LLM Guardrails
LLM Guardrails
How can you make sure your AI application isn’t going to do something you don’t want it to do? How do enterprises ensure reliable model performance in high-stake applications?
Large language models (LLMs) are non-deterministic, meaning the same input can give you a different output each time you generate a completion. This can lead to unintended consequences such as data leakage, harmful or biased responses, or output that has no relation to a user’s query. LLM guardrails are designed to mitigate these risks by aligning model behaviour with intended use, preventing them from generating undesired output.
In this guide, we’ll explore the different types of LLM guardrails, their importance, and best practices for their implementation.
What are LLM Guardrails
LLM guardrails are structured frameworks and mechanisms designed to monitor, direct, and enhance the behaviour of large language models within enterprise environments. They serve as a quality control layer, ensuring that AI outputs align with a company’s ethical, operational, and regulatory standards while preventing potential risks. As LLMs can produce a vast range of responses, guardrails shape the boundaries of their output, enforcing a certain degree of security and reliability.
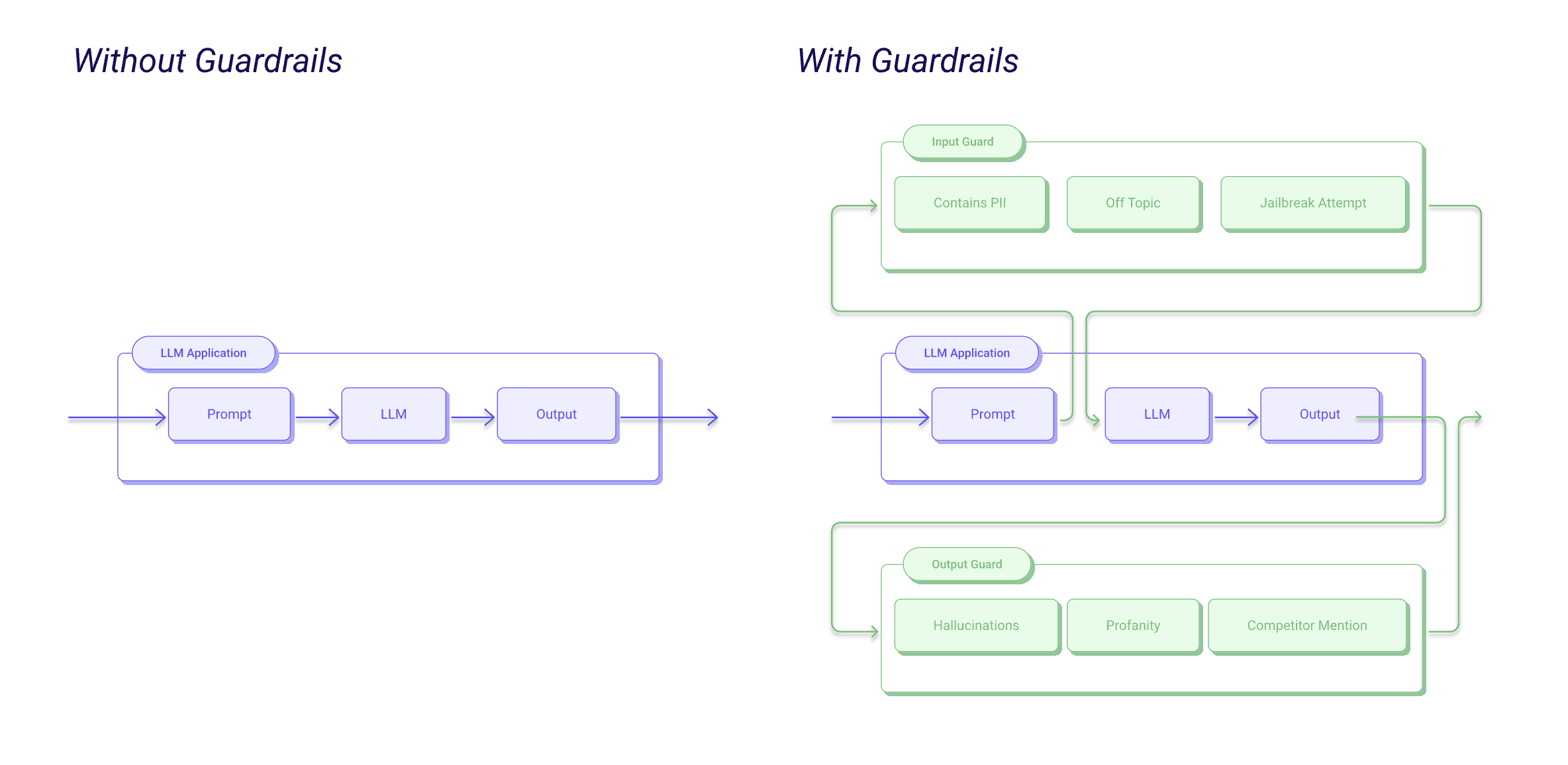
Guardrails work to ensure LLM outputs remain accurate, secure, and contextually appropriate. In high-stakes applications—such as healthcare, finance, or customer support—errors can lead to more than just operational inefficiency; they can risk data security, compliance, and brand reputation. Guardrails allow enterprises to instill trust in their AI systems by embedding oversight that can dynamically respond to evolving user interactions, whether it’s restricting sensitive information exposure or adapting responses to changing regulatory requirements.
