What is fine-tuning?
What is Fine-Tuning?
Fine-tuning is a way of taking a pre-trained neural network and customising it to improve its performance on a specific task. Fine-tuning has become important for building large language model (LLM) applications as, alongside prompt engineering, it’s one of two main ways to take a pre-trained LLM and adapt it for your use case.
In this blog, we’ll explain how to fine-tune a model in practice, the potential benefits of fine-tuning, and when to choose fine-tuning vs prompt engineering.
How Does Fine-Tuning Work?
At its core, the fine-tuning process leverages the learned knowledge embedded within a pre-trained model. This foundational model has been trained on large datasets, developing a generalized understanding of patterns in language or images (depending on the model's domain). Fine-tuning hones these capabilities for a specific task by further training the model on a smaller, task-specific dataset.
Benefits of Fine-Tuning
There are pros and cons of fine-tuning vs custom-training or prompt engineering. The biggest benefits are:
Improved Accuracy and Relevance
By specializing in pre-trained models for specific tasks, you can significantly enhance the accuracy and relevance of output. This leads to a better user experience and more impactful outcomes.
Reduced Development Costs
Fine-tuning eliminates the extensive time and resource investment required to train large-scale models from scratch. This can help achieve tailored performance without incurring the substantial expenses associated with full model development.
Enhanced Data Efficiency
Fine-tuning often requires smaller amounts of labeled data compared to training from scratch. This is particularly valuable for enterprises dealing with niche domains or scenarios where data collection is expensive or time-consuming.
Customization and Competitive Edge
Fine-tuning enables you to customise pre-trained models for unique use cases, giving them an edge over competitors who may rely solely on generic off-the-shelf models.
Speed
Fine-tuned models can be much smaller than foundation models as they only need to be good at one specific task. As a result they can have much lower latency and cost than foundation models for the same accuracy or performance.
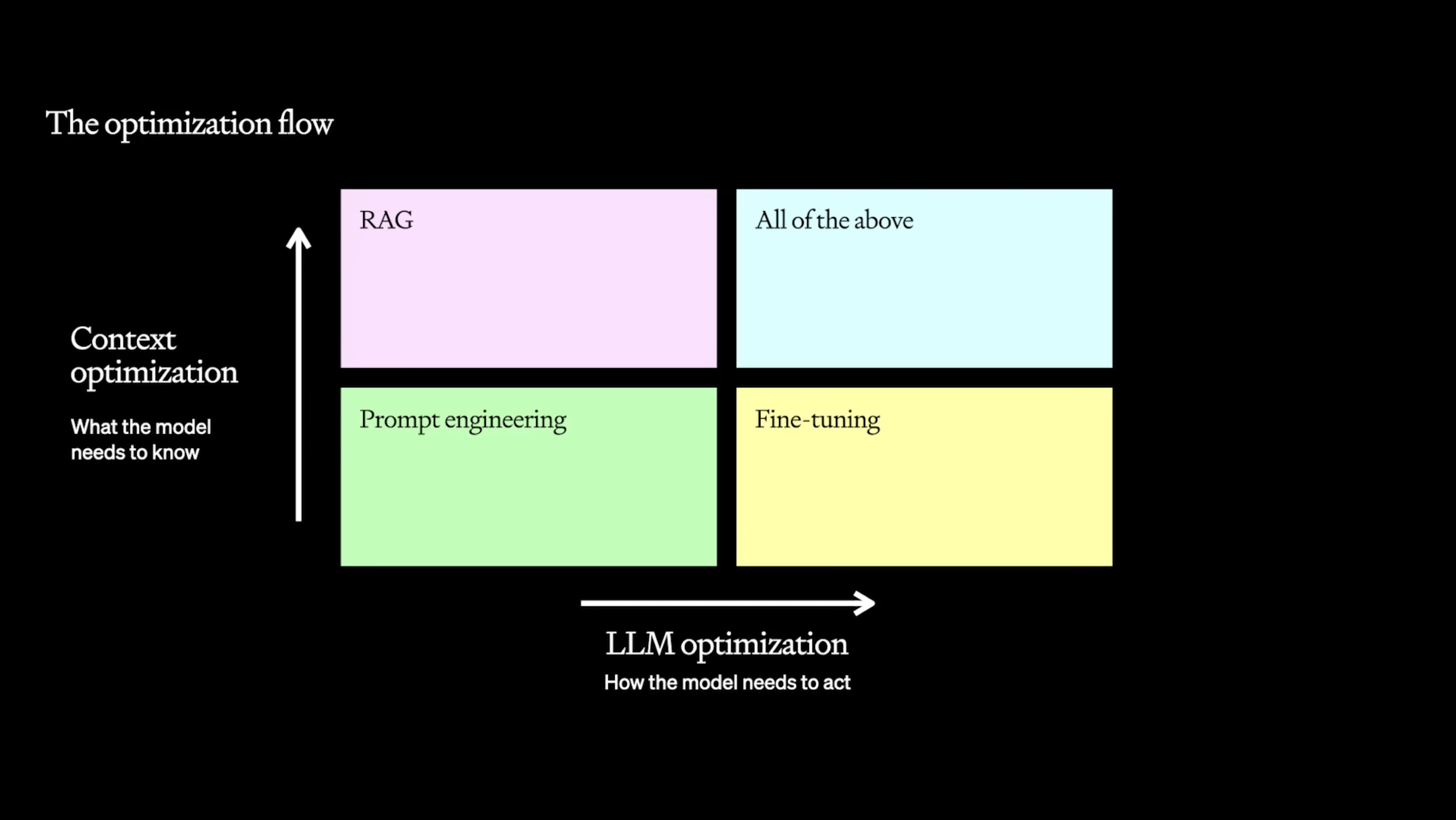
For large language models, many of these same benefits can be achieved with prompt engineering. Fine-tuning typically involves a lot more work, is slower to update and requires more machine learning expertise. For these reasons, we typically advise to first push the limits of prompt engineering before considering fine-tuning.
