What is LLM Observability and Monitoring?
LLM Monitoring and Observability
How do you ensure your LLMs perform as intended, especially when they're interacting with thousands of users at scale? How do you proactively catch potential issues like degraded performance, harmful outputs, or embarrassing mistakes before they impact your users?
This is where LLM monitoring and observability come in. While monitoring focuses on continuously measuring the performance of your AI applications, observability takes things a step further. Observability delves deeper into the why behind your model’s behavior, offering richer insights for debugging and optimization. Together, they form the foundation for maintaining high-quality, reliable AI systems.
We’ll break down what LLM monitoring and observability are, why they’re crucial, and the best practices and metrics you should know to keep your AI applications running smoothly, even at scale.
What is LLM Monitoring and Observability?
LLM monitoring is the ongoing process of observing and analyzing the performance of a large language model (LLM) once it is deployed in production environments. It’s akin to having a watchful eye on a complex machine, ensuring it operates efficiently and produces the desired outcomes. Monitoring allows for real-time tracking of model performance and flags when something isn’t working as expected.
Meanwhile, LLM observability goes deeper than traditional monitoring. Observability is the ability to understand why an LLM behaves a certain way by collecting, analyzing, and interpreting detailed logs, traces, and metrics. It provides a more holistic view of the system by allowing for better debugging, optimization, and performance tuning.
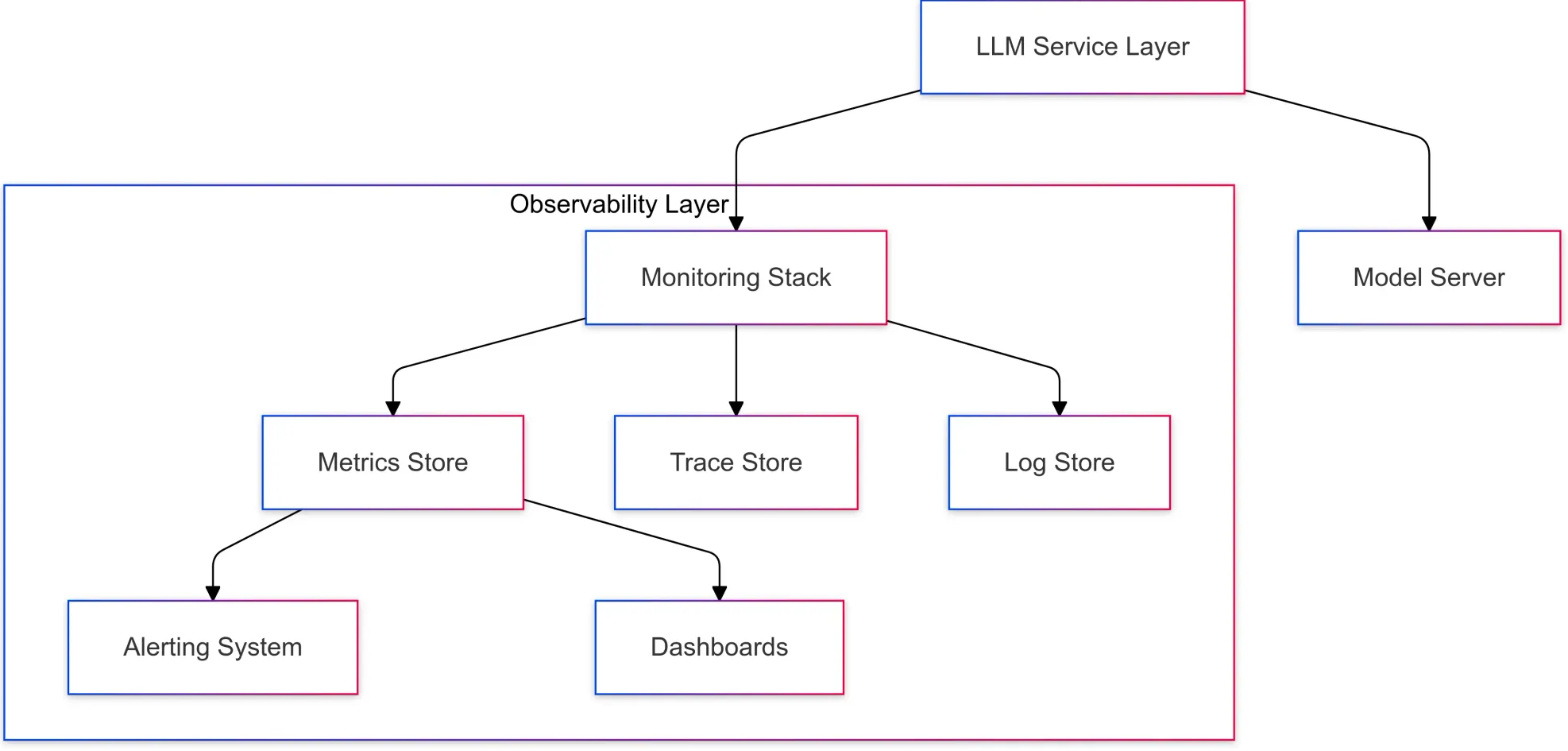
While monitoring alerts you to what is happening, observability helps uncover the underlying causes. Both monitoring and observability ensure reliability and performance of AI systems. In addition, they are used together for proactive and reactive optimization.