Why are Guardrails for LLMs important?
Guardrails for LLMs are essential to ensure these models operate securely, responsibly, and in line with business objectives. By implementing strong guardrails, enterprises can leverage LLMs while mitigating the risks associated with stochastic models and maintaining user confidence.
Security
In any LLM deployment, particularly in enterprise, security guardrails are indispensable. Security-focused guardrails are designed to prevent risks like data leakage or prompt injection attacks by ensuring that the model only accesses approved data sources and adheres to strict access controls. For instance, enterprises must protect customer information in customer service interactions and prevent accidental disclosure of proprietary or sensitive information. Without these guardrails, enterprises risk exposing themselves and their users to data breaches, regulatory penalties, and reputational harm.
Information and Evidence
For any enterprise deploying LLMs, the reliability and factual accuracy of model outputs are critical. Information-focused guardrails help maintain quality by ensuring that the model’s responses align with verified data sources, reducing the risk of “hallucinations” (outputs that are factually incorrect or misleading). These guardrails validate that the AI outputs are consistent with the organisation’s informational standards and evidence-based practices. Such measures build user trust and ensure compliance, especially in regulated sectors like healthcare and finance, where misinformation can lead to costly errors and compromised safety standards.
Ethics and Safety
Ethical and safety guardrails address biases and unintended harmful outputs that might arise from LLMs trained on diverse and sometimes unfiltered datasets. These guardrails set strict parameters around language, tone, and inclusivity, minimising the risk of biased or harmful interactions. For instance, in a customer service model, ethical guardrails ensure the AI avoids biased responses and upholds fair, respectful communication across diverse user demographics. Implementing these safeguards promotes user safety, builds public trust, and aligns AI outputs with an organization’s commitment to inclusivity and ethical standards.
What are the different types of AI Guardrails?
Compliance Guardrails
Compliance guardrails focus on aligning LLM outputs with industry regulations and legal standards. In sectors like healthcare and finance, where data privacy laws like GDPR are stringent, compliance guardrails help ensure that the model’s behaviour meets regulatory expectations, especially regarding user data protection and privacy. This minimises legal risks and supports trustworthiness in regulated environments.
Contextual Guardrails
Contextual guardrails refine the model’s output to be contextually relevant, adjusting responses to align with the user’s intent and specific application settings. They help prevent situations where the model might generate technically accurate but contextually inappropriate information, enhancing relevance in fields like customer service or specialised technical support.
Adaptive Guardrails
Adaptive guardrails offer dynamic adjustments to the model’s behaviour based on ongoing interactions and emerging threats. These guardrails continuously learn from user inputs and adjust the model’s boundaries, ensuring that LLMs stay aligned with both ethical standards and evolving user needs. This adaptability is particularly valuable in applications requiring flexibility, such as real-time monitoring and response adjustment.
Best practices for Implementing LLM Guardrails
Establish Customized Model Constraints
One of the most effective ways to implement guardrails is by tailoring constraints specific to the enterprise’s needs and industry requirements. For example, a healthcare-focused LLM may need strict guidelines around patient data privacy and medical ethics. By establishing and enforcing these unique constraints through model training and rule-based adjustments, organizations can maximize LLM performance and ensure that their LLM aligns closely with internal policies and external regulations. This approach helps avoid generalization, where models operate broadly rather than focusing on precise industry nuances, thereby enhancing both relevance and compliance.
Conduct Red Teaming and Regular Vulnerability Assessments
Red teaming involves using internal or external experts to actively test the model’s defences, searching for potential security vulnerabilities and misbehaviour. This method helps identify weak spots where the model may fail, such as susceptibility to prompt injection or manipulation. Regular vulnerability assessments, including adversarial testing, allow teams to understand the model’s limitations and proactively address them. This practice is essential for high-stakes applications where undetected flaws could lead to significant risks.
Implement Continuous Monitoring and Real-Time Auditing
LLM monitoring tools like Humanloop and real-time auditing mechanisms allow for live oversight of LLM outputs. These tools can flag outputs that might be inappropriate, biased, or factually incorrect, enabling rapid intervention. For example, organizations can deploy monitoring algorithms that automatically flag harmful or misaligned content, allowing human oversight to step in when necessary. Real-time feedback systems are invaluable in applications with public or high-frequency interactions, where consistent quality control is crucial for maintaining user trust and operational efficiency.
Integrate a Feedback Loop for Continuous Improvement
Establishing a feedback loop from users, moderators, and other stakeholders enables ongoing refinement of the LLM. User feedback helps identify problematic outputs in diverse real-world scenarios, informing adjustments to the model. This iterative process encourages gradual improvements and adaptability, allowing the LLM to evolve in response to changing user needs or emerging issues. A well-integrated feedback loop contributes to both adaptive guardrails and an LLM that is continually refined for accuracy and alignment with enterprise objectives.
Learn more about LLM Guardrails
Humanloop is the LLM evals platform for enterprises. Teams at Gusto, Vanta, and Duolingo use Humanloop to develop guardrails for LLMs so they can ship reliable AI products. We enable you to adopt best practices for prompt management, evaluation, and observability, which are core pillars for developing guardrails that work at scale. To learn more, book a demo today.
About the author

- 𝕏@conorkellyai