The main scenarios where you would want to finetune are in situations where it's easier to communicate what you want with examples than with language. Such as:
- Increasing consistency of formatting
- Capturing a particular tone of voice
- Handling edge cases
Or when cost and latency are big concerns. In this case fine-tuning can allow you to transfer knowledge from a big general purpose model to a small task specific model.
Why is Fine-Tuning Important?
Fine-tuning LLMs is crucial because it's the key to unlocking their true potential in specific domains. It's like taking a Swiss Army knife and honing one of its blades to a razor-sharp edge for a particular task. This process allows companies to differentiate their AI offerings, creating moats in specific verticals or use cases. Fine-tuning isn't just about improving performance; it's about creating unique AI products that can drive business value in ways that off-the-shelf models simply can't match. It's the difference between a generic chatbot and a specialized assistant that truly understands your industry's jargon, regulations, and nuances. In the AI arms race, fine-tuning is the secret weapon that turns raw language models into strategic assets, enabling businesses to carve out defensible niches.
Retrieval Augmented Generation (RAG) vs Fine-Tuning
In situations where improving large language model (LLM) performance requires the model to have context to additional data, we recommend that you start with Retrieval Augmented Generation (RAG). RAG is a method in LLM application development that dynamically integrates data from external sources into the context window to enhance the generation process. Fine-tuning may be used later as a optimization technique to improve speed, low cost or enhance reliability. To learn more about RAG vs fine-tuning, read our comprehensive guide on how to maximize LLM performance.
How to Fine-Tune a Large Language Model (LLM)
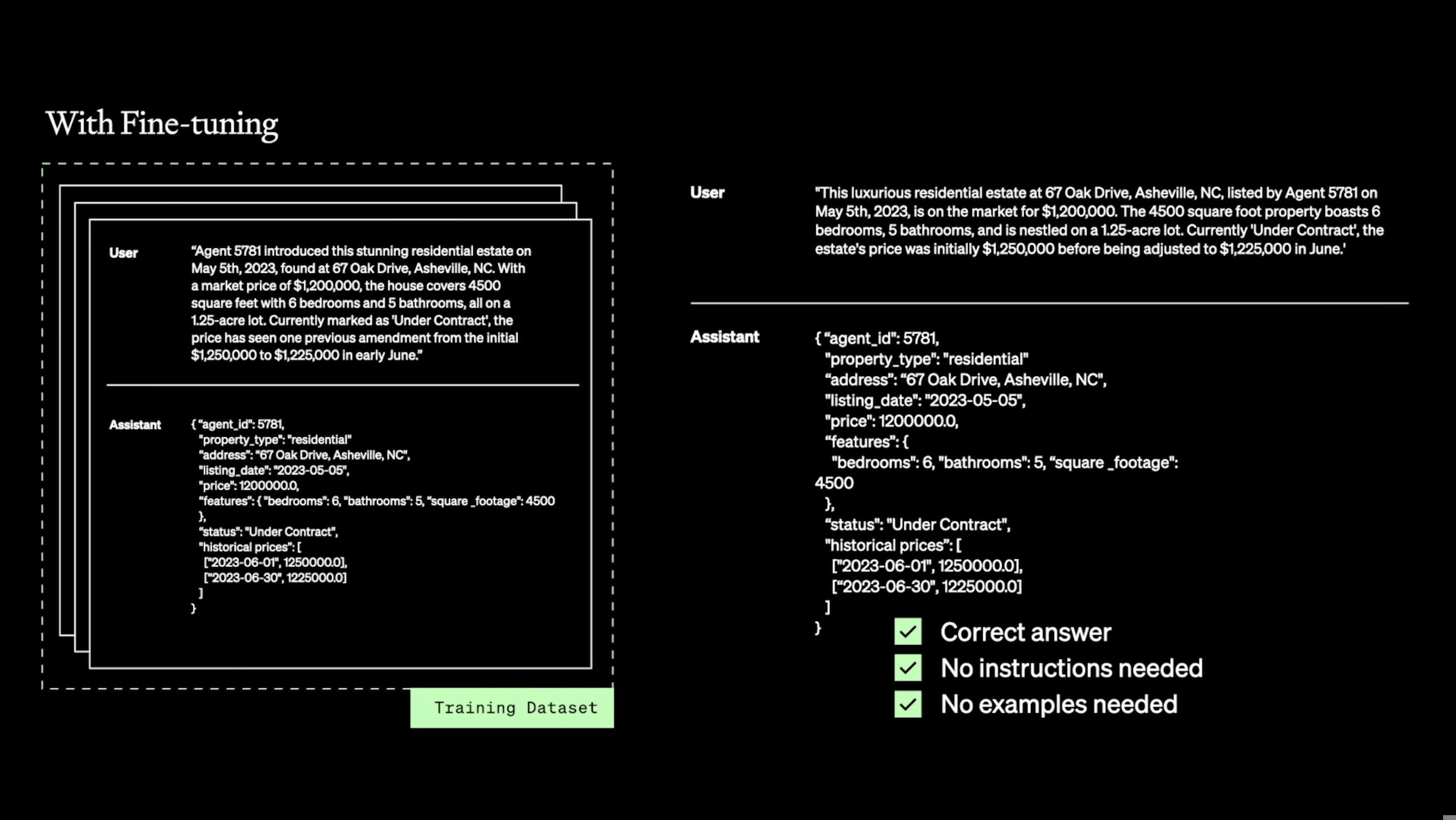
To fine-tune a large language model you’ll first need a pre-trained base model and a dataset of input-output pairs that are representative of the task you want the model to perform. For example, if you want the model to be good at question answering, you’ll need a data set of questions and answers. If you want to do summarization, you’ll need a dataset of long documents paired with their summaries. The larger the dataset and the closer it is to the types of inputs the model will see in production, the better the results will be. In practice when fine-tuning GPT-4o or other prominent LLMs, a few 100 data points is often sufficient.
