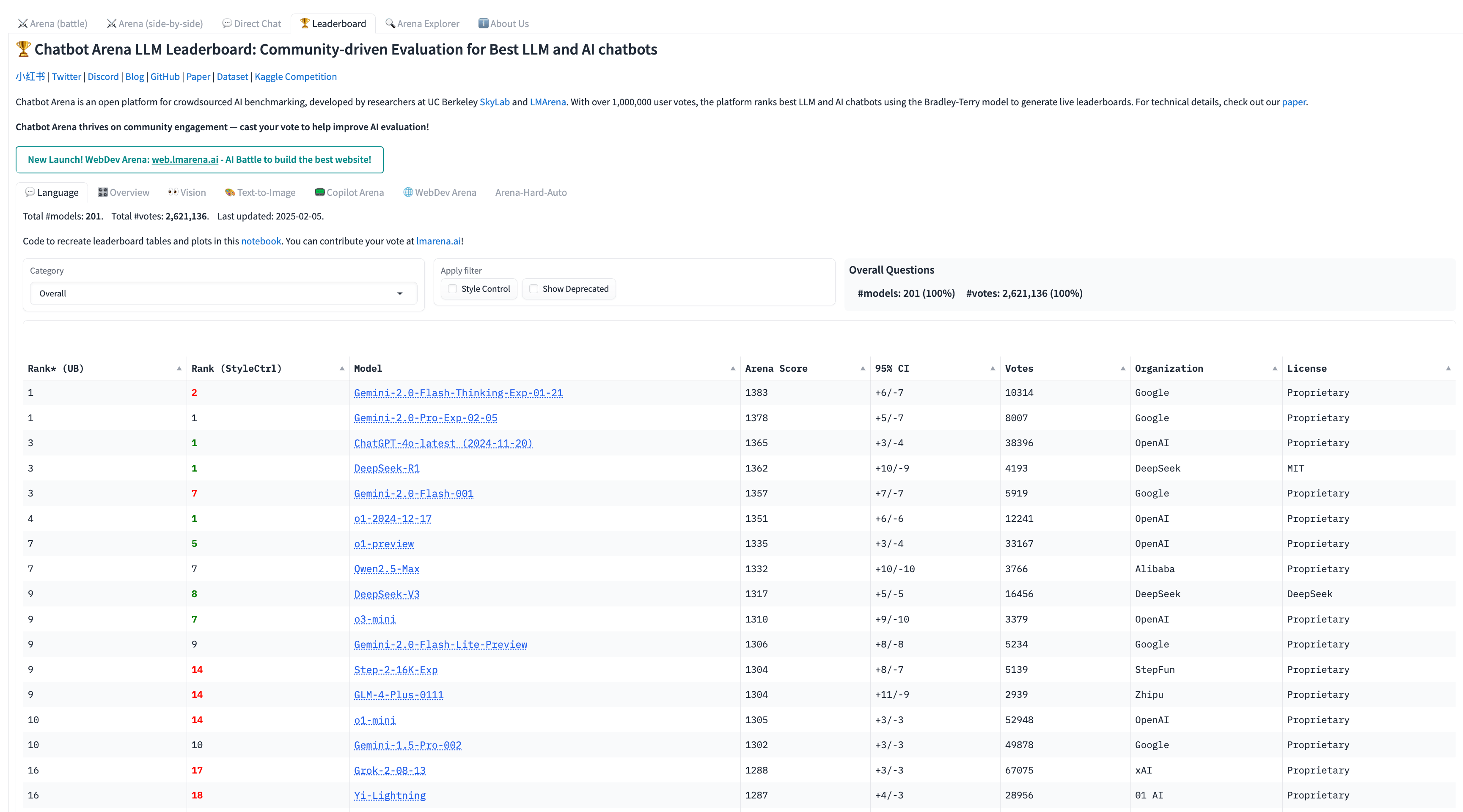
- MT Bench: A dataset of
challenging questions designed for multi-turn conversations. LLMs are graded
(often by other, even more powerful LLMs) on the quality and relevance of
their answers. The focus here is less about casual chat and more about a
chatbot's ability to provide informative responses in potentially complex
scenarios.
