February
New Tool creation flow
February 26th, 2024
You can now create Tools in the same way as you create Prompts and Directories. This is helpful as it makes it easier to discover Tools and easier to quickly create new ones.
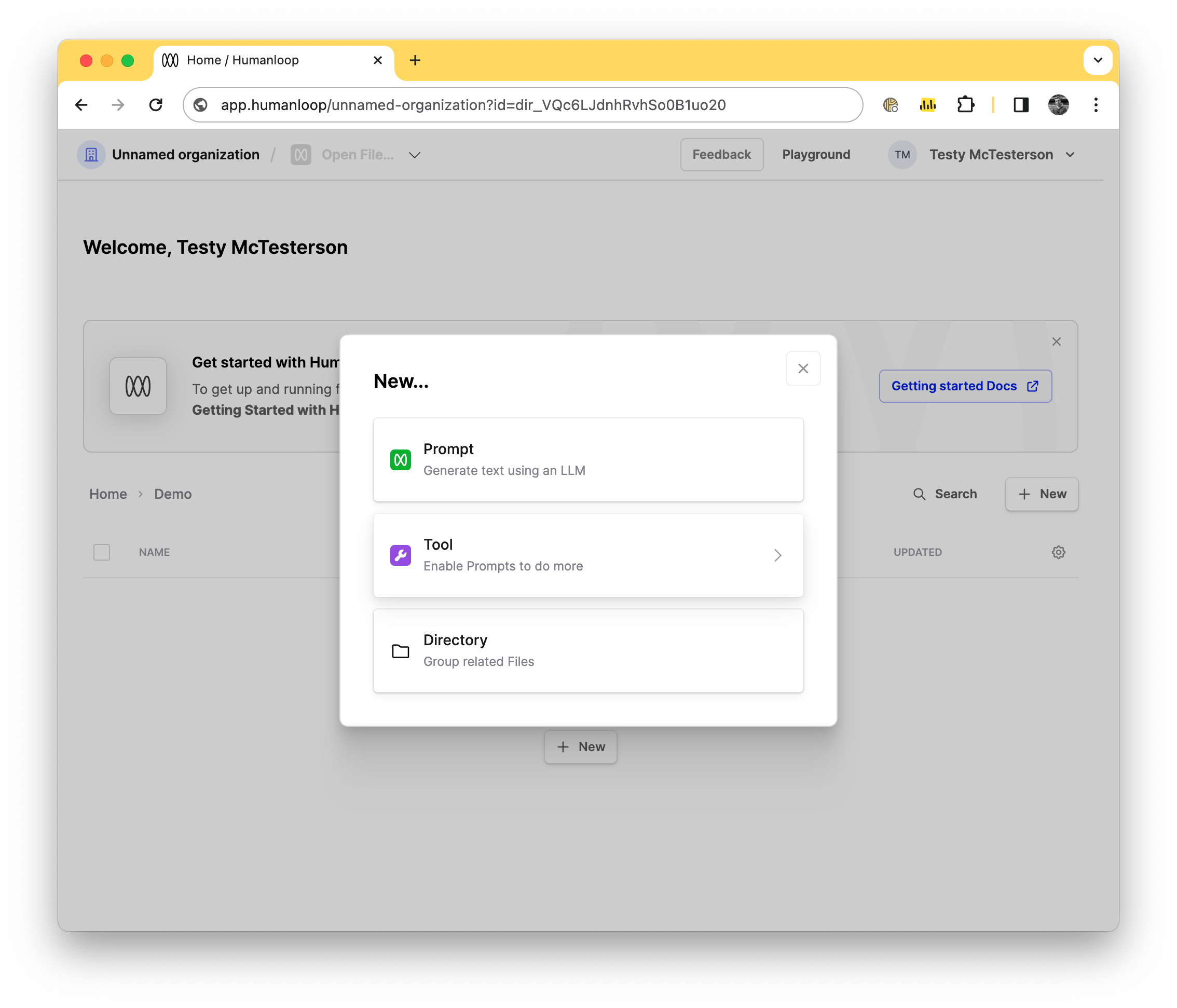
To create a new Tool simply press the New button from the directory of your choice and select one of our supported Tools, such as JSON Schema tool for function calling or our Pinecone tool to integrate with your RAG pipelines.
