A look back at 2024: How Humanloop has evolved
A look back at 2024: How Humanloop has evolved
Over the last year, we’ve built out our platform for managing the full lifecycle of AI applications, including prompt management, evals and observability.
In this post, I’ll provide a brief run through of how our platform has evolved over this time by highlighting the major areas that we’ve invested time in. At Humanloop we do weekly product releases and maintain a tight feedback cycle with our customers. This process has helped us in setting the standard for AI engineering as the space and needs of customers have evolved.
Release Highlights
We've released many new features over the year across the areas of Prompt Management, Editor, Model Proxy, Complex Tracing, Evals and Human Review, which all work in unison on Humanloop. Here are some of the highlights:
Prompt Management
An important part of your AI development is having a place to store and version your Prompts, where your engineers and product teams can easily collaborate. As opposed to hard-coding Prompts in code and alienating non-engineering teams, customers manage their Prompts on Humanloop where we've added features like:
- A flexible file system, where Prompts can be organised in directories with access control.
- Enhanced version control with git-like commits, diff views and attribution.
- Environment management and the ability to tag Prompts for deployment to staging and production.
- Our
.promptfiles format for easier source control integration. - Custom prompt attributes to control versioning based on your application needs.
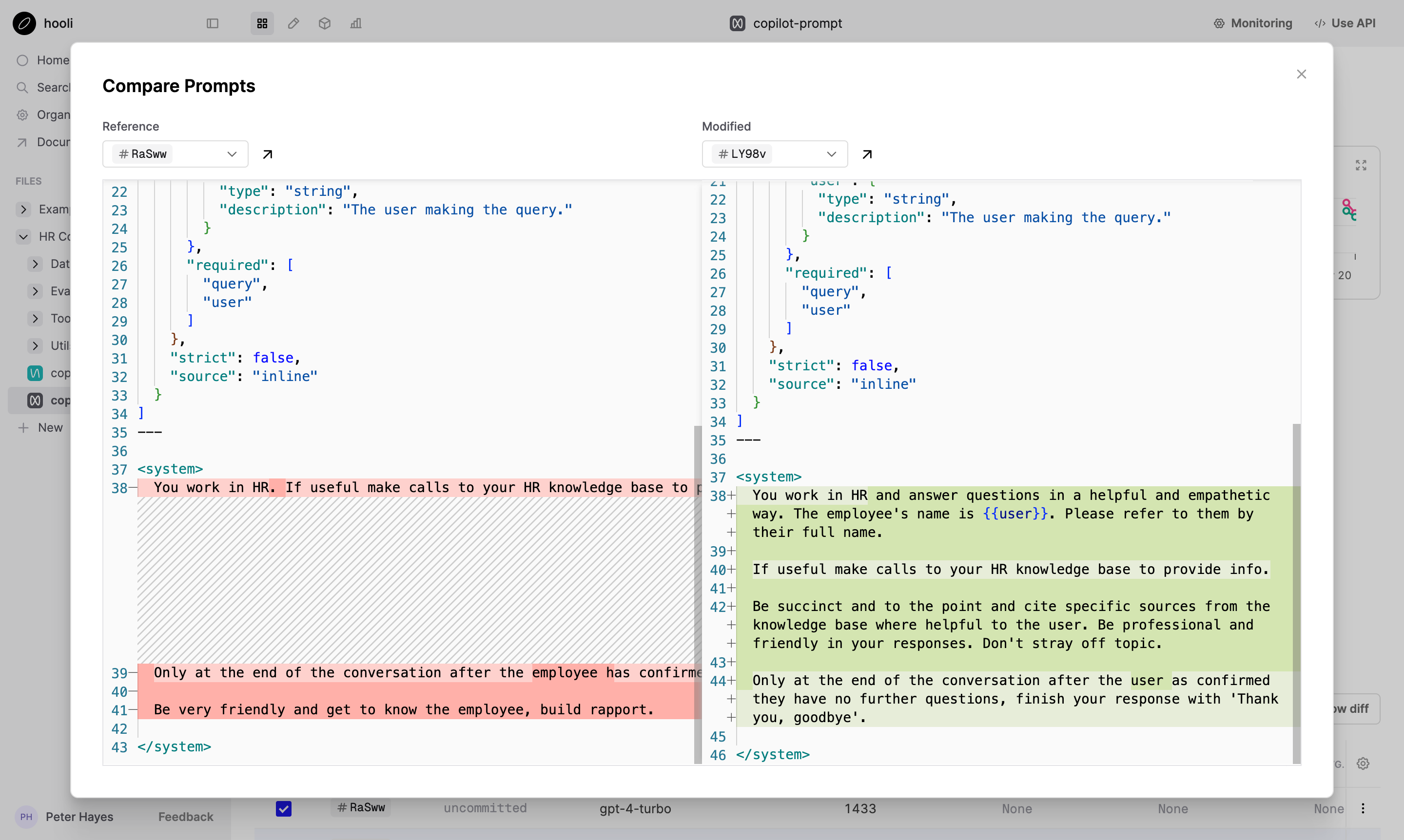
Interactive Editor Environment
At the heart of the Humanloop UI is our interactive Editor environment. Teams use the Editor to iterate on their Prompts and Agents, pulling in context from their production logs, swapping between different model providers and triggering evals to measure improvements. We’ve enhanced our Editor with:
- Support for tool calling and structured output; including template integrations for popular APIs and data sources.
