Compare and Debug Prompts
In this guide, we will walk through comparing the outputs from multiple Prompts side-by-side using the Humanloop Editor environment and using diffs to help debugging.
You can compare Prompt versions interactively side-by-side to get a sense for how their behaviour differs; before then triggering more systematic Evaluations. All the interactions in Editor are stored as Logs within your Prompt and can be inspected further and added to a Dataset for Evaluations.
Prerequisites
- You already have a Prompt — if not, please follow our Prompt creation guide first.
Compare Prompt versions
In this example we will use a simple support agent Prompt that answers user queries about Humanloop’s product and docs.
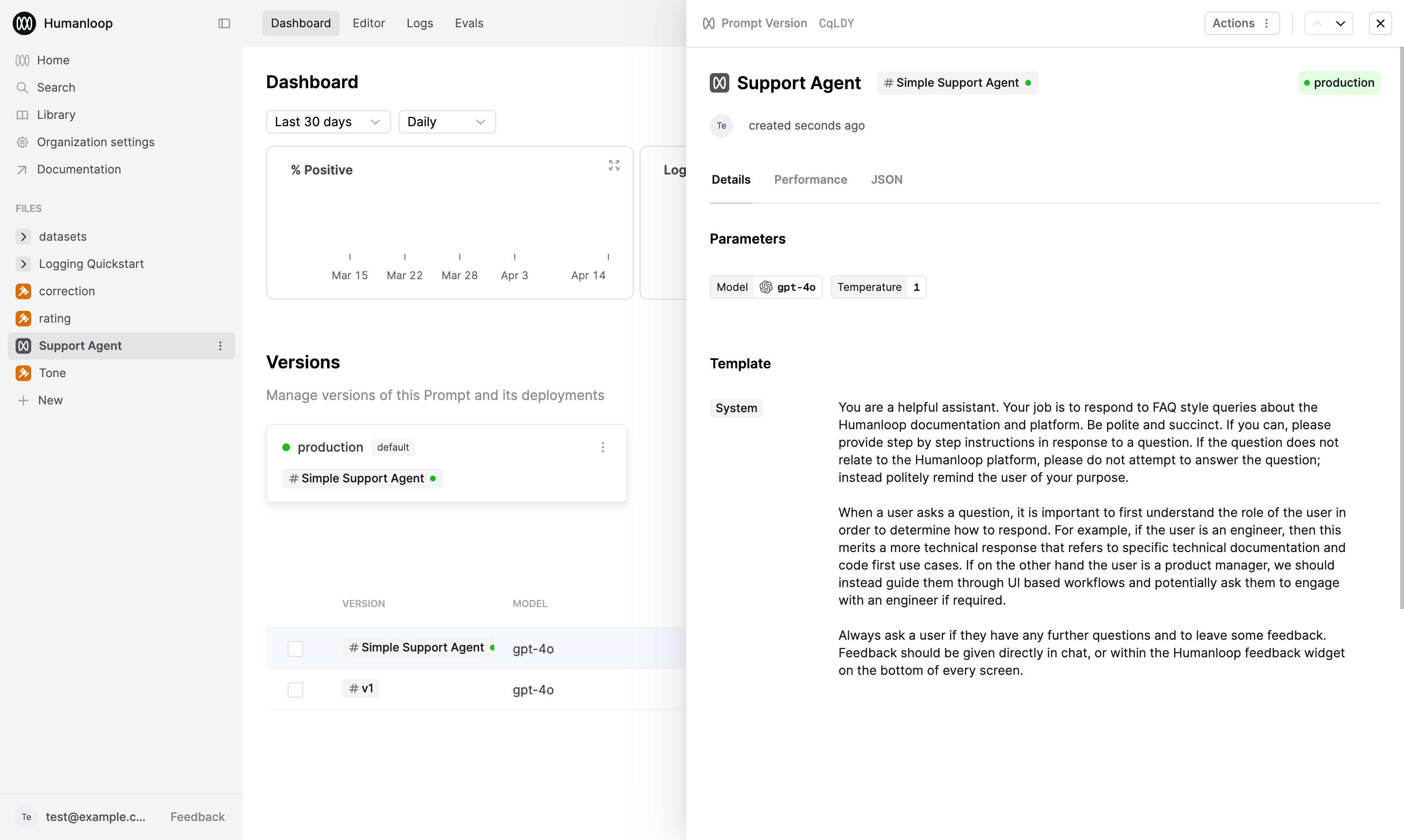
Create a new version of your Prompt
Open your Prompt in the Editor. Under Parameters, change some details such as the choice of Model.