Tool editor and deployments
February 26th, 2024
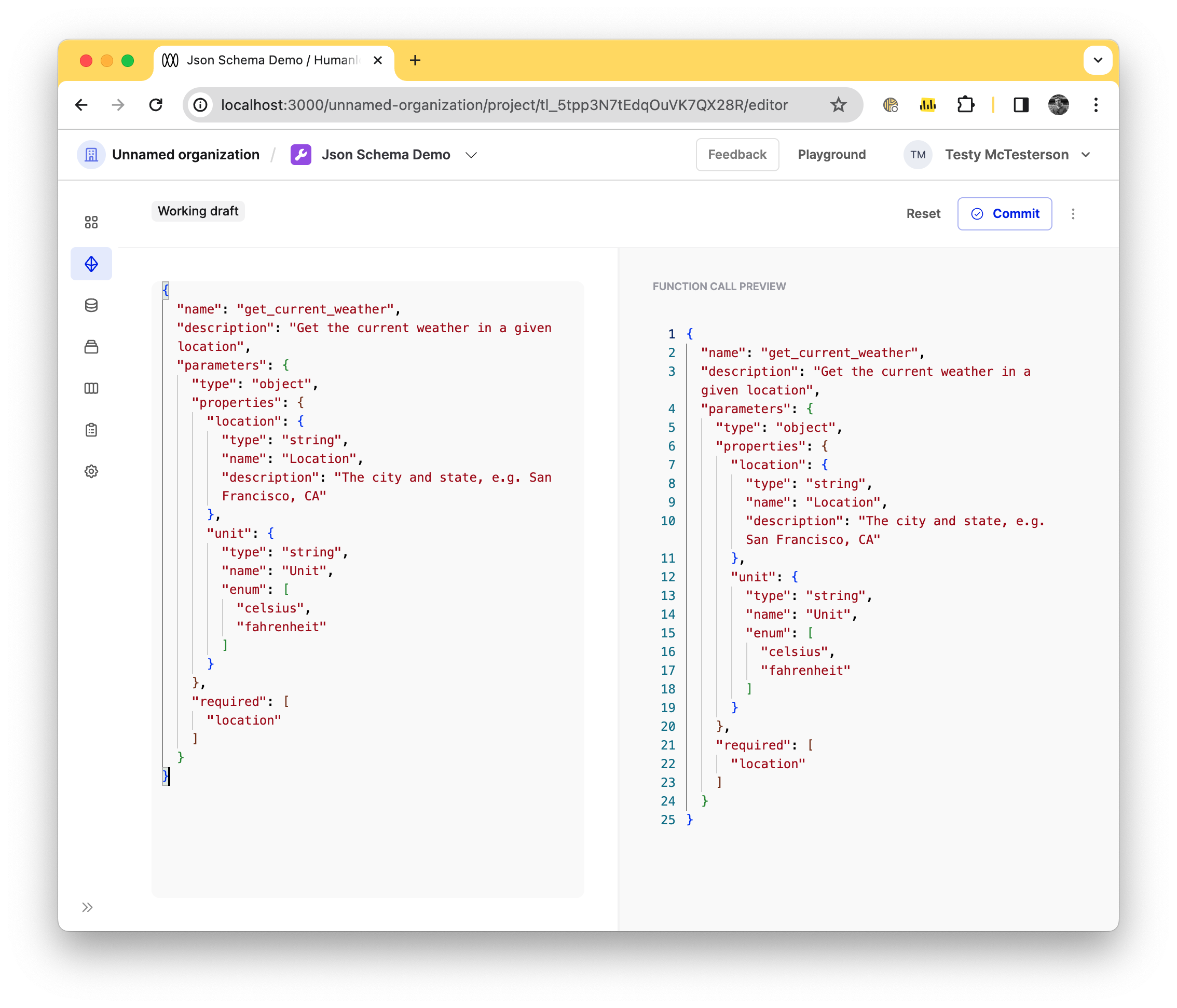
You can now manage and edit your Tools in our new Tool Editor. This is found in each Tool file and lets you create and iterate on your tools. As well, we have introduced deployments to Tools, so you can better control which versions of a tool are used within your Prompts.