- Improved UX with keyboard shortcuts and agent sessions.
- Side-by-side comparison mode so users can sense check performance across multiple different prompt versions.
- Local and org wide history for better auditing of changes.
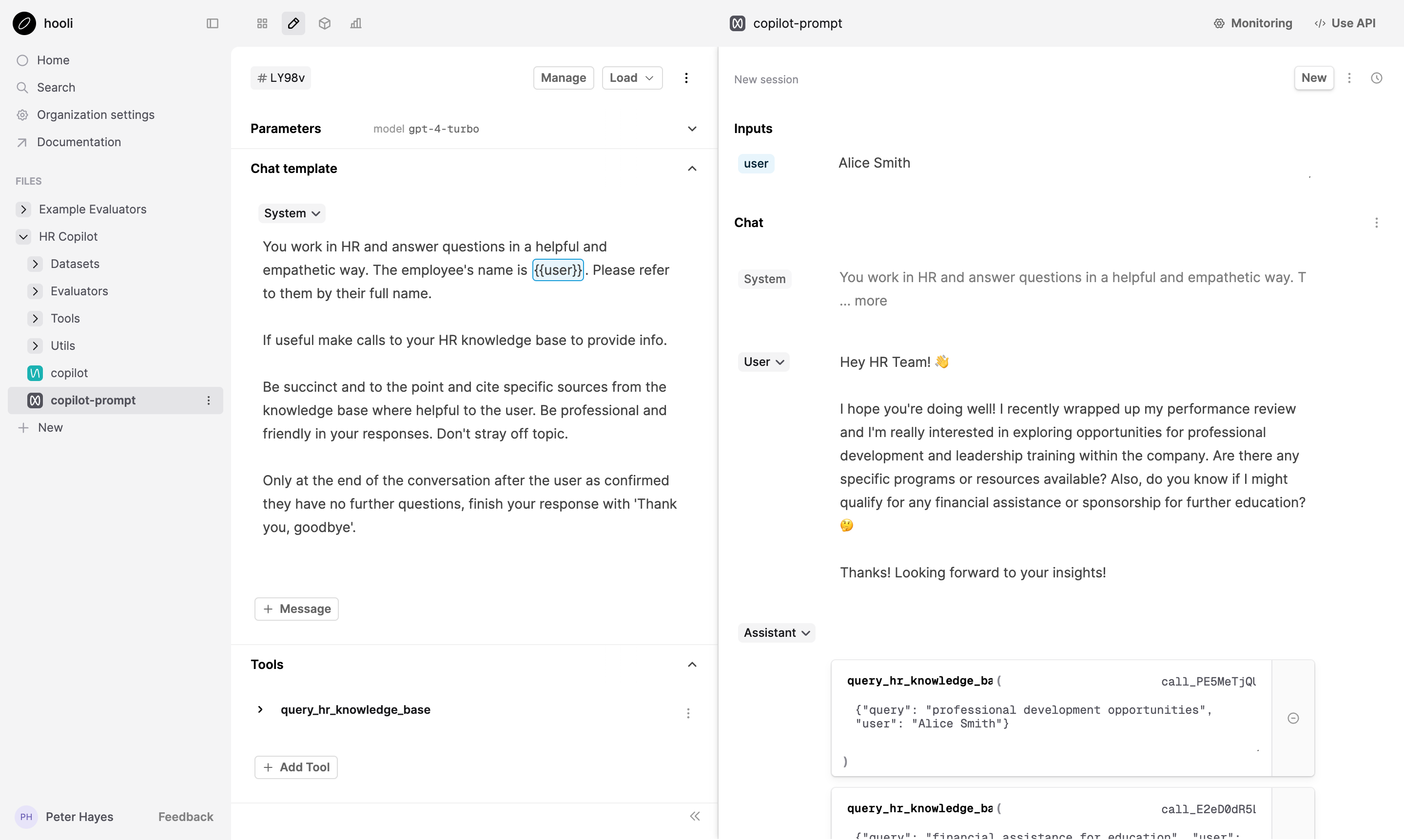
Model Proxy
Humanloop provides a unified interface across all the major model providers with our model proxy. This allows our users to easily experiment with the latest model versions as they're released, without having to change their integrations. Over the past year, we’ve integrated 8 model providers (covering both open and closed sourced models) and now maintain a same day SLA for adding new models released by the top providers. We’ve also shipped:
- A unified interface for tool calling across all providers, including Llama and AWS Bedrock variants.
- A registry of token costs across all model providers used to estimate usage costs for our users.
- Support for multi-modal inputs across providers.
- The ability to easily integrate a user’s custom models.