In this example, we change from gpt-4o to gpt-4o-mini.
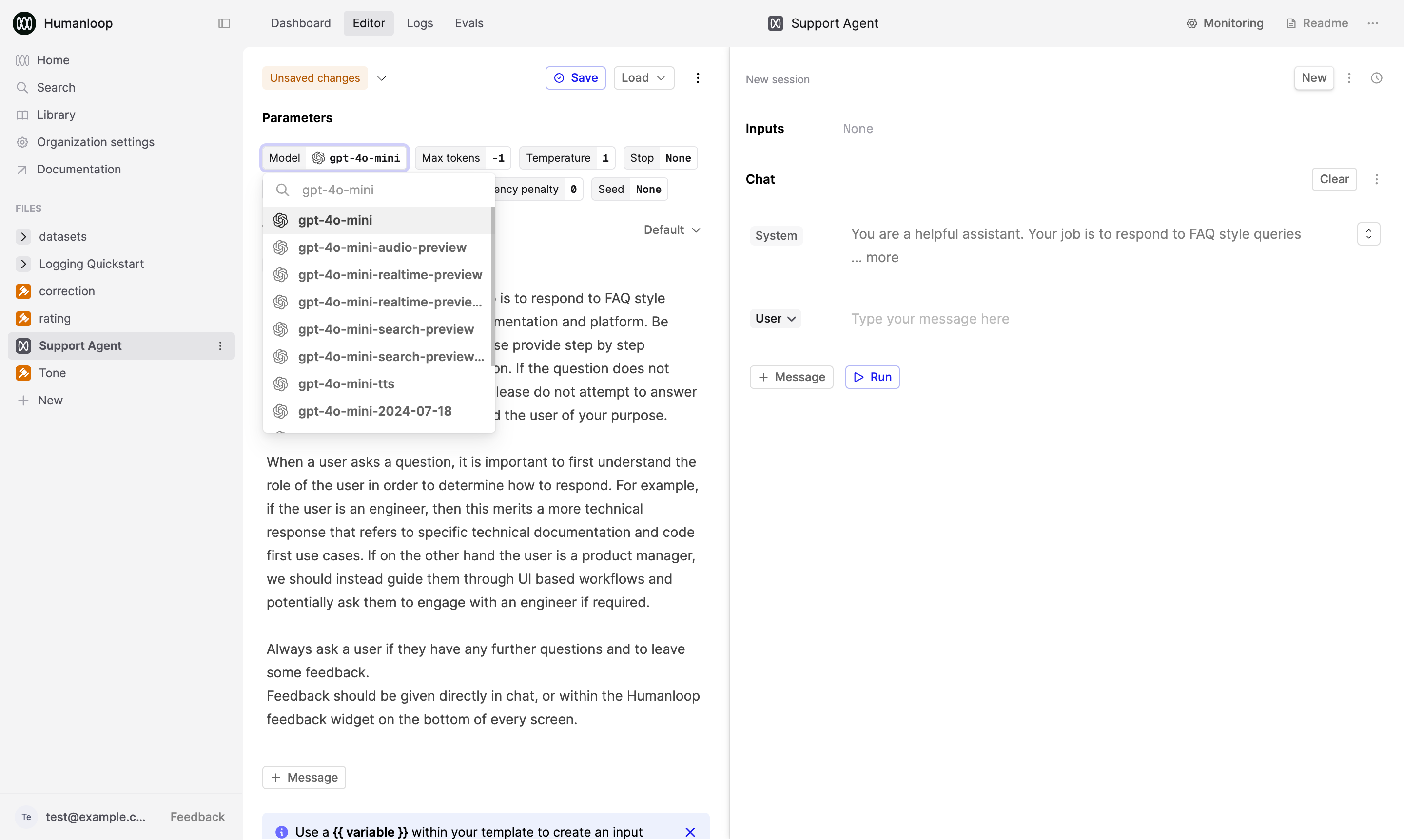
Now save the new version of your Prompt by selecting the Save button in the top right and optionally provide a helpful version name (e.g. “Simple Support Agent v2”) and/or description (e.g. “Changed model to gpt-4o-mini”).