Tool Editor
This replaces the previous Tools section which has been removed. The editor will let you edit any of the tool types that Humanloop supports (JSON Schema, Google, Pinecone, Snippet, Get API) and commit new Versions.
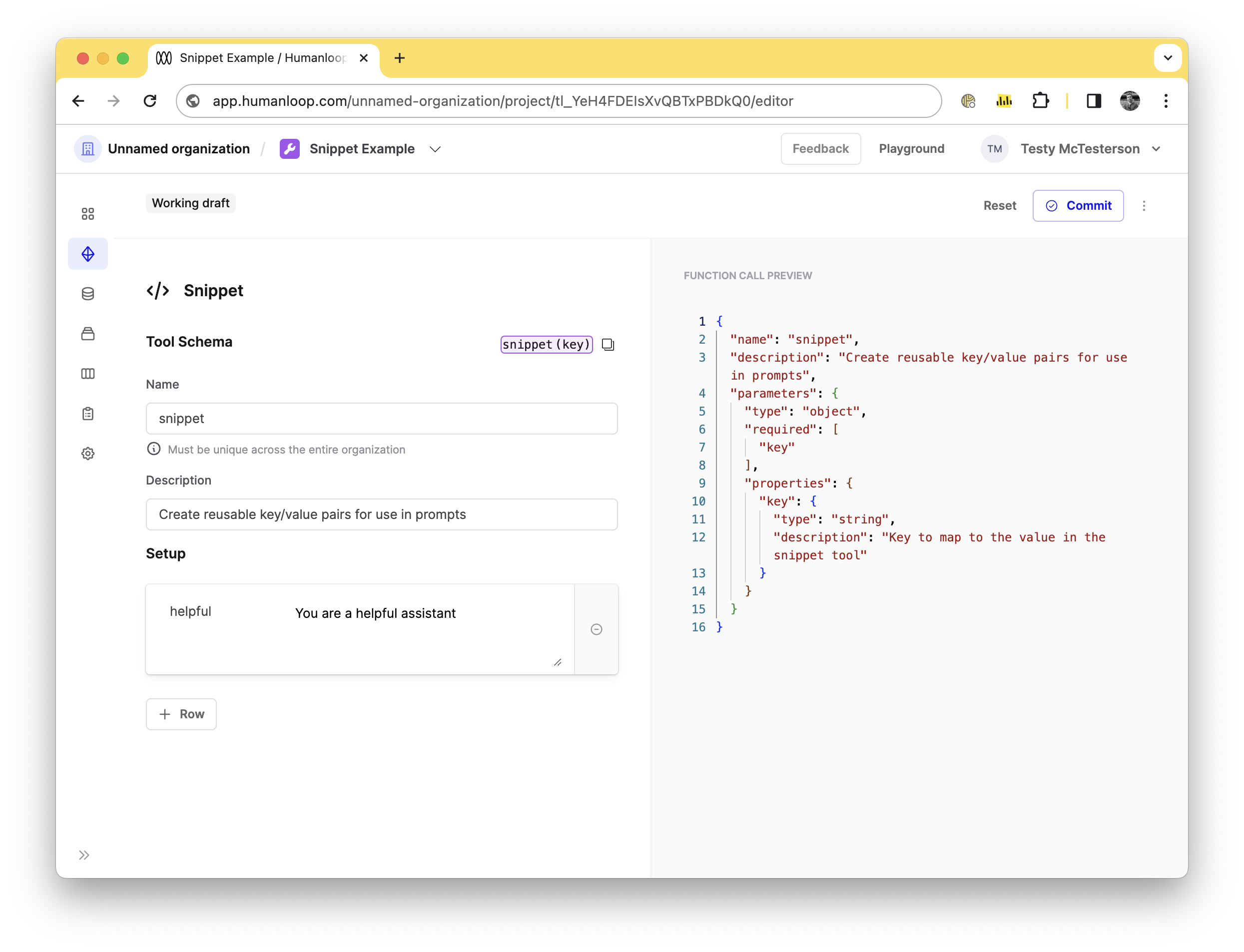
Deployment
Tools can now be deployed. You can pick a version of your Tool and deploy it. When deployed it can be used and referenced in a Prompt editor.