To implement an effective LLM monitoring and observability stack, focus on these pillars:
- Model performance: Tracking metrics like accuracy, latency, and response time to assess the model's effectiveness.
- Data quality: Evaluating the quality and relevance of the data used to train and tune the model.
- Bias detection: Identifying and mitigating biases in the model's outputs to ensure fairness.
- System performance: Monitoring the underlying infrastructure and resources to prevent bottlenecks.
- User experience: Gathering feedback on user interactions to improve the model's usability.
By systematically tracking these areas, organizations can identify potential issues early, prevent service disruptions, and continually improve LLM performance. Observability lets teams not only identify problems but also understand and resolve them more effectively, creating a more stable foundation for deploying AI at scale.
Why is LLM Monitoring and Observability Important?
Deploying an LLM into the real world is not without its risks. Despite their sophistication, LLMs have underlying uncertainties and vulnerabilities that can lead to unpredictable behavior, performance issues, or even compliance breaches. Monitoring and observability play a crucial role in mitigating these risks by continuously tracking and understanding how models behave in production.
While LLM monitoring focuses on tracking key metrics and performance indicators to detect when something is going wrong, LLM observability goes further by providing the tools and insights to understand exactly why these issues occur. Combined, they let teams maintain control, reliability, and trust in their AI systems.
Some key reasons as to why both LLM monitoring and observability are important include:
Reputational Risk
LLMs have the potential to generate unexpected, harmful, or inappropriate outputs. Without monitoring and observability, these issues can go unnoticed and lead to brand-damaging situations.
For example, an LLM tasked with generating creative marketing content might inadvertently produce offensive or biased text, putting the company’s reputation at risk. Monitoring tools catch such instances in real-time, while observability solutions enable teams to trace back the root cause of the issue, such as problematic training data or specific prompt weaknesses.
Performance Degradation
Over time, LLMs can experience prompt drift, where their responses deviate from the expected outputs due to changes in underlying data, evolving prompts, or even updates to the model itself.
This can drastically affect performance - especially in dynamic environments where prompt structures or user inputs evolve rapidly. For instance, if you’re relying on a model alias (such as GPT-4o), which automatically updates to the latest version of the model, subtle differences in the new model may cause the LLM’s quality of responses to degrade.
Monitoring helps detect these irregular patterns early, while observability helps diagnose why the model behavior changed, whether due to infrastructure updates, changes in input patterns, or differences in model versions.
Compliance Breaches
Monitoring ensures that the data processed by the LLMs is handled correctly and in compliance with regulatory standards. Without comprehensive monitoring and observability, enterprises risk data mishandling or non-compliance with standards like the GDPR or the EU AI Act.
For example, monitoring ensures that key performance metrics for data handling and model outputs align with regulatory requirements. Observability, on the other hand, provides traceability. This lets teams log, audit, and explain how inputs were processed and decisions were made. This level of transparency is important to follow laws and avoid devastating data breaches or penalties.
By integrating both monitoring and observability into their workflows, teams can proactively address these risks, maintain control over their systems, and build trust with users. Monitoring alerts teams to immediate issues, while observability empowers them to resolve problems faster by understanding the deeper causes. Together, they provide a comprehensive and sustainable strategy to manage LLMs in real-world environments.
Benefits of LLM Monitoring and Observability
Benefits of LLM monitoring and observability include:
- Proactive Issue Detection: By combining monitoring with observability, teams can quickly identify and address potential problems like performance degradations, harmful outputs, or system bottlenecks before they impact end users.