LLM Benchmarks for Question Answering and Language Understanding
These benchmarks aim to assess if an LLM truly "gets" the nuances of language, whether it's finding specific information or demonstrating broader comprehension. Here are some key players:
- MMLU (Massive Multitask Language Understanding): A wide-ranging benchmark suite designed to push LLMs beyond the basics. It features over 15,000 questions across 57 diverse tasks, spanning STEM subjects, humanities, and other areas of knowledge. MMLU aims for a comprehensive evaluation. Questions go beyond simple factual recall – they require reasoning, problem-solving, and an ability to understand specialised topics.
- GLUE &
SuperGLUE: GLUE (General Language
Understanding Evaluation) was an early but groundbreaking benchmark suite.
SuperGLUE emerged as a response to LLMs quickly outperforming the original
GLUE tasks. These benchmarks include tasks like:
- Natural Language Inference: Does one sentence imply another?
- Sentiment Analysis: Is the attitude in a piece of text positive or negative?
- Coreference Resolution: Identifying which words in a text refer to the same
thing.
LLM Benchmarks for Reasoning
When LLMs generate impressive text or answer questions, it's tempting to attribute this to genuine "understanding". But are they truly reasoning, or just masters of imitation? Benchmarks designed specifically for reasoning skills aim to answer that question.
-
ARC (AI2 Reasoning Challenge): ARC confronts LLMs with a collection of complex, multi-part science questions (grade-school level). LLMs need to apply scientific knowledge, understand cause-and-effect relationships, and solve problems step-by-step to successfully tackle these challenges.
Split into an “Easy Set” and a “Challenge Set”, ARC helps us see if a model is going beyond pattern matching and showcasing true logical reasoning capabilities.
-
HellaSwag: An acronym for “Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations”, this benchmark focuses on commonsense reasoning. To really challenge LLMs, the benchmark includes deceptively realistic wrong answers generated by "Adversarial Filtering," making the task harder for models that over-rely on word probabilities.
The LLM is presented with a sentence and multiple possible endings. Its task is to choose the most logical and plausible continuation. Picking the right ending requires having an intuitive understanding of how the world generally works – if I drop a glass, it likely breaks, it wouldn’t do something like sprout wings. HellaSwag tests if an LLM possesses this type of general knowledge.
LLM Benchmarks for Coding
Coding benchmarks rigorously test whether LLM-generated code actually accomplishes the task at hand. Here are a few that push LLMs to their limits:
- HumanEval: HumanEval moves past simple text comparisons and focuses instead on whether the LLM's generated code actually works as intended. It presents models with carefully crafted programming problems and evaluates whether their solutions pass a series of hidden test cases. HumanEval spotlights those LLMs that can truly problem-solve, not just imitate code they've seen before.