And example of this, if you have a version of a Snippet tool with the signature snippet(key) with a key/value pair of “helpful”/“You are a helpful assistant”. You decide you would rather change the value to say “You are a funny assistant”, you can commit a version of the Tool with the updated key. This wont affect any of your prompts that reference the Snippet tool until you Deploy the second version, after which each prompt will automatically start using the funny assistant prompt.
Prompt labels and hover cards
February 26th, 2024
We’ve rolled out a unified label for our Prompt Versions to allow you to quickly identify your Prompt Versions throughout our UI. As we’re rolling out these labels across the app, you’ll have a consistent way of interacting with and identifying your Prompt Versions.

The labels show the deployed status and short ID of the Prompt Version. When you hover over these labels, you will see a card that displays the commit message and authorship of the committed version.
You’ll be able to find these labels in many places across the app, such as in your Prompt’s deployment settings, in the Logs drawer, and in the Editor.

As a quick tip, the color of the checkmark in the label indicates that this is a version that has been deployed. If the Prompt Version has not been deployed, the checkmark will be black.

Committing Prompt Versions
February 26th, 2024
Building on our terminology improvements from Project -> Prompt, we’ve now updated Model Configs -> Prompt Versions to improve consistency in our UI.
This is part of a larger suite of changes to improve the workflows around how entities are managed on Humanloop and to make them easier to work with and understand. We will also be following up soon with a new and improved major version of our API that encapsulates all of our terminology improvements.
In addition to just the terminology update, we’ve improved our Prompt versioning functionality to now use commits that can take commit messages, where you can describe how you’ve been iterating on your Prompts.
We’ve removed the need for names (and our auto-generated placeholder names) in favour of using explicit commit messages.

We’ll continue to improve the version control and file types support over the coming weeks.
Let us know if you have any questions around these changes!
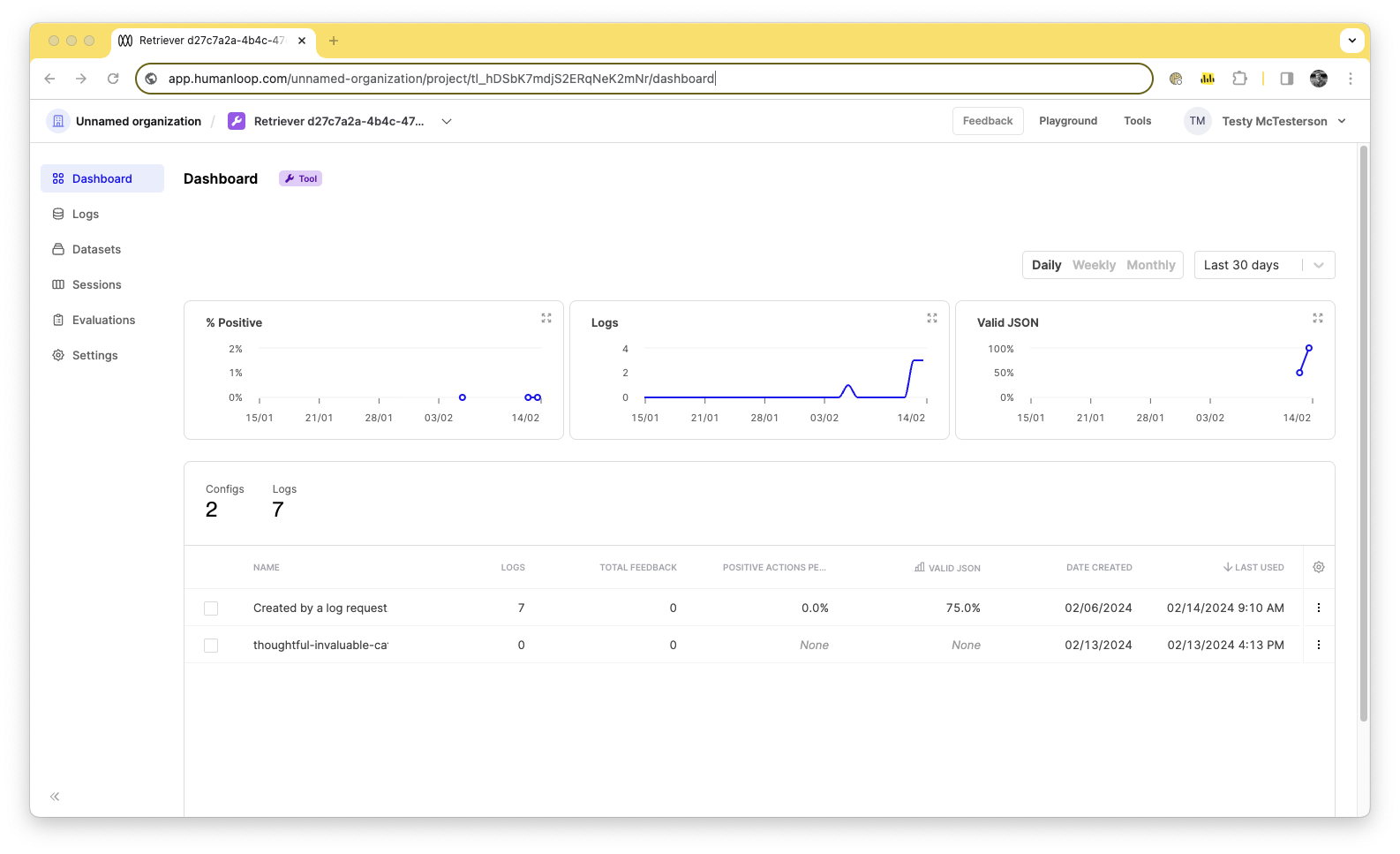
Online evaluators for monitoring Tools
February 14th, 2024
You can now use your online evaluators for monitoring the logs sent to your Tools. The results of this can be seen in the graphs on the Tool dashboard as well as on the Logs tab of the Tool.
Logging token usage
February 14th, 2024
We’re now computing and storing the number of tokens used in both the requests to and responses from the model.
This information is available in the logs table UI and as part of the log response in the API. Furthermore you can use the token counts as inputs to your code and LLM based evaluators.
The number of tokens used in the request is called prompt_tokens and the number of tokens used in the response is called output_tokens.
