Top 5 Vector Databases in 2025
Top 5 Vector Databases in 2025
In 2025, the demand for smarter, faster, and more scalable data systems is reshaping how we handle information. At the forefront of this shift is the vector database—a specialized type of database designed to manage and query high-dimensional data like text embeddings, image features, and other complex vectors. These databases are the backbone of applications like semantic search, recommendation engines, and retrieval-augmented generation (RAG) for AI systems.
Organizations adopt vector databases to extract meaningful patterns from vast datasets, improve user interactions through personalization, and optimize data retrieval processes. The rapid advancements in AI and the increasing need for systems that can handle unstructured, high-dimensional data are making vector databases an essential component of modern technology stacks. This blog looks at the top five vector databases of 2025, highlighting their features, differences, and applications to help you better understand this transformative technology.
What is a Vector Database?
A vector database is a specialized type of database designed to store, manage, and query data in vector format. Vectors are numerical representations of complex data types—such as text, images, audio, or video—that capture their semantic meaning in high-dimensional space. These embeddings are generated by machine learning models trained to understand patterns and relationships in unstructured data.
Unlike traditional relational databases that store structured data like numbers and strings in rows and columns, vector databases are optimized for similarity searches. This means they can efficiently find vectors that are closest in meaning or context to a given query. For example, in semantic search, a vector database can retrieve text documents, images, or audio clips that are contextually similar to a search query, even if the exact words or pixels don’t match.
In modern applications, vector databases are essential for powering AI-driven use cases like recommendation engines, image recognition, and retrieval-augmented generation (RAG) architectures. As the demand for understanding unstructured data grows, vector databases offer the performance and scalability needed to manage the massive scale of high-dimensional embeddings.
How does a Vector Database work?
At the core of a vector database lies the concept of vector embeddings—dense numerical representations of data, such as text, images, audio, or video. These embeddings are generated by machine learning models trained to capture semantic similarities between data points. For instance, in text processing, two documents with similar meanings will have embeddings that are close to each other in high-dimensional space.
Vector databases store these embeddings in specialized structures optimized for fast retrieval. Instead of traditional indexing methods like B-trees or hash tables used in relational databases, vector databases rely on advanced indexing techniques such as k-d trees, HNSW (Hierarchical Navigable Small World graphs), or product quantization. These structures enable efficient nearest neighbor searches, allowing the database to quickly find the most similar vectors to a query vector.
Retrieval processes in a vector database involve querying the stored embeddings with a new vector, often using similarity metrics like cosine similarity or Euclidean distance. This process is key to applications such as semantic search or recommendation systems, where results need to be ranked based on relevance rather than exact matches.
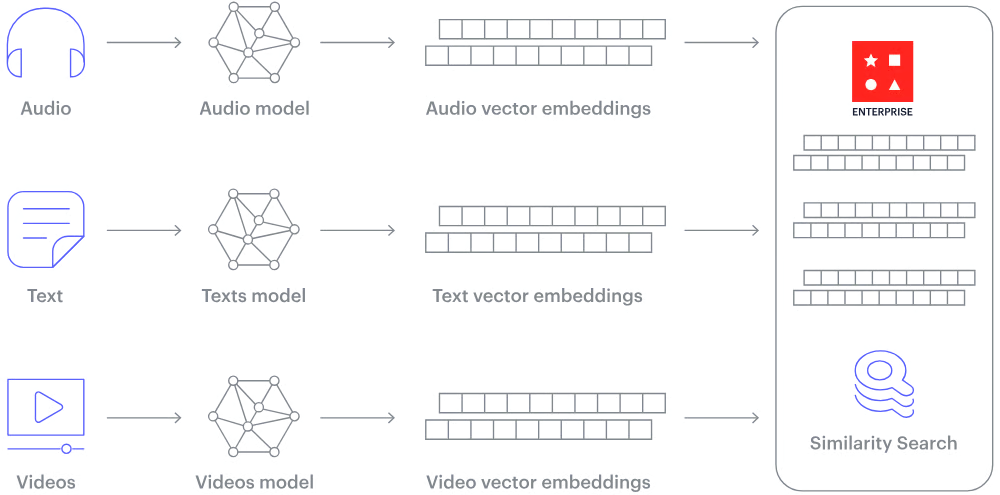
Popular Vector Database Applications
Below, we explore five of the most popular vector databases of 2025, in no particular order.