Read more here.
Complex Tracing
AI applications are generally multi-step and combine multiple Prompts and Tools in order to achieve a task, especially as things become increasingly agentic. We introduced another core concept on Humanloop called Flows in order to effectively support this, providing:
- Logging for the full execution trace of your application; giving you full visibility when debugging.
- SDK utilities, including an OpenTelemetry integration and decorators to easily instrument existing applications.
- Support for both end-to-end and component level evaluations.
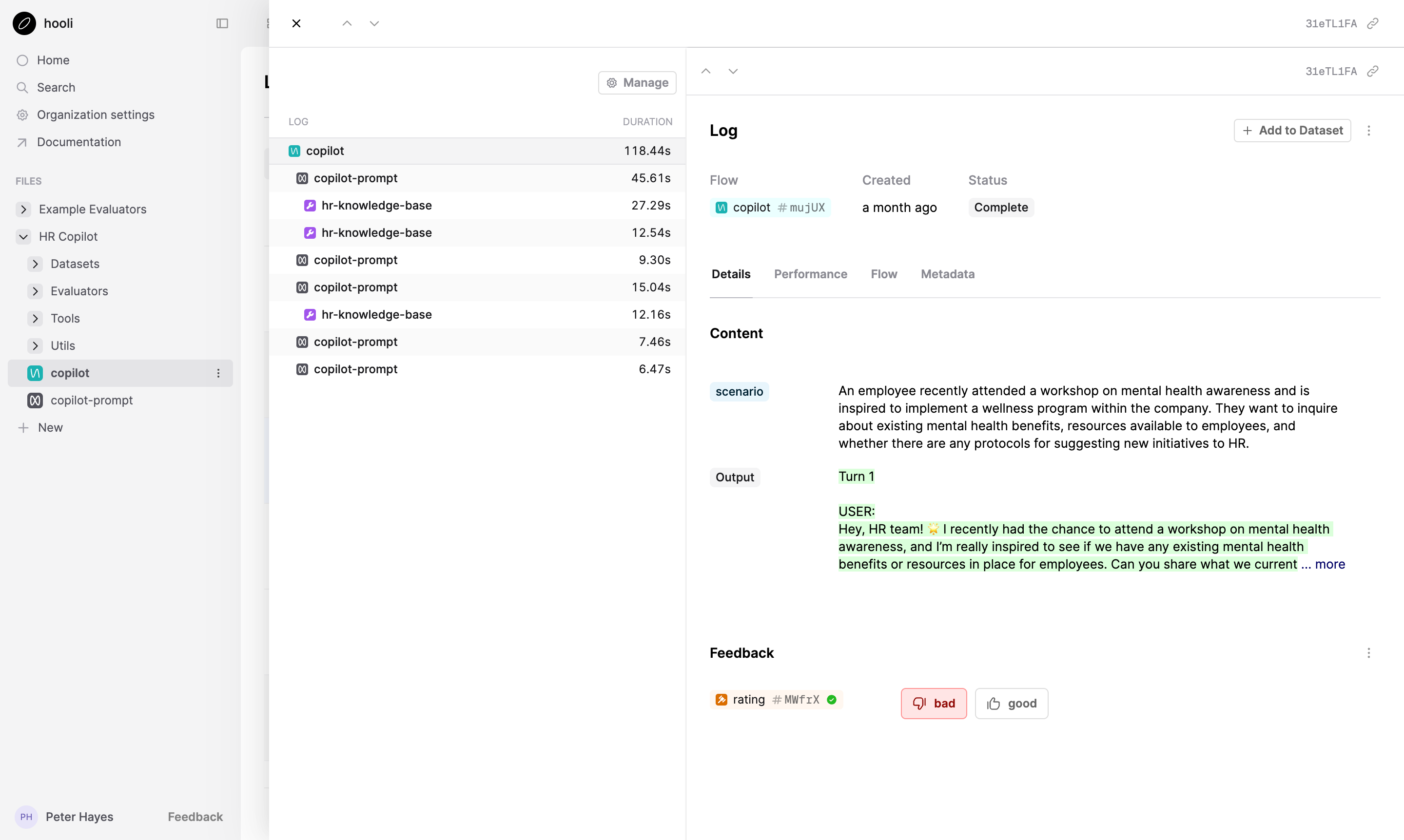
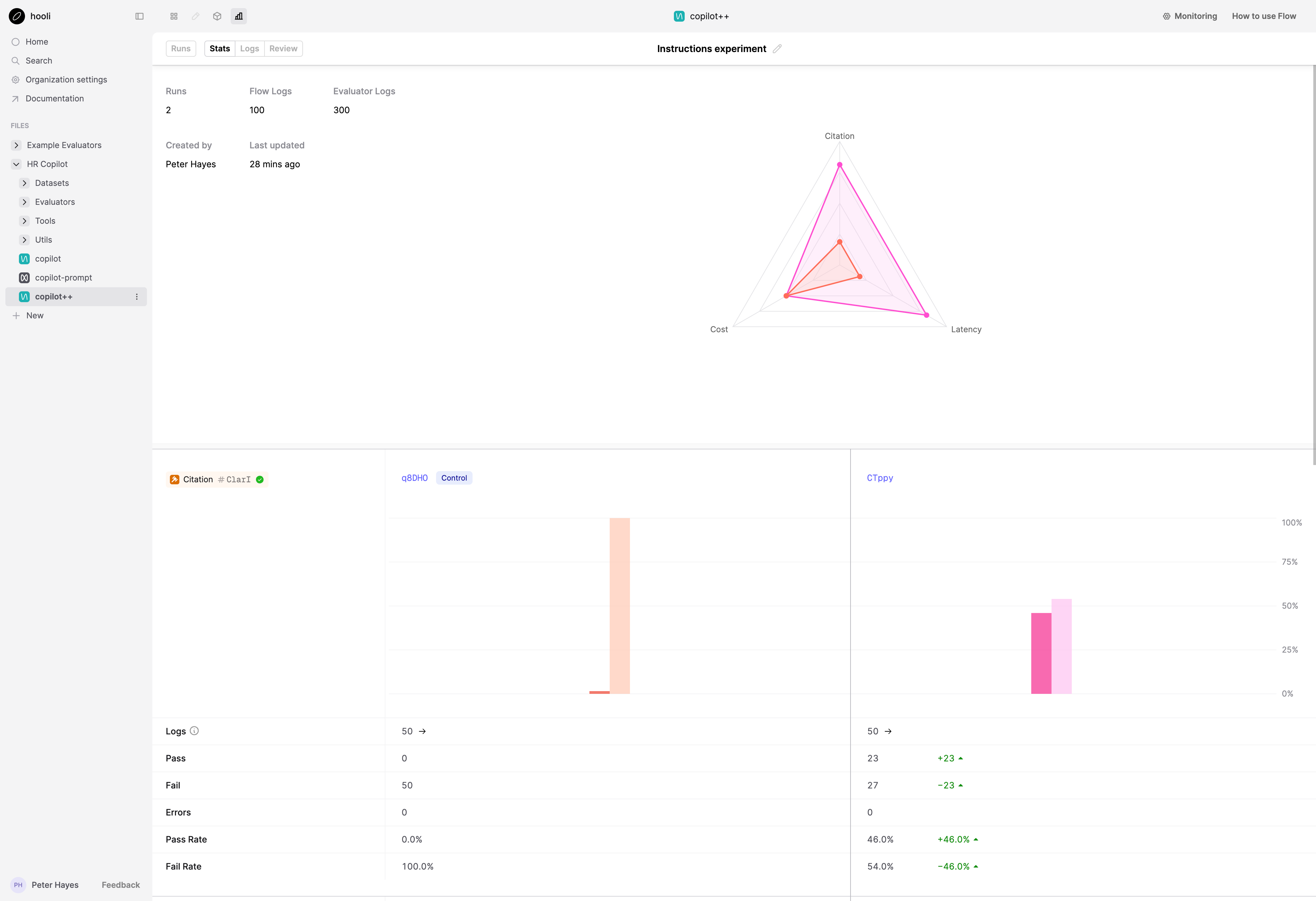
Evals
At the core of any robust AI development workflow are evals. Both for tracking improvements during offline experiments and for monitoring how your apps are performing in production. This is the area where we’ve probably invested most heavily over this period given the demands of our users, adding features like:
- Automatic cost, token and latency tracking.
- Support for LLM-as a judge, code and Human evals; with the ability to combine multiple criteria for monitoring in production and running offline experiments.
- New UI for seeing top level summary statistics and drilling in and replaying the underlying model interactions.
- Utilities for easily integrating evals into your CICD workflows for checking for regressions.
- Full Dataset management; including version control and multiple import/export methods.
- A new workflow for curating Datasets from interesting production logs to close the loop.
Human Review
Best-in-class AI features tend to have something in common: their teams figure out a way to leverage their subject-matter experts (SMEs) when evaluating and iterating. In order to better support Human review workflows, we’ve added:
- Customisable feedback schemas for setting up Human review workflows and improved views for SMEs to provide feedback.
- Workflows for easily spot checking production logs.
- The ability to delegate review tasks across your team.