This works consistently across all model providers and whether or not you are you are streaming the responses. OpenAI, for example, do not return token usage stats when in streaming mode.

Prompt Version authorship
February 13th, 2024
You can now view who authored a Prompt Version.

We’ve also introduced a popover showing more Prompt Version details that shows when you mouseover a Prompt Version’s ID.

Keep an eye out as we’ll be introducing this in more places across the app.
Filterable and sortable evaluations overview
February 9th, 2024
We’ve made improvements to the evaluations runs overview page to make it easier for your team to find interesting or important runs.
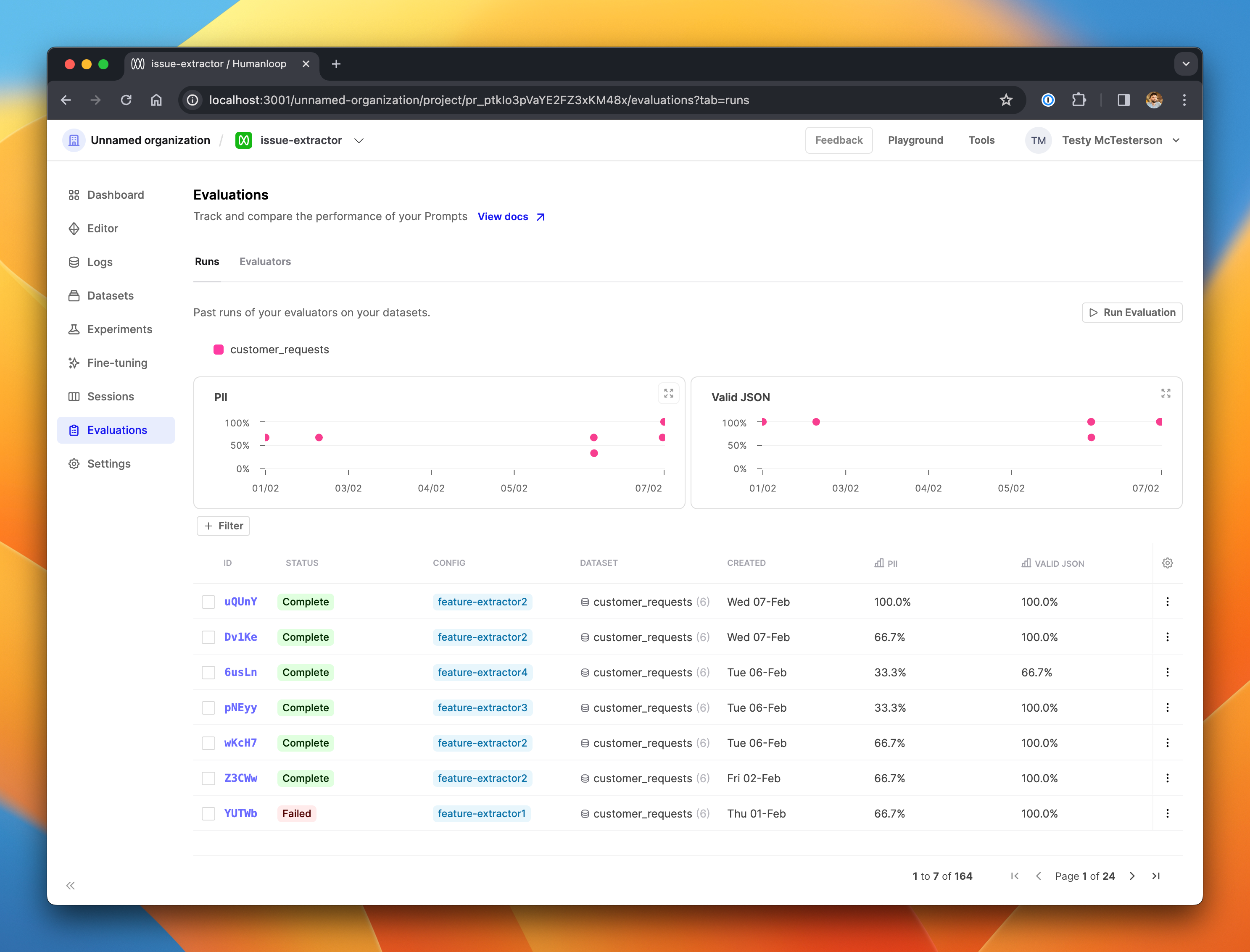
The charts have been updated to show a single datapoint per run. Each chart represents a single evaluator, and shows the performance of the prompt tested in that run, so you can see at a glance how the performance your prompt versions have evolved through time, and visually spot the outliers. Datapoints are color-coded by the dataset used for the run.
The table is now paginated and does not load your entire project’s list of evaluation runs in a single page load. The page should therefore load faster for teams with a large number of runs.
The columns in the table are now filterable and sortable, allowing you to - for example - filter just for the completed runs which test two specific prompt versions on a specific datasets, sorted by their performance under a particular evaluator.

