November
Logging with Decorators
November 16th, 2024
We’ve released a new version of our Python SDK in beta that includes a suite of decorators that allow you to more seamlessly add Humanloop logging to your existing AI features.
By adding the new decorators like @flow or @prompt to your existing functions, the next time your code runs, Humanloop will start to version and monitor your application.
In this release, we’re introducing decorators for Prompts, Tools, and Flows:
-
@prompt: Automatically creates a Prompt on Humanloop and tracks your LLM provider calls; with details like provider and any hyperparameters. This decorator supports OpenAI, Anthropic, Replicate, Cohere, and Bedrock clients. Changing the LLM provider, or the hyperparameters used, will automatically bump the Prompt version on Humanloop. -
@tool: Uses the function’s signature and docstring to create and version a Tool. Changing the code of the function will create a new version of the Tool and any calls to the Tool will be logged appropriately. -
@flow: Designed for the main entry point of your LLM feature to capture all the steps within. Any other decorated functions called within the@floware automatically logged into its trace.
You can also explicitly pass values for decorator arguments; including attributes and metadata. Values passed explicitly to the decorator will override any inference made by the SDK when logging to Humanloop.
Here’s an example of how to instrument a basic chat agent. Each conversation creates a Log under a Flow, with Prompt and Tool Logs then captured for each interaction.
After running this code, the full trace of the agent will be visible on Humanloop immediately:
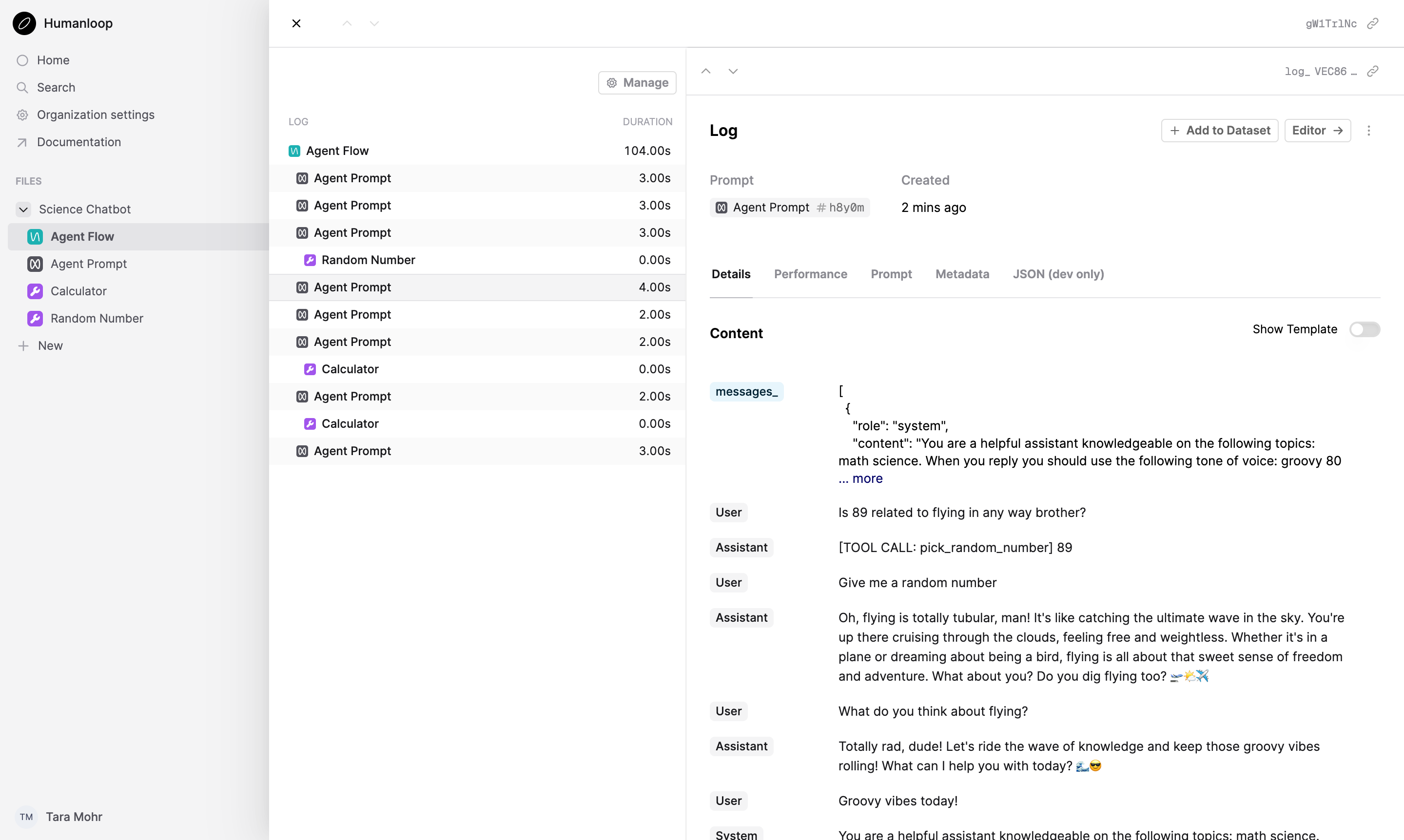
This decorator logging also works natively with our existing offline eval workflows.
If you first instrument your AI feature with decorators and then subsequently want to run evals against it, you can just pass it in as the callable to
hl.evaluations.run(...). The logs generated using the decorators will automatically be picked up by the Eval Run.
Similar functionality coming soon to TypeScript!
New App Layout
November 14th, 2024
We’ve launched a major redesign of our application interface, focusing on giving you a clearer app structure and more consistent navigation. The new design features refined sidebars, tabs, and side panels that create a more cohesive experience.