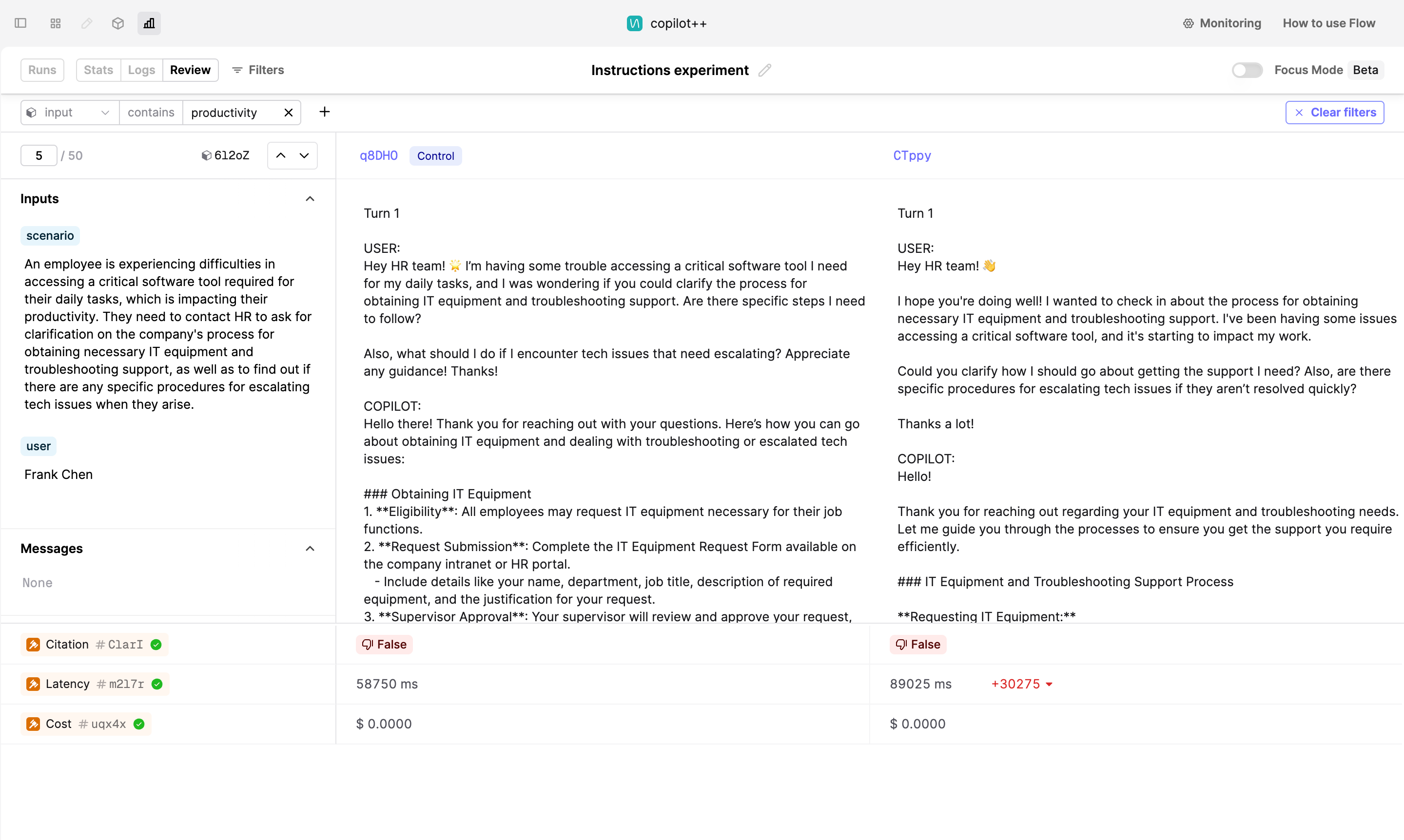
The year in numbers
To wrap up the review of how we’ve evolved over the last year or so, here are some quick highlights:
- Had over 300 production deployments culminating in 50 product releases.
- Added support for over 50 new LLM models.
- Are now processing millions of LLM logs daily across thousands of AI products deployed in production.
- Completed 4 successful external penetration tests maintaining our commitment to security.
This has all been made possible by our amazing Team! We’ve been lucky to assemble a great group that embodies our values of growth mindset and optimism about the future of AI. We’re actively hiring for product and engineering roles in London and SF, so get in touch!

About the author