- Improved Model Performance: Regularly tracking metrics such as response accuracy, latency, and bias ensures that LLMs consistently meet performance benchmarks, while observability tools allow teams to uncover patterns and optimize model behavior effectively.
- Enhanced Debugging and Transparency: Observability provides deeper insights into why a model produces certain outputs, using logs, traces, and metrics. This makes debugging faster and helps build trust by offering interpretability and traceability of model decisions.
- Mitigation of Risks: Monitoring flags issues like reputation-damaging outputs, compliance breaches, or inappropriate model responses in real-time. In contrast, observability helps teams understand and fix the root causes of these risks.
- Continuous Optimization: With detailed observability insights and regular monitoring, enterprises can adapt their LLMs to changing user needs, data inputs, and application contexts. This allows for long-term reliability and relevance.
LLM Observability and Monitoring Challenges
Despite the importance of LLM observability and monitoring are critical for deploying reliable AI systems, there are a wide range of challenges you’ll need to consider when implementing them.
Let’s look at the key obstacles teams face:
- Anomalous or Harmful Outputs: LLMs can unpredictably generate hallucinations, biased text, or unsafe content. Detecting these issues in real-time requires advanced monitoring solutions and automated guardrails.
- Performance Drift from Model Updates: Automatic model updates (e.g., GPT-4 → GPT-4o) may introduce subtle behavioral shifts. Tracking prompt drift and maintaining consistency across versions requires rigorous observability.
- Black-Box Interpretability: The nature of LLMs makes it hard to trace why responses occur. This makes debugging and compliance with regulations like the EU AI Act complicated.
- Scalable Traceability: Logging and analyzing millions of interactions in real-time strains infrastructure. Teams need systems that balance cost, latency, and granularity.
- Evolving Regulatory Compliance: Standards for AI transparency and data handling (e.g., GDPR, EU AI Act) change rapidly. Observability must adapt to ensure audit trails and accountability.
What's the Difference between LLM Observability and Evaluation?
While LLM observability and evaluation both play key roles in managing LLMs, they serve different purposes and operate in different stages of the AI lifecycle. Understanding their differences lets your team use the right tools at the right time.
LLM Observability
LLM observability is a continuous, real-time process focused on understanding how and why LLMs behave the way they do in production. It goes beyond surface-level metrics to provide granular insights into model decision-making, user interactions, and system health. The goal is to diagnose root causes of issues, ensure transparency, and maintain reliability by tracing model behavior across inputs, outputs, and infrastructure.
LLM Evaluation
Evaluation is often a periodic, offline process that assesses the overall quality of an LLM against predefined benchmarks or user expectations. It typically occurs during development, after major updates, or when testing new use cases. Its goal is to validate model effectiveness, safety, and alignment with business objectives.
Key Differences
The main differences between LLM observability and evaluation include:
| Aspect | Observability | Evaluation |
|---|---|---|
| Timing | Continuous (real-time) | Periodic (offline) |
| Scope | Explains why issues occur | Validates what the model does |
| Data Focus | Logs, traces, user interactions | Benchmarks, test cases, expert judgments |
| Cost | Optimized for scale (low-cost automation) | High computational resources and time |
| Regulatory Role | Ensures audit trails for compliance | Certifies model safety pre-deployment |
Read our guide on evaluating LLM applications to learn more.
Why Do Both Matter?
- Observability allows models to stay effective in production by catching issues like prompt drift, cost spikes, or compliance gaps.
- Evaluation guarantees models are effective before deployment, aligning them with user needs and ethical standards.
Together, they create a closed-loop system: evaluations set baselines, while observability ensures those baselines are maintained over time.
How Humanloop Helps With LLM Monitoring, Observability and Evaluation
Maintaining reliability and transparency at scale requires more than basic monitoring when it comes to deploying LLMs. Humanloop’s platform bridges the gap between real-time performance tracking and deep diagnostic insights. It does so by offering an integrated suite of tools designed to meet the challenges of modern AI systems.
Real-Time Observability for Production Visibility
Humanloop’s observability platform provides full-stack visibility into LLM behavior, system health, and user interactions.
Key features include:
-
Granular Metrics Tracing: Track metrics like latency and token costs in real-time while logging inputs, outputs, and token-level traces to diagnose root causes
-
Guardrails: Automatically detect harmful outputs (e.g., hallucinations, toxic language). Define custom thresholds and actions, such as redirecting flagged responses to human reviewers, to minimize reputational risks.