1. Chroma
Chroma is a rapidly growing vector database designed specifically for modern AI applications. Its architecture is built to seamlessly integrate with workflows that require high-dimensional vector search, such as semantic search, and personalized recommendation systems. One of Chroma’s key strengths lies in its user-friendly design and its focus on simplifying embedding management, making it highly accessible to developers and data scientists.
Key features of Chroma include real-time vector search and seamless integration with popular machine learning frameworks. Chroma also stands out for its open-source nature, enabling users to adapt the platform to their specific needs while benefiting from a supportive community.
Best-suited applications for Chroma include systems that rely heavily on semantic understanding, such as AI-powered chatbots, enterprise search tools, and media retrieval systems.
2. Pinecone
Pinecone is a powerful vector database designed to simplify and optimize similarity search in AI-driven applications. Known for its reliability, Pinecone enables users to perform real-time vector retrieval at scale, making it a go-to solution for applications like semantic search and anomaly detection. Its serverless architecture eliminates infrastructure management, allowing developers to focus on building and deploying solutions efficiently.
Key features of Pinecone include hybrid search capabilities (combining dense and sparse vector search), real-time index updates, and seamless integration with machine learning models and frameworks. Pinecone’s innovative design separates storage from compute, offering cost-effective scaling while maintaining consistent performance across workloads.
What sets Pinecone apart is its ability to deliver low-latency search results on large datasets without compromising accuracy. Pinecone’s ease of integration and high reliability make it a strong contender for developers and enterprises building next-generation AI applications.
3. Weaviate
Weaviate is a cloud-native, GraphQL-based vector database designed to handle large-scale, AI-driven applications. Known for its speed and flexibility, Weaviate is capable of performing nearest-neighbor searches across millions of objects in just milliseconds. Its architecture supports both on-the-fly vectorization during data import and the use of pre-computed embeddings, giving developers greater flexibility in building AI-powered solutions.
Key features of Weaviate include an easy-to-use GraphQL interface, schema flexibility, and native integrations with machine learning platforms like OpenAI, Cohere, and HuggingFace. It also emphasizes scalability, with built-in support for replication and sharding to maintain performance as datasets grow. Beyond vector searches, Weaviate offers functionalities like recommendation systems, summarization tools, and neural search framework integrations.
Weaviate stands out for its ability to bridge rapid prototyping and large-scale production environments seamlessly. Used by companies such as Red Hat, Stack Overflow, and Writesonic, it caters to industries requiring high-speed search and retrieval with a focus on security. Additionally, its straightforward API and integration options streamline implementation, reducing the complexity of building AI-driven solutions.
4. Qdrant
Qdrant is a high-performance vector database designed for similarity searches across high-dimensional data. Built in Rust, it offers low-latency and resource-efficient operations, making it well-suited for demanding AI applications. Qdrant functions as an API service, enabling users to create applications for tasks such as matching, searching, and generating recommendations.
Key features of Qdrant include support for OpenAPI v3, ready-made client libraries for multiple programming languages, and advanced filtering capabilities that allow for result refinement based on vector payloads. It utilizes a custom implementation of the HNSW algorithm for rapid and accurate searches and offers features like filtering by string matches, numerical ranges, and even geo-locations. Qdrant also emphasizes scalability with its cloud-native design, allowing horizontal scaling for enterprise use cases.
Qdrant is trusted by companies like Discord, Johnson & Johnson, and Mozilla, reflecting its versatility and reliability in powering AI-driven solutions across industries.