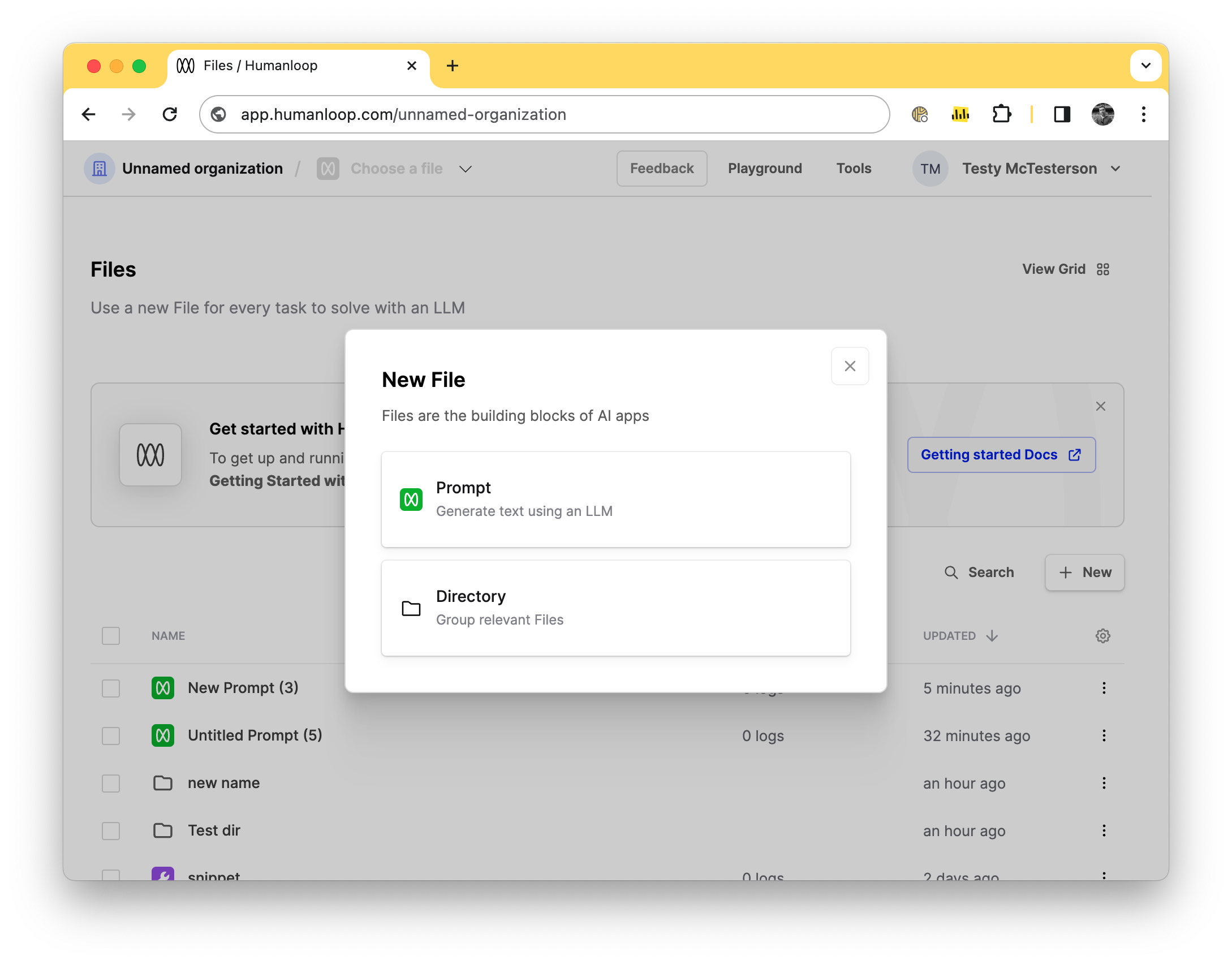
Projects rename and file creation flow
February 8th, 2024
We’ve renamed Projects to Prompts and Tools as part of our move towards managing Prompts, Tools, Evaluators and Datasets as special-cased and strictly versioned files in your Humanloop directories.
This is a purely cosmetic change for now. Your Projects (now Prompts and Tools) will continue to behave exactly the same. This is the first step in a whole host of app layout, navigation and API improvements we have planned in the coming weeks.
If you are curious, please reach out to learn more.

New creation flow
We’ve also updated our file creation flow UI. When you go to create projects you’ll notice they are called Prompts now.