-
Integrated Alerting: Get instant Slack or email notifications for anomalies like sudden cost spikes or data drift. Proactive alerts ensure teams resolve issues before they escalate.
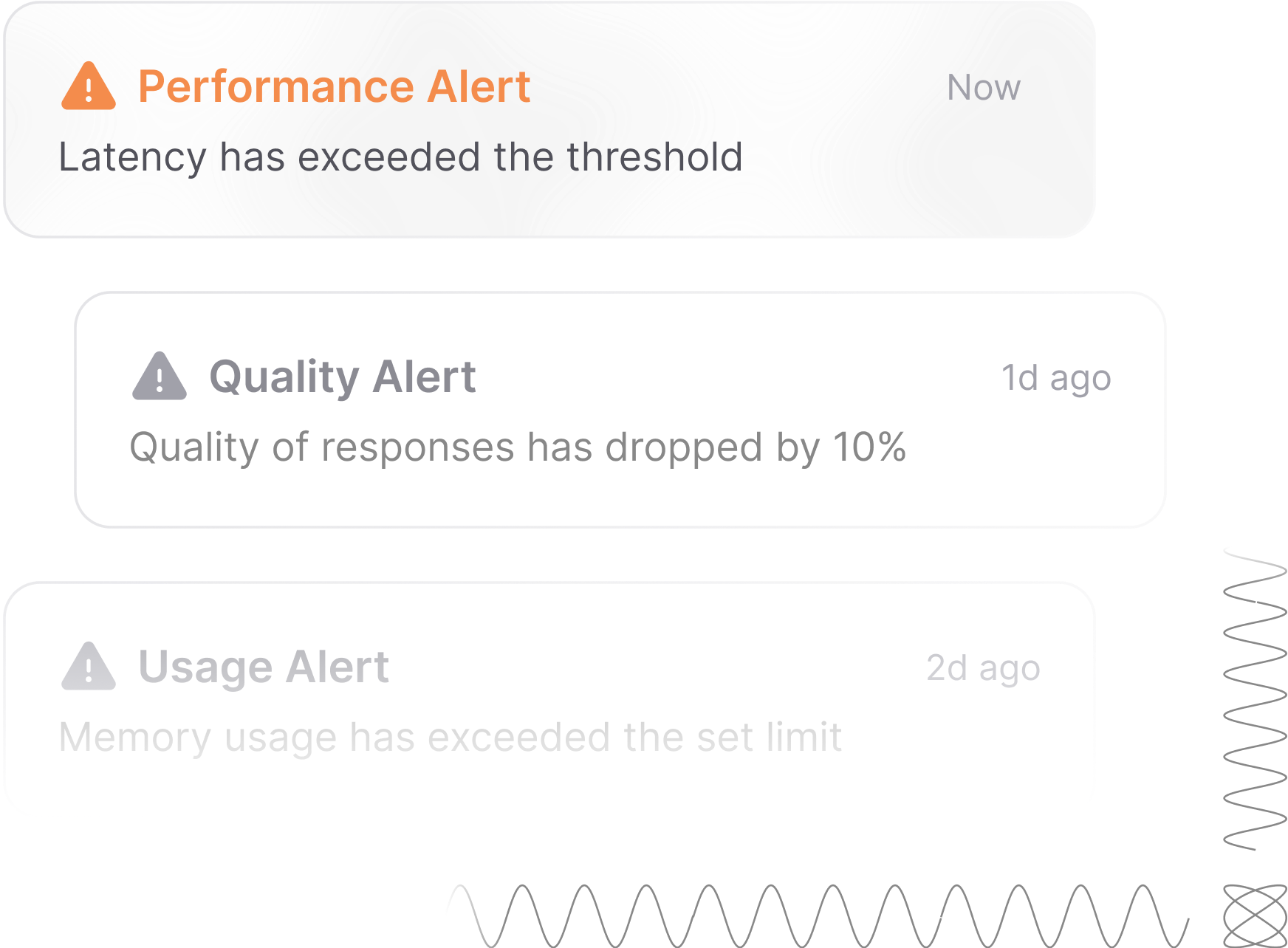
Evaluations for Pre-Deployment Validation and Continuous Improvement
Humanloop’s Evaluations Suite directly integrates with observability, creating a closed-loop feedback system.