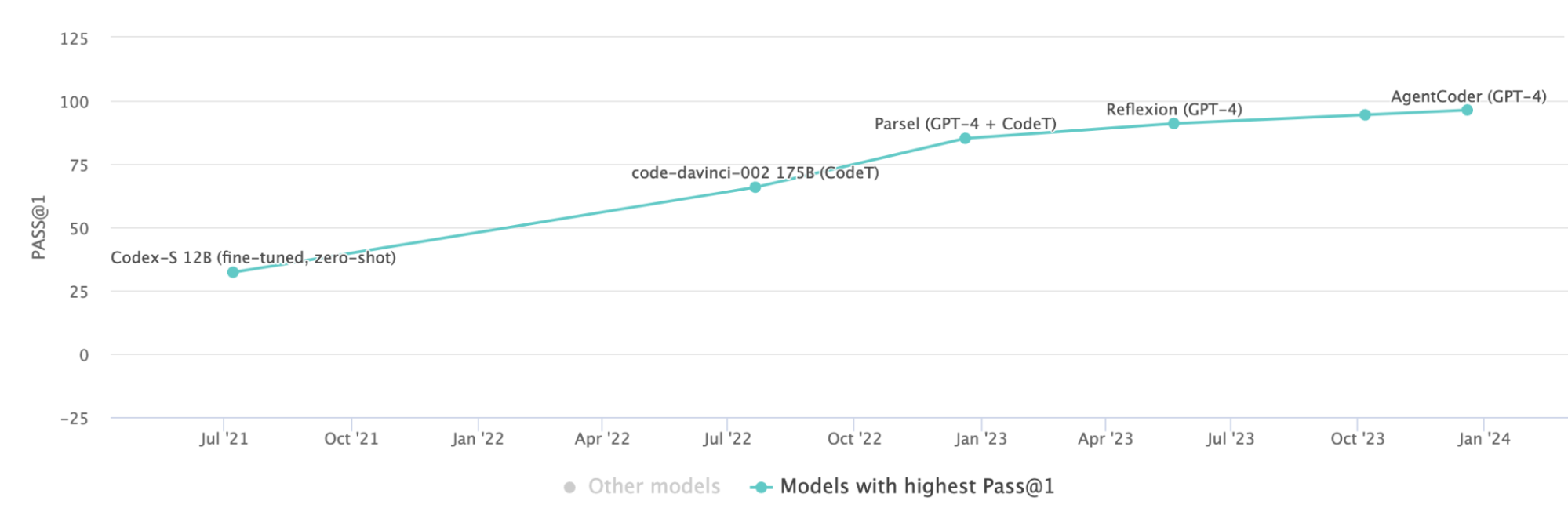
-
MBPP: AShort for “Mostly Basic Python Programming'', MBPP is a vast dataset of 1,000 Python coding problems designed for beginner-level programmers. This benchmark tests an LLM's grasp of core programming concepts and its ability to translate instructions into functional code. MBPP problems comprise three integral components: task descriptions, correct code solutions, and test cases to verify the LLM's output.
-
SWE-bench: Short for “Software Engineering Benchmark”, SWE-bench is a comprehensive benchmark designed to evaluate LLMs on their ability to tackle real-world software issues sourced from GitHub. This benchmark tests an LLM's proficiency in understanding and resolving software problems by requiring it to generate patches for issues described in the context of actual codebases. Notably, SWE-bench was used to compare the performance of Devin, the AI Software Engineer, with that of assisted foundational LLMs.
LLM Benchmarks for Math
Mathematical reasoning presents a unique challenge for large language models, requiring not just pattern recognition but deep symbolic manipulation and step-by-step logical deduction. Math benchmarks test these very capabilities, each targeting different aspects of mathematical expertise.
-
MATH: The MATH dataset, developed by Hendrycks et al. (2021), is a comprehensive benchmark featuring 12,500 problems derived from high-school-level math competitions. These problems encompass a wide array of mathematical topics, including algebra, geometry, calculus, and combinatorics. Unlike simpler datasets, MATH emphasizes the importance of structured reasoning by requiring solutions to demonstrate the full derivation process, not just final answers.
LLMs like GPT-4 have achieved notable success on this benchmark, with scores reaching around 80% when advanced prompting techniques are applied. However, even state-of-the-art LLMs often fail on more intricate problems, particularly those involving multiple steps or abstract concepts.
-
MathOdyssey: The MathOdyssey dataset (2024) introduces a new level of complexity in evaluating LLM mathematical reasoning. Designed collaboratively by educators, researchers, and mathematicians, it contains 387 rigorously curated problems spanning high school, university-level, and Olympiad-level mathematics. The dataset addresses several limitations of prior benchmarks:
- Originality and Fairness: Unlike MATH, whose problems may overlap with training data, MathOdyssey ensures originality by incorporating novel questions crafted specifically for benchmarking purposes.
- Diverse Topics: Problems span algebra, number theory, combinatorics, calculus, differential equations, and more. This wide coverage ensures that models are tested on both breadth and depth of mathematical knowledge.
- Tiered Difficulty: MathOdyssey challenges LLMs at three levels—high school,
university, and Olympiad—progressively increasing in complexity. This design
ensures models are tested across a spectrum of mathematical reasoning
abilities, from foundational concepts to advanced problem-solving.