Preparing Your Data
How you prepare your data will depend a lot on the type of model you’re fine-tuning. If you want to fine-tune a language model then it’s common practice to present the data in the format of a conversation.
For example the OpenAI fine-tuning API expects each example to be a conversation in the same format as their Chat Completions API, which is a list of messages where each message has a role, content, and optional name. Most other LLMs applications will require data in a similar format if training a conversational model. The same principles apply to other data modalities like images or audio.
Here’s an example of what a few data points for fine-tuning an LLM might look like:
[
{
"messages": [
{
"role": "system",
"content": "You are TravelBuddy, a helpful and slightly humorous travel recommendation chatbot."
},
{ "role": "user", "content": "What's a good place to visit in Italy?" },
{
"role": "assistant",
"content": "Ah, Italy! The land where pasta flows like water and hand gestures are a second language. You can't go wrong with Rome - it's like a giant open-air museum where you can trip over ancient history while hunting for the perfect gelato. Just watch out for those Vespa drivers, they think they're in 'Fast and Furious: Colosseum Drift'."
}
]
},
{
"messages": [
{
"role": "system",
"content": "You are TravelBuddy, a helpful and slightly humorous travel recommendation chatbot."
},
{
"role": "user",
"content": "I'm planning a beach vacation. Any suggestions?"
},
{
"role": "assistant",
"content": "Beach vacation, eh? Trying to achieve that 'lobster red' look? Bali is fantastic if you want to combine sun, surf, and the occasional monkey stealing your sunglasses. For a closer-to-home option, Hawaii is great. It's like a postcard come to life, but with better Wi-Fi. Just remember, no matter where you go, sand will find its way into places you didn't even know you had."
}
]
},
{
"messages": [
{
"role": "system",
"content": "You are TravelBuddy, a helpful and slightly humorous travel recommendation chatbot."