-
LLM-as-a-Judge Assessments: Automate evaluations for subjective metrics (e.g., tone, helpfulness) using customizable LLM evaluators. These benchmarks then become guardrails in the observability platform.
-
CI/CD Integration: Embed evaluations into development pipelines to catch regressions early. Observability dashboards then track these metrics in production.
How to set up LLM Monitoring and Observability with Humanloop
Implementing effective observability and monitoring requires a structured approach.
We’ll look at how to do this with the Humanloop platform:
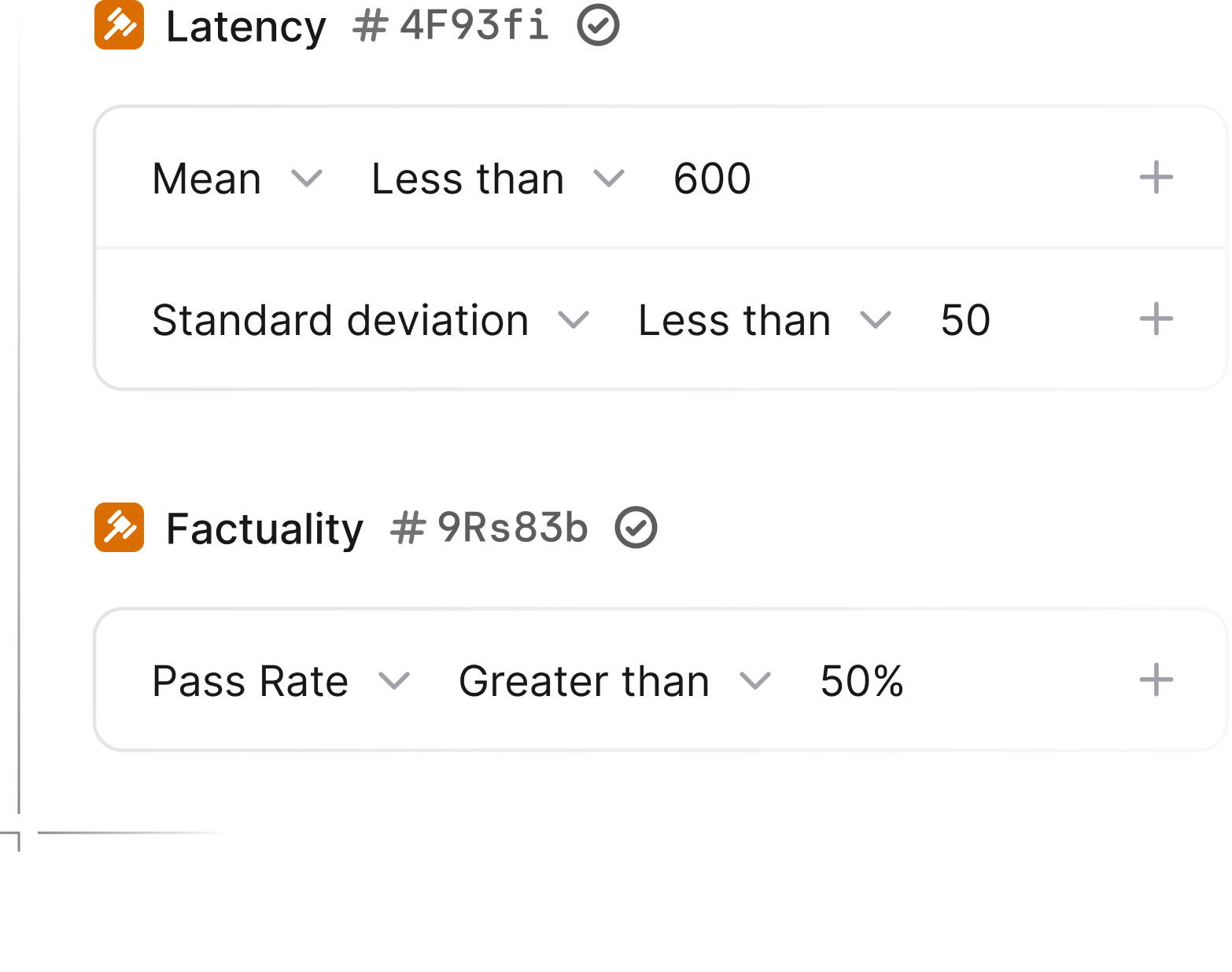
1. Define Key Metrics and Evaluators
Before deploying your LLM, you’ll want to identify key metrics aligned with your use case.