Tool Use Benchmarks
Evaluating a large language model's (LLM) proficiency in utilizing external tools is crucial for understanding its practical applicability in real-world scenarios. Several benchmarks have been developed to assess these capabilities, focusing on aspects such as API interaction, tool selection, and execution planning.
- API-Bank: API-Bank is a benchmark
designed to evaluate LLMs' abilities to interact with external APIs
effectively. It comprises 73 API tools across various domains, including
search engines, calendars, smart home controls, and hotel reservations. The
benchmark includes 314 annotated tool-use dialogues with 753 API calls,
assessing models on:
- Planning: Determining whether an API call is necessary for a given task.
- Retrieval: Identifying the appropriate API from a pool of options.
- Execution: Accurately calling the API with correct parameters.
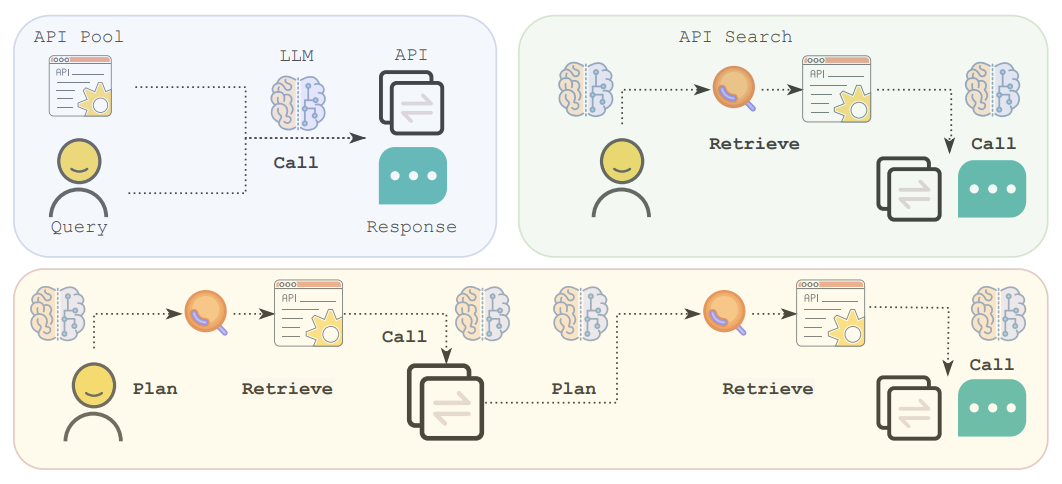
- ToolLLM: The ToolLLM framework,
introduced in 2024, marks a significant advancement in tool-use benchmarking
by focusing on real-world API interactions. It includes the ToolBench Dataset,
comprising over 16,000 APIs across 49 categories, sourced from platforms like
RapidAPI. This dataset is notable for its:
- Diversity of scenarios: Single-tool, multi-tool, and interdependent tool use cases.
- Solution path annotation: Multi-step reasoning paths annotated with a depth-first search decision tree (DFSDT), enabling robust evaluation of reasoning abilities.
- Generalization tests: Models like ToolLLaMA demonstrate strong performance
on out-of-distribution tasks, achieving comparable results to closed-source
models like ChatGPT.
MultiModality Benchmarks
Multimodality benchmarks evaluate the ability of large language models (LLMs) to process and reason across multiple types of data, such as text, images, audio, and video. These benchmarks are vital for testing the integration of linguistic understanding with visual, auditory, or other sensory inputs, mimicking human-like multi-sensory reasoning.