The primary views Dashboard, Editor, Logs and Evaluations are now located in the top navigation bar as consistent tabs for all files. The sidebar no longer expands to show these views under each file, which gives you a more stable sense of where you are in the app.
The new layout also speeds up navigation between files through wiser prefetching of the content, and the default view when opening a file is now the Editor.
These changes lay the foundation for further improvements to come such as consistent ways to slice and dice the data on different versions through each view.
 The new layout with the top navigation bar
The new layout with the top navigation bar
 Before
Before After
AfterEvals Comparison Mode progress bar
November 13th, 2024
We’ve added a progress bar to the comparison view to help you and your Subject Matter Experts (SME) track the progress of your human evaluations more easily.
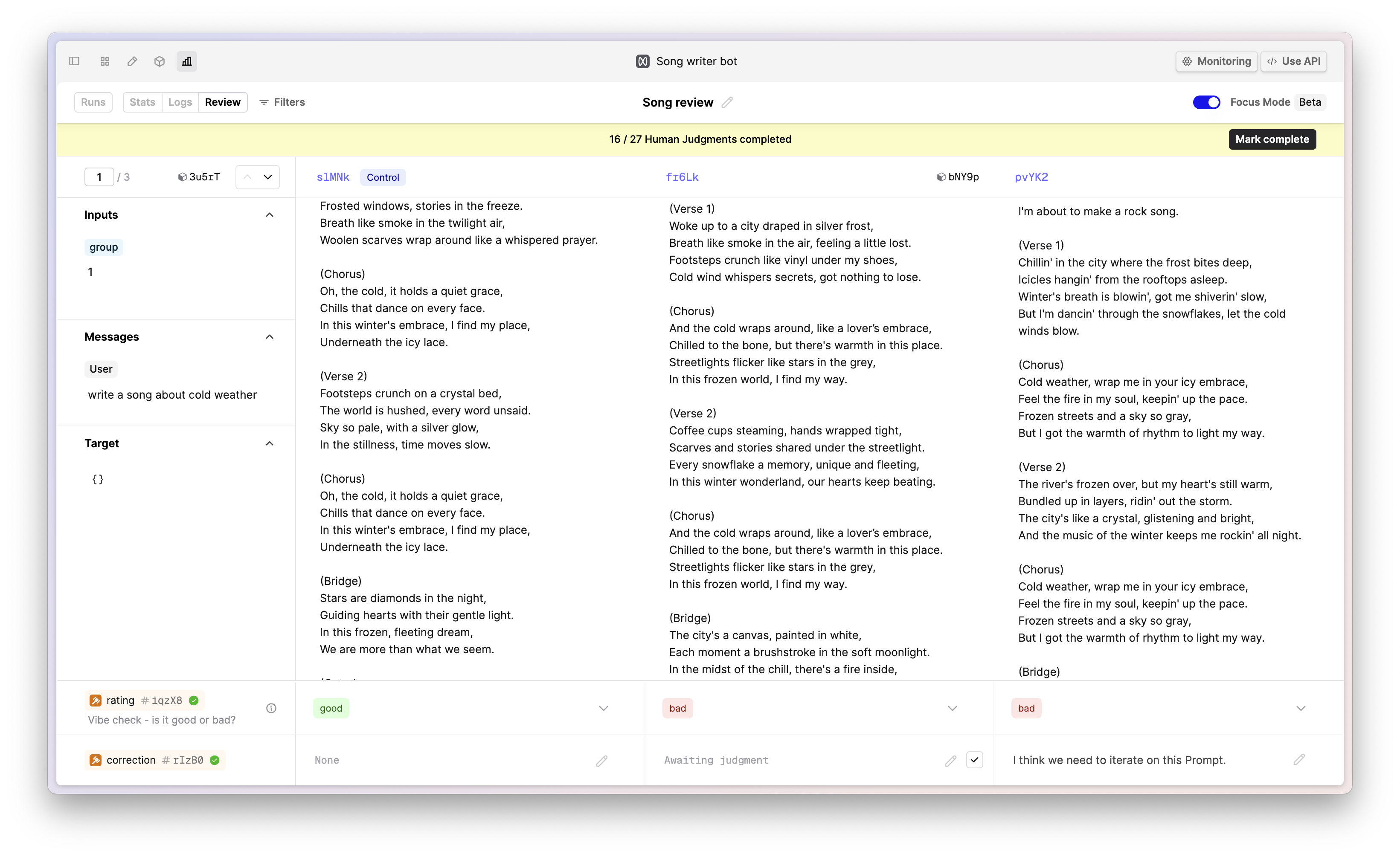
You can also now mark individual cells as complete without providing a judgment value for the Evaluator. This is particularly useful when the Evaluator is not applicable for the output under review.