5. Milvus
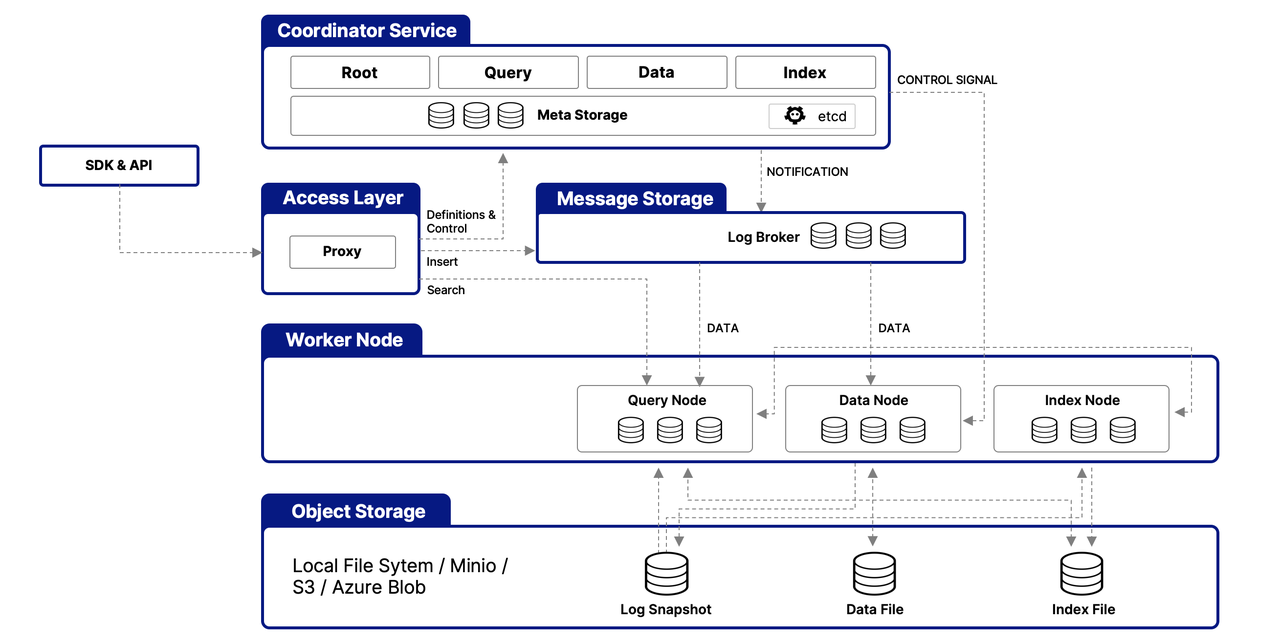
Milvus is an open-source vector database engineered for managing massive-scale vector data. With its distributed architecture, Milvus can handle billions of vectors while maintaining low-latency, high-speed similarity searches. It is optimized for both exact nearest neighbor search (NNS) and approximate nearest neighbor search (ANNS), catering to diverse application needs.
Key features of Milvus include flexible deployment options—supporting Kubernetes, Docker, and cloud environments—along with seamless integration with popular deep learning frameworks like TensorFlow, PyTorch, and Hugging Face. Its distributed design ensures scalability, making it suitable for enterprise workloads and rapidly growing datasets.
Companies like Salesforce, Shell, and Airbnb rely on Milvus for AI-driven solutions such as personalized recommendations, fraud detection, and image retrieval. Milvus is particularly well-suited for industries that require large-scale, real-time vector analysis, such as e-commerce, financial services, and media.
Conclusion
Vector databases have emerged as critical infrastructure for modern AI applications, enabling efficient management and retrieval of high-dimensional data. Whether you need scalability for massive datasets, seamless integration with machine learning frameworks, or advanced search capabilities, the choice of a vector database should align with your specific application needs.
The ongoing evolution of vector databases is redefining how organizations leverage AI to deliver smarter, faster, and more personalized solutions. As enterprises continue to adopt AI at scale, selecting the right vector database will be pivotal in driving innovation and staying competitive.
If you're looking to incorporate vector databases into your AI solutions, explore how Humanloop can help streamline your journey. Book a demo today and discover how we can enhance your AI capabilities.
About the author

- 𝕏@conorkellyai