-
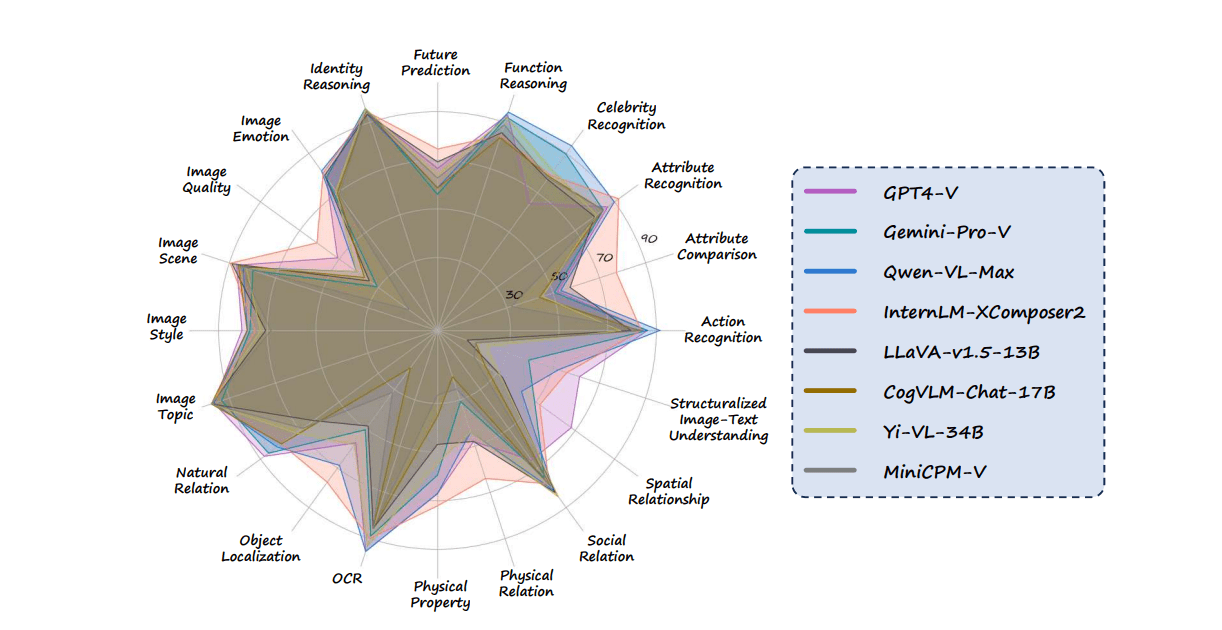
Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU): MMMU is a comprehensive benchmark designed to assess multimodal models on tasks that require college-level subject knowledge and deliberate reasoning. It comprises 11,500 meticulously curated multimodal questions sourced from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Technology & Engineering. These questions span 30 subjects and 183 subfields, featuring 30 highly heterogeneous image types, including charts, diagrams, maps, tables, music sheets, and chemical structures.
Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Even advanced models like GPT-4V and Gemini Ultra achieve accuracies of only 56% and 59%, respectively, indicating significant room for improvement.
-
MMBench: A rigorous evaluation framework that spans multiple domains and data formats, this benchmark emphasizes not only the ability to process individual modalities but also the nuanced integration of diverse inputs like text, images, and charts. MMBench introduces progressively challenging tasks, from straightforward visual recognition to sophisticated data fusion problems where text and visuals must work in tandem to generate meaningful outputs. A unique aspect of MMBench is its focus on dynamic, real-time interactions, such as describing an evolving visual trend or answering context-driven questions. Despite advancements, even top-performing models like GPT-4V occasionally falter when faced with complex, context-heavy visual reasoning tasks, highlighting areas where multimodal alignment remains incomplete.
Multilingual Benchmarks
Multilingual benchmarks evaluate large language models (LLMs) on their ability to process, understand, and generate text across multiple languages. These benchmarks play a critical role in testing linguistic diversity and ensuring equitable performance across languages beyond English, addressing biases that often arise in training datasets predominantly composed of English-language content.
The FLORES-101 Evaluation Benchmark: for Low-Resource and Multilingual Machine Translation focuses on testing LLMs' translation quality across low-resource languages. By including languages like Sinhala, Nepali, and Pashto, FloRes addresses the critical gap in benchmarks tailored for languages with minimal digital representation. This benchmark evaluates both forward translations (e.g., Sinhala to English) and backward translations (e.g., English to Sinhala), providing a bidirectional view of a model's multilingual translation capabilities.