Evals Comparison Mode filters
November 8th, 2024
We’ve added filters to the comparison view to help you and your domain experts provide judgments more efficiently and quickly.
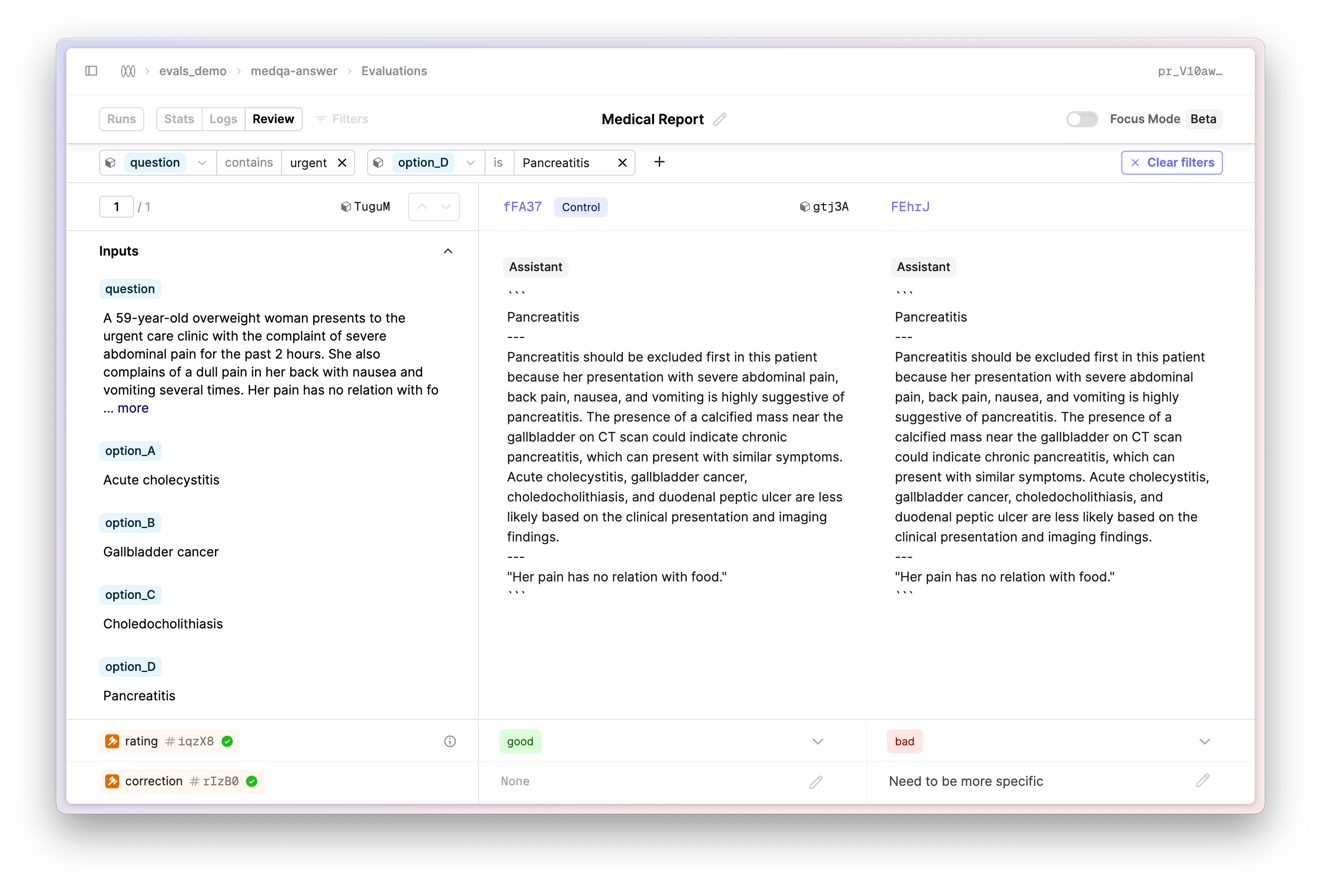
While on the Review tab, click the Filters button to open the filters panel. You can filter the datapoints by full or partial text matches of the input variable values. In future updates, we will add support for filtering by evaluator judgments. This will provide you with more flexibility in how you view and interact with your evaluations.
Enhanced Eval Runs
November 5th, 2024
We’ve extended our concept of an Eval Run to make it more versatile and easier to organise. Before now, every Run in an Evaluation had to use the exact same version of your Dataset. With this change:
-
We now allow you to change your Dataset between Runs if required; this is particularly useful when trying to iterate on and improve your Dataset during the process.
-
You can now create a Run using existing logs, without first requiring a Dataset at all; this is great for using evals to help spot check production logs, or to more easily leverage your existing logs for evals.