Control logging level
February 2nd, 2024
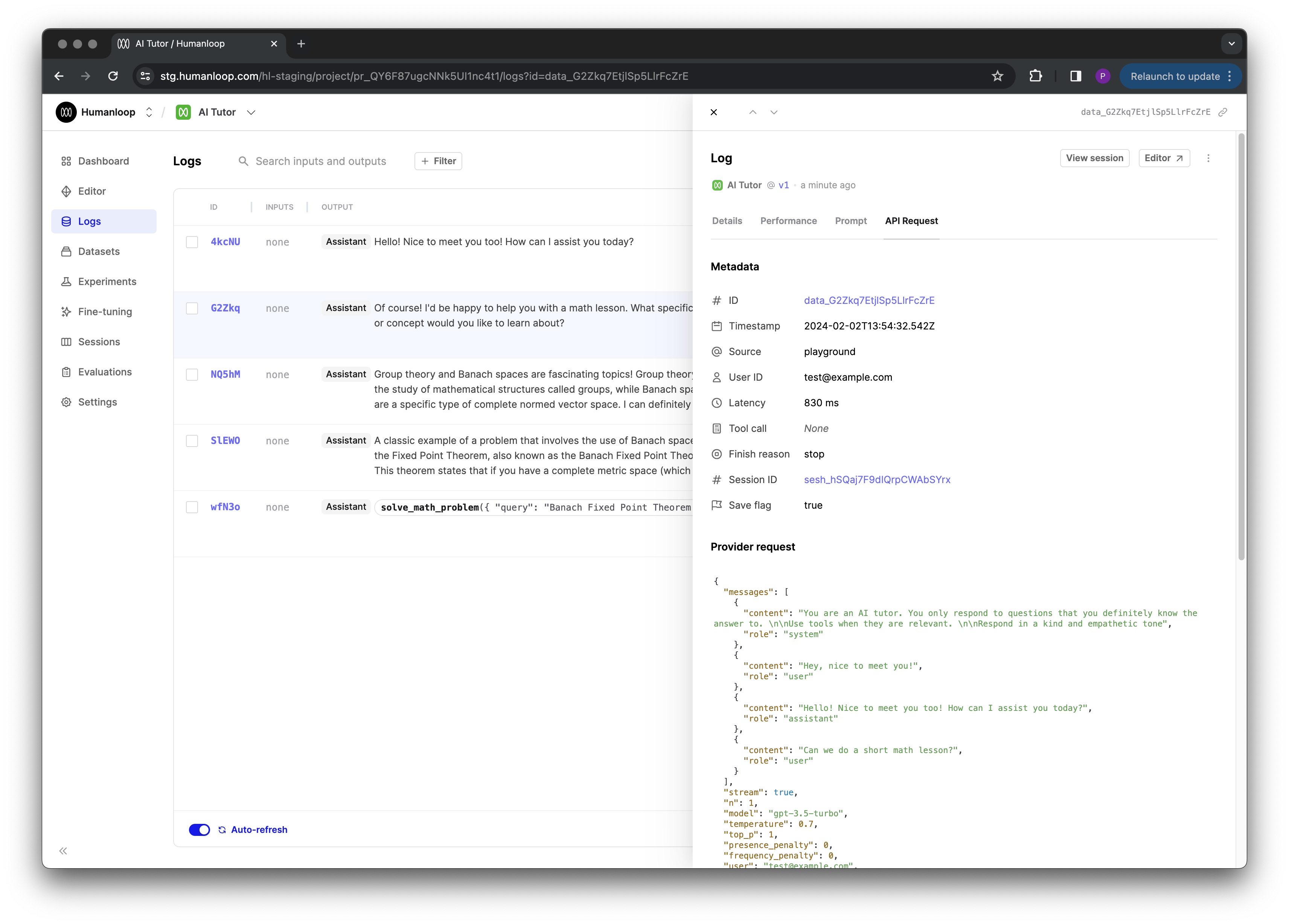
We’ve added a save flag to all of our endpoints that generate logs on Humanloop so that you can control whether the request and response payloads that may contain sensitive information are persisted on our servers or not.
If save is set to false then no inputs, messages our outputs of any kind (including the raw provider request and responses) are stored on our servers. This can be helpful for sensitive use cases where you can’t for example risk PII leaving your system.
Details of the model configuration and any metadata you send are still stored. Therefore you can still benefit from certain types of evaluators such as human feedback, latency and cost, as well as still track important metadata over time that may not contain sensitive information.
This includes all our chat and completion endpoint variations, as well as our explicit log endpoint.
Logging provider request
February 2nd, 2024
We’re now capturing the raw provider request body alongside the existing provider response for all logs generated from our deployed endpoints.
This provides more transparency into how we map our provider agnostic requests to specific providers. It can also effective for helping to troubleshoot the cases where we return well handled provider errors from our API.