A standout feature of FloRes is its incorporation of human evaluation baselines,
ensuring that benchmark scores remain grounded in real-world linguistic
expectations. Results consistently show that while models like GPT-4 and Google
Translate perform strongly on high-resource language pairs, low-resource pairs
still pose substantial challenges, particularly in idiomatic or culturally
nuanced translations.
Benefits and Challenges of LLM Benchmarks
Benefits of LLM Benchmarks
-
Informed Decision-Making
For business owners or product leaders evaluating LLMs for their offerings, benchmarks provide a concrete, data-driven foundation for decision-making. Instead of relying on marketing claims or generic model descriptions, benchmarks offer objective performance comparisons across tasks relevant to your business.
-
Customization Insights for Better ROI
Benchmarks can offer insights into areas requiring fine-tuning; For example, benchmarks can reveal if a model struggles with domain-specific terminology or task complexity. This clarity enables targeted customization, maximizing your return on investment by ensuring the deployed LLM delivers tailored, high-quality outcomes.
-
Accelerated Compliance and Risk Management
In regulated industries like healthcare, finance, or legal services, benchmarks often include metrics for fairness, bias, and reliability. Using these as a baseline, businesses can ensure compliance with ethical and legal standards, reducing operational risks.
-
Scaling Globally with Confidence
For companies with international reach, multilingual and multimodal benchmarks provide a roadmap to deploying LLMs that perform well across diverse languages. By leveraging benchmark insights, businesses can expand into new markets, offering culturally and linguistically appropriate solutions that resonate with local audiences.
Challenges of LLM Benchmarks
-
Narrow Task Representation
LLM benchmarks often generalize tasks to evaluate broad model performance. However, for business owners looking to solve specific problems—such as domain-specific language processing in finance or healthcare—benchmarks may fail to capture the nuances of these specialized requirements. This misalignment can lead to overestimating a model's real-world applicability.
-
Risk of Overfitting
When models are trained or fine-tuned on datasets resembling benchmark tasks, they may excel in scoring but perform poorly in dynamic, real-world scenarios. For businesses, this creates a false sense of confidence in the model's capabilities, potentially resulting in underwhelming performance when deployed.
-
Evolving Metrics and Standards
Benchmarks represent a snapshot in time, testing against current challenges. As models improve and new applications emerge, benchmarks risk becoming outdated. For businesses, this means relying on benchmarks that may no longer be relevant to evolving market demands or customer needs.
-
Difficulty in Measuring Human-Like Capabilities
While benchmarks can test precision, recall, or reasoning, they struggle to capture qualitative aspects of LLM behavior, such as emotional intelligence or adaptability in ambiguous situations. These qualities are often critical for customer-facing products like chatbots, yet benchmarks fall short of measuring their effectiveness.
The Future of LLM Benchmarks
As large language models continue to evolve, so too must the benchmarks that evaluate them. The future of LLM benchmarks lies in pushing beyond static datasets and rigid scoring systems to embrace more dynamic, real-world scenarios that reflect the complexities of human interaction and decision-making. Benchmarks will likely prioritize adaptability, testing models on emerging tasks such as ethical reasoning, cultural context understanding, and proactive problem-solving. Multimodal and multilingual benchmarks must expand their scope, incorporating underrepresented languages and modalities to ensure inclusivity and fairness. Additionally, as businesses increasingly integrate LLMs into their operations, benchmarks may evolve to measure not just raw model performance but also their real-world impact on user satisfaction, efficiency, and innovation.
Get More Advice on LLM Benchmarks
Humanloop makes it easy to evaluate the performance of LLM applications. We provide enterprises with generative-AI native tooling for testing, measuring and improving applications built on models like GPT-4, Claude 3 and Gemini Ultra.
Using our evaluation features, teams can develop custom benchmarks and perform manual (human expert) or automated (code or LLM-based) evaluation runs to ensure the performance of their models is optimized for production. Book a demo with our team, who have expertise in LLM Evaluations, to learn more.
About the author

- 𝕏@conorkellyai