-
We’ve also added a new
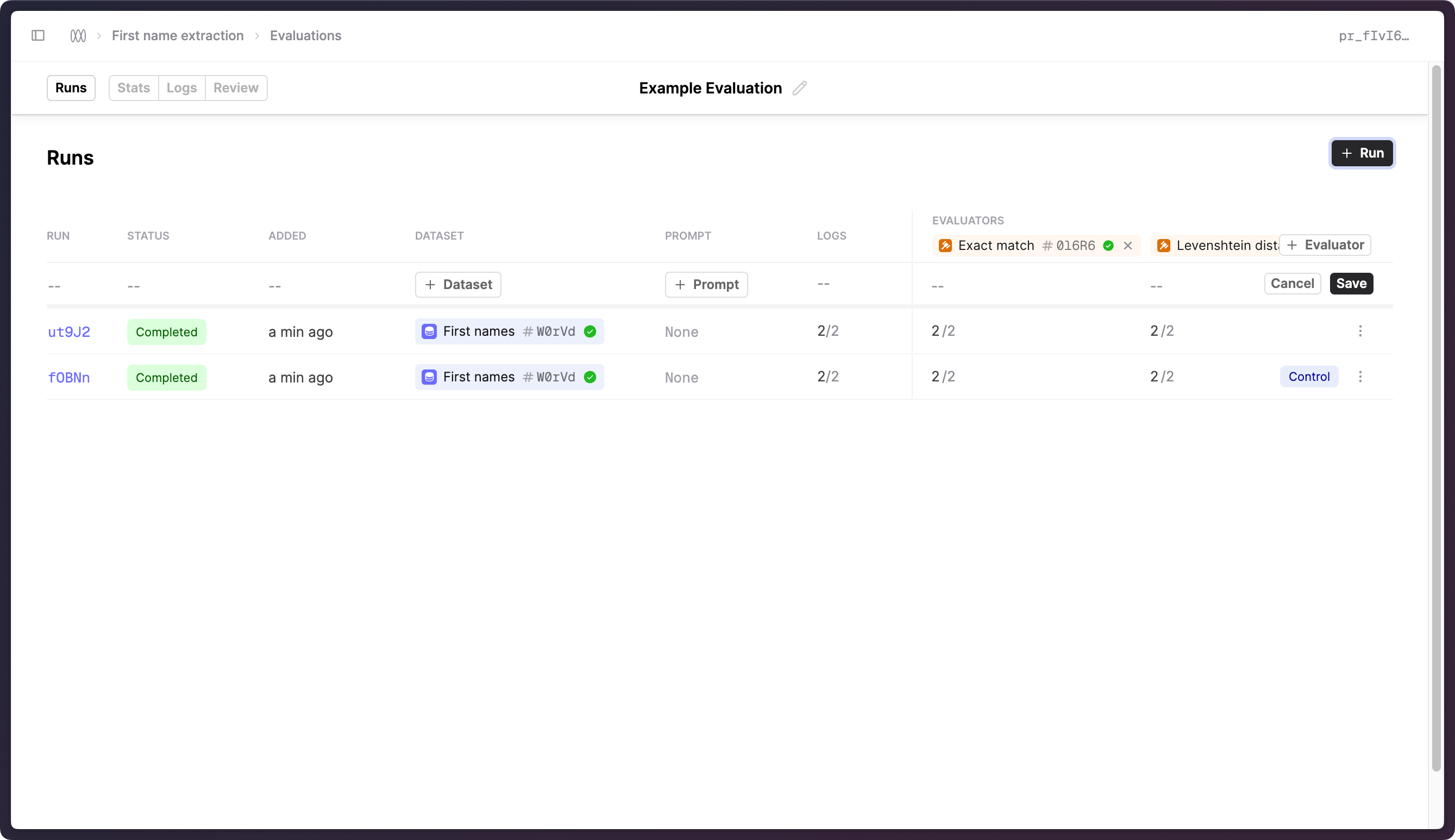
Runstab within an Evaluation to provide a clearer UI around the setup, progress and organisation of different Runs.
How to create Runs
In the newly-introduced Runs tab, click on the + Run button to start creating a new Run. This will insert a new row in the table where you can select a Version and Dataset as before, before clicking Save to create the Run.
To start using Eval Runs in your code, install the latest version of the Humanloop SDK.
In Python, you can use the humanloop.evaluations.run(...) utility to create a Run. Alternatively, when managing API calls directly yourself, you can create a Run by calling humanloop.evaluation.create_run(...) and pass the generated run_id into your humanloop.prompts.log(run_id=run_id, ...) call.
This replaces the previous evaluation_id and batch_id arguments in the log method.
In order to create a Run for existing logs, use the humanloop.evaluations.create_run(...) method without specifying a Dataset and then use humanloop.prompts.log(run_id=run_id, ...) to associate your Logs to the Run.
Furthermore, if the Logs are already on Humanloop, you can add them to the Run by calling humanloop.evaluations.add_logs_to_run(id=evaluation.id, run_id=run.id, log_ids=log_ids) with the log_ids of the Logs you want to add.