These could include:
- Accuracy
- Latency
- Helpfulness
You can use pre-built evaluators like factuality checks to flag hallucinations or inaccuracies. Moreover, you can define acceptable ranges for token costs or response times and automate alerts. Humanloop’s platform lets you attach online evaluators to your prompts to assess subjective qualities like tone or alignment with brand guidelines.
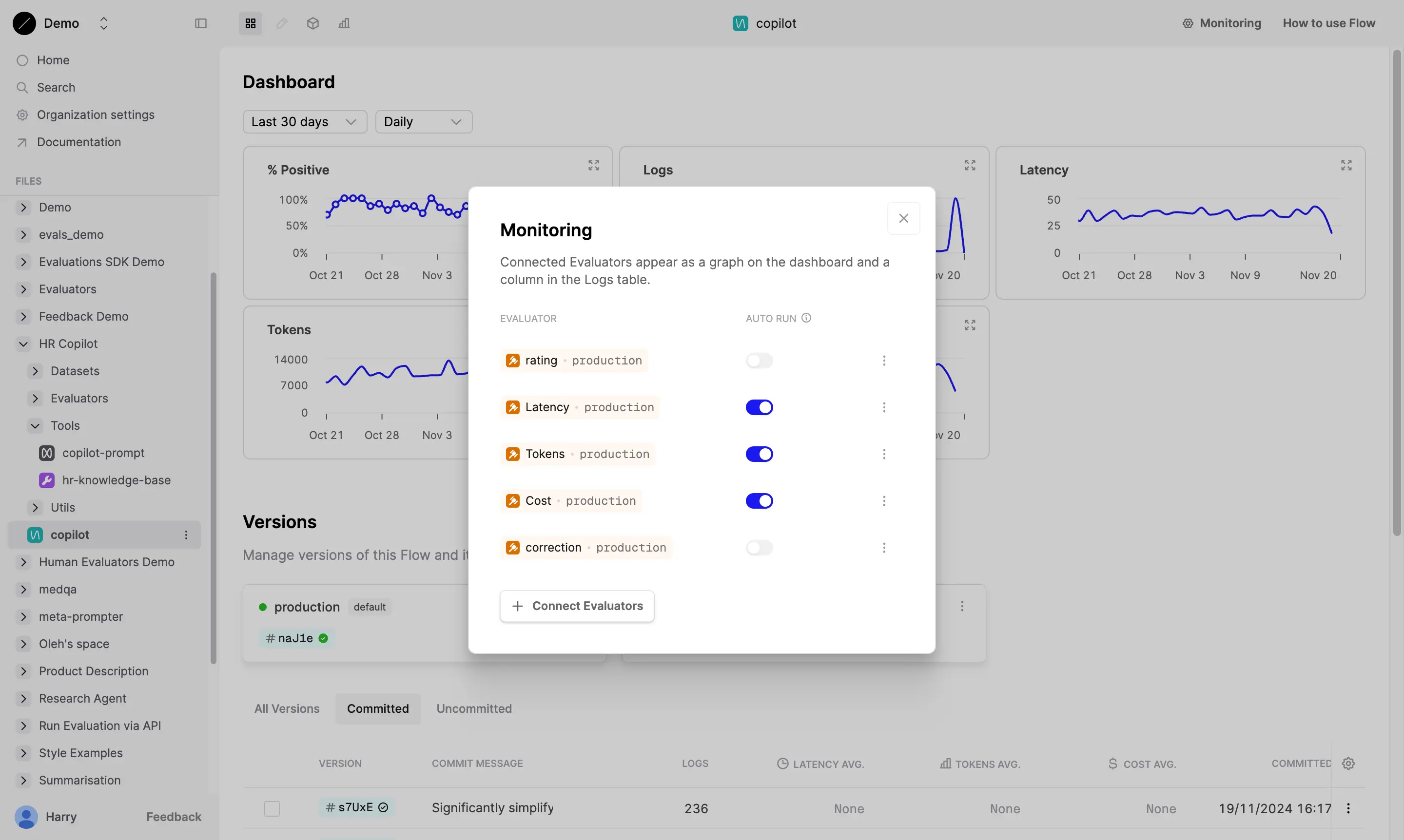
2. Connect Evaluators to Production Prompts
Afterwards, you’ll want to create a prompt by designing your LLM workflow in Humanloop’s editor.