},
{ "role": "user", "content": "What should I pack for a trip to Alaska?" },
{
"role": "assistant",
"content": "Ah, Alaska! Where the mosquitoes are the size of small aircraft and the bears consider humans to be walking appetizers. Pack layers, lots of layers. Think onion, but less smelly. Bring a good camera to capture the Northern Lights, and maybe some night vision goggles to spot your tent after dark. Oh, and don't forget bear spray - it's like deodorant, but for survival!"
}
]
}
]
Training the Large Language Model
Once you’ve prepared the data, the next step is to further train your base model on your dataset. For cloud hosted LLMs there are fine-tuning APIs that will take care of this step for you. Otherwise libraries like HuggingFace Transformers or fast.ai provide utilities for fine-tuning on your own dataset.
There are several different approaches to how much of the original model to actually adapt. You want to preserve the relevant knowledge from the models pre-training and minimize the amount of compute needed. Neural networks are composed of layers of artificial neurons that gradually refine the input at each stage. Earlier layers learn simple more generic features and later layers are more task specialized.
-
Fine-Tuning All Layers: In this scenario, all layers of the pre-trained model are updated during the fine-tuning process. This approach is often suitable when your dataset is significantly different from the data the model was originally trained on. The downside is that for large models this can be very computationally expensive and can cause the model to forget its pre-training.
-
Freezing Layers: One approach to solving these problems is to keep the original network fixed apart from the final layers of the network. This allows you to adapt the model to your task at much lower computational cost and preserve more of the original model.
-
Low Rank fine-tuning and Adaptors (LoRA): In many use cases you might want to have many versions of a model for different audiences or small variations of task. Low Rank Adaptors (LoRa) augment the existing model with a small number of new parameters and leave the entire original model unchanged. LoRa fine-tuning can be much more computationally and memory efficient than full fine-tuning but the amount you’re able to adjust the model is reduced.
Key Steps to Consider When Fine-Tuning an LLM
Fine-tuning typically necessitates a lower learning rate than the original model training. This helps to carefully adjust the existing weights and biases without drastically overwriting the knowledge gained during pre-training.
Here’s an outline of the key steps:
1. Model Selection
Strategically choose a pre-trained model aligned with your task and its complexity. Consider the model's architecture, its original training domain, and its size. Enterprises often find large-scale models— like OpenAI's GPT series for text tasks, or a ResNet pre-trained on ImageNet for image classification— well-suited as a foundation for customization. OpenAI's models provide a powerful baseline, and you can find comprehensive guides for fine-tuning GPT-3.5.
2. Data Preparation
Meticulously curate a high-quality dataset tailored to your specific use case. Ensure the data distribution aligns with real-world scenarios the model will encounter, addressing potential biases in the process. Pay attention to label accuracy, formatting consistency, and data volume.
Tip: Utilize data augmentation techniques, particularly with smaller datasets, to expand and diversify your training data, improving the model's robustness.
3. Fine-Tuning Configuration:
-
Select Layers: Determine the layers to fine-tune. For simple adaptations, you might freeze the initial layers and focus on the final few. For more significant divergences from the original training domain, fine-tuning all layers may be necessary. Gradual unfreezing offers a nuanced approach.
-
Learning Rate: Opt for a lower learning rate than the original training. Experimentation is key – try various smaller learning rates and potentially learning rate schedules.
-
Hyperparameters: Set appropriate hyperparameters like batch size, the number of training epochs, and optimization algorithms.
4. Train and Monitor
Initiate the fine-tuning process while tracking crucial performance metrics on a held-out validation set. This monitoring is key to identifying overfitting or underfitting, allowing you to adjust your strategy.
Tip: Consider utilizing specialized machine learning frameworks like Hugging Face Transformers to simplify fine-tuning workflows and streamline hyperparameter management.
5. Evaluation
Once fine-tuning is complete, conduct a thorough evaluation of the model on a representative test set. This evaluation should align with your key business metrics and determine whether the model's performance is suitable for deployment.
Fine-Tuning with Humanloop
Humanloop's platform helps you build a data asset from your customers and use that data to fine-tune models and improve their experience. We make it easy for you to log production data and augment it with human feedback and automated evaluations.
Once you have this rich dataset augmented with targeted feedback, you can find the subsets of the data that lead to the best outcomes for your customers and use them as the input dataset for finetuning. Humanloop offers native fine-tuning support directly on the platform and makes it easy to export your dataset in a format that’s appropriate for finetuning your own models.
Get More Advice on Fine-Tuning
If you'd like to learn more about how Humanloop can help your teams collaborate on LLM application development, evaluate model performance or use production data to fine-tune models, book a demo with our team.
About the author

- 𝕏@RazRazcle