In the monitoring tab, select evaluators like factuality or custom LLM-as-a-judge checks to run on all production logs. Then, toggle the “auto-run” switch to ensure evaluators execute on every interaction without manual intervention.
3. Analyze Results and Optimize
Humanloop’s dashboard provides actionable insights across the following tables:
Dashboard Table
Track average evaluator scores over time. Adjust date ranges to spot trends, such as latency spikes during peak hours.
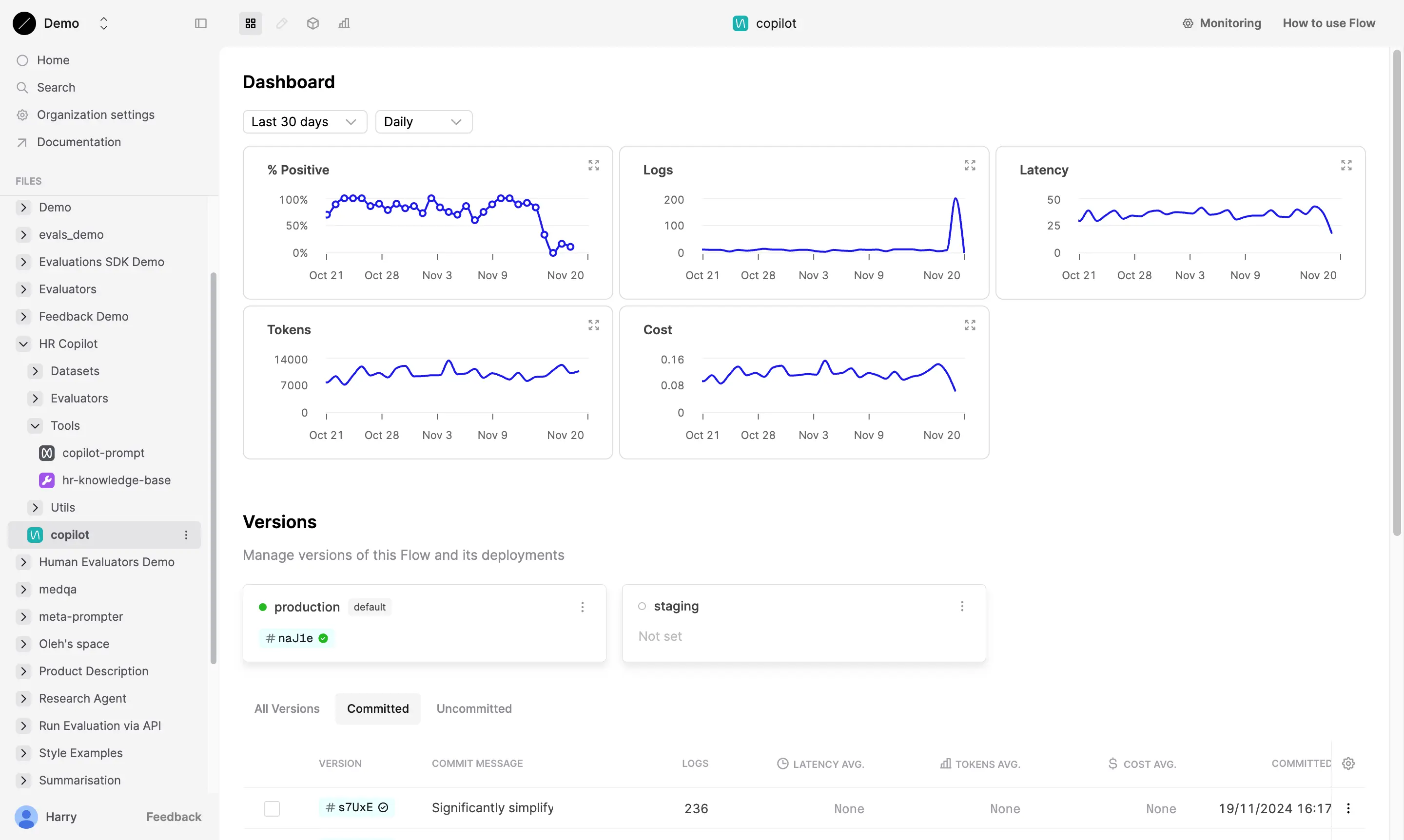
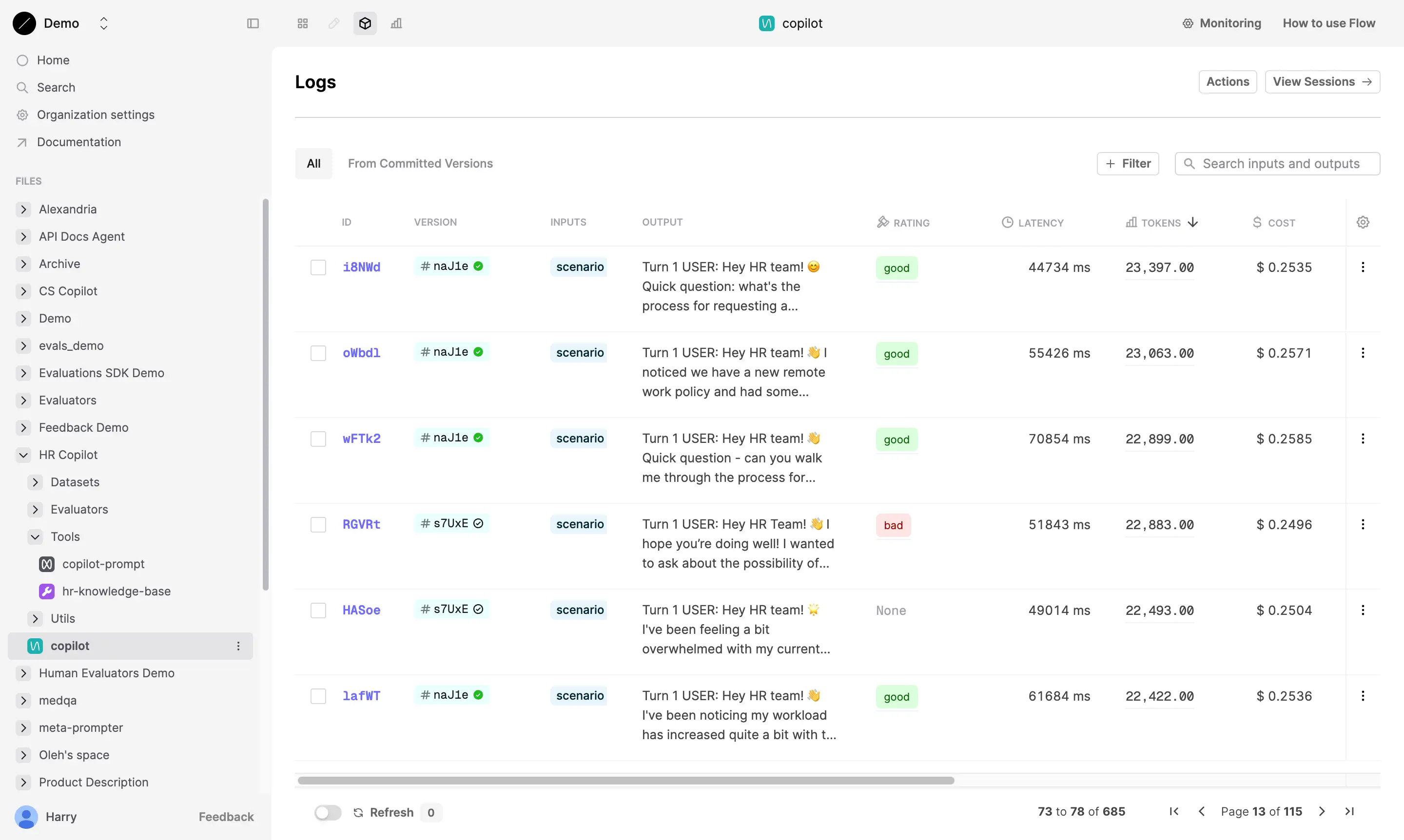
Logs Table
Filter logs by evaluator results (e.g., “bad” rating) to debug specific failures. You can then use the evaluator results to iterate and optimize your prompt.
Learn More About LLM Observability and Monitoring
LLM observability and monitoring lets teams maintain control over AI systems, offering real-time detection of harmful or anomalous outputs and deep insights into why models behave unpredictably.
Humanloop is the LLM evaluations platform for enterprises with best-in-class tooling for LLM Observability and Monitoring. Engineering and product teams at Gusto, Vanta, and Duolingo use Humanloop to understand the performance of their AI products, streamline development and track behaviour over time.
To learn how you can adopt best practices for LLM observability, monitoring, evaluation and more, chat with us today.
About the author

- 𝕏@conorkellyai