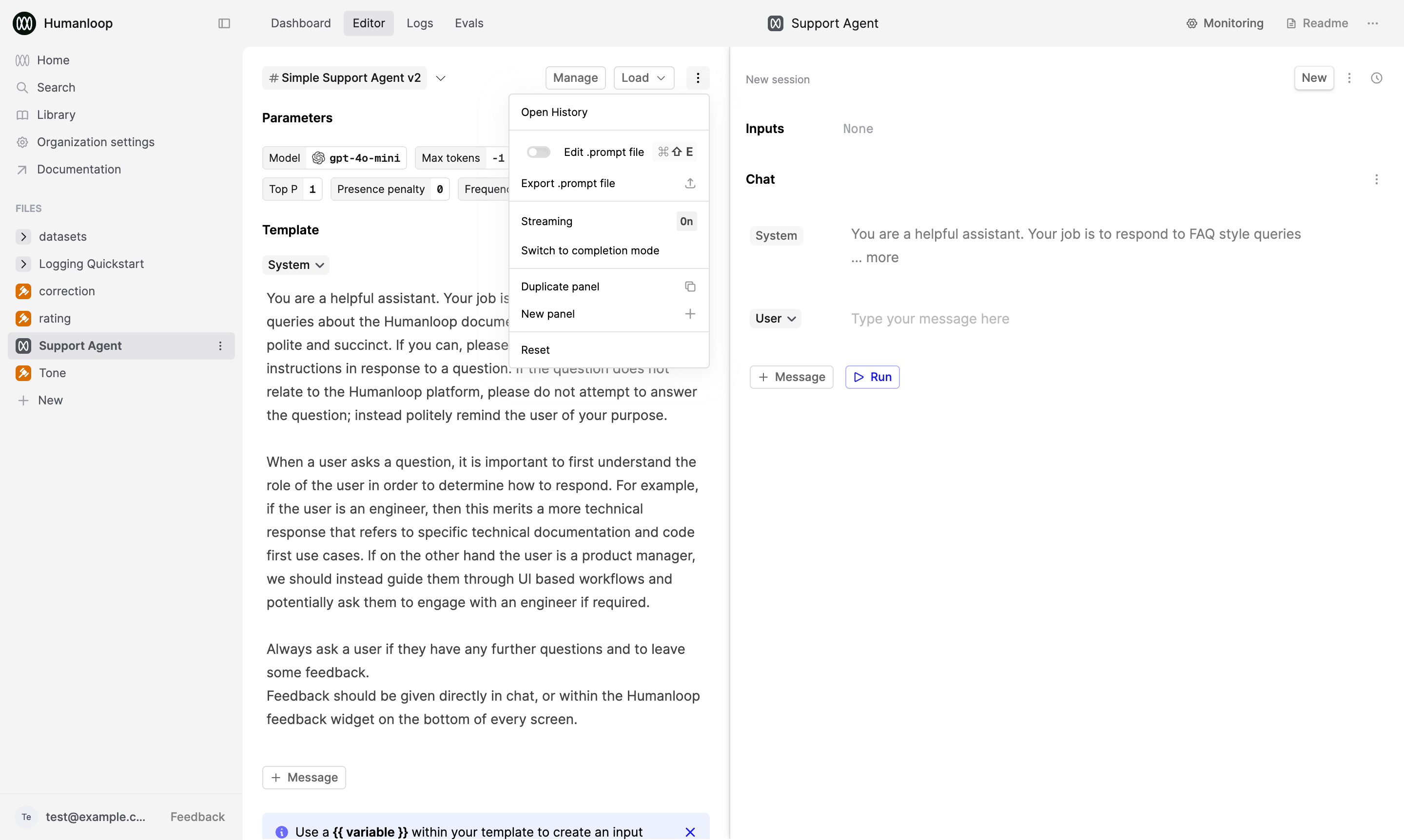
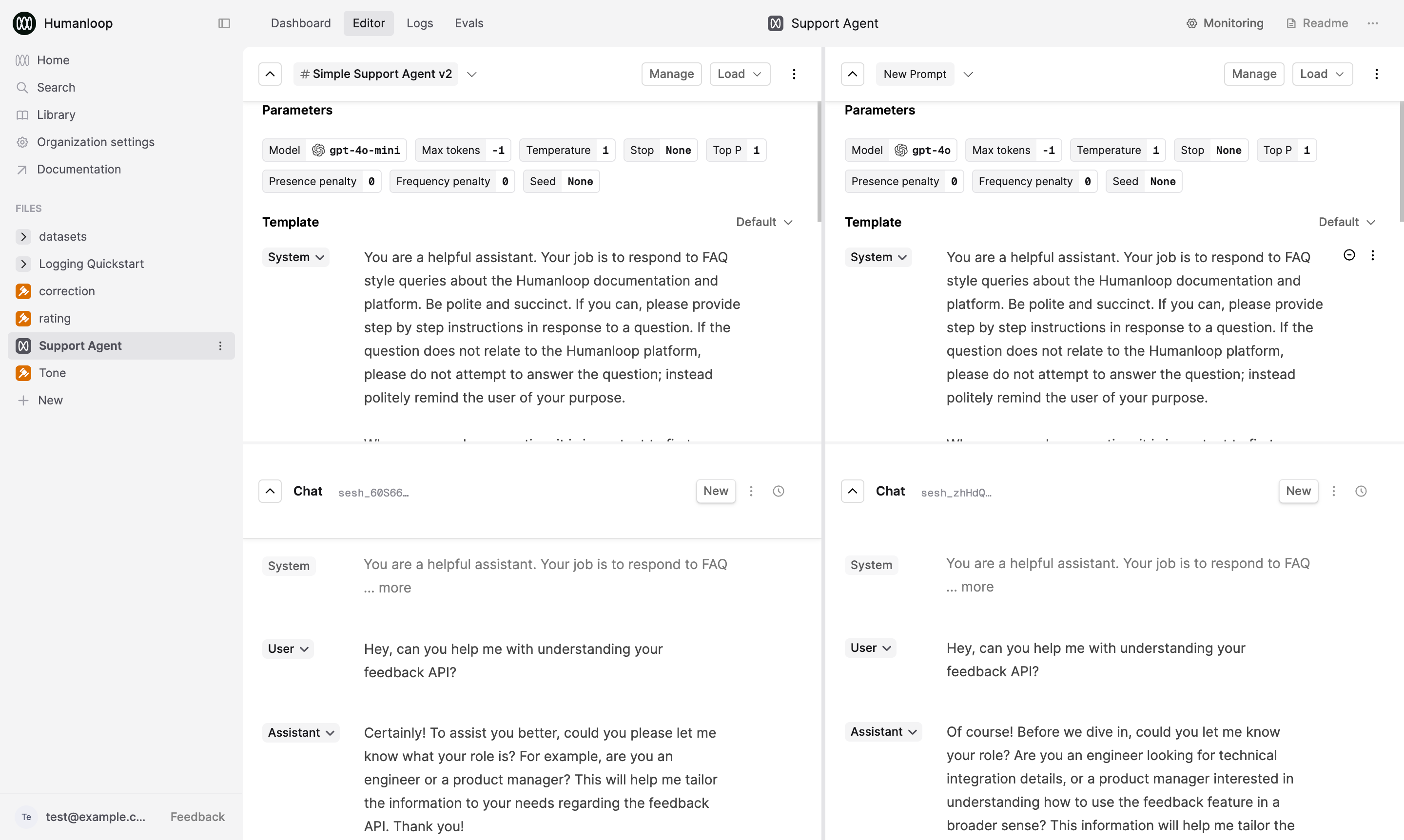
Load up two versions of your Prompt in the Editor
To load up the previous version side-by-side, select the menu beside the Load button and select the New panel option (depending on your screen real-estate, you can add more than 2 panels).
Then press the Load button in the new panel and select another version of your Prompt to compare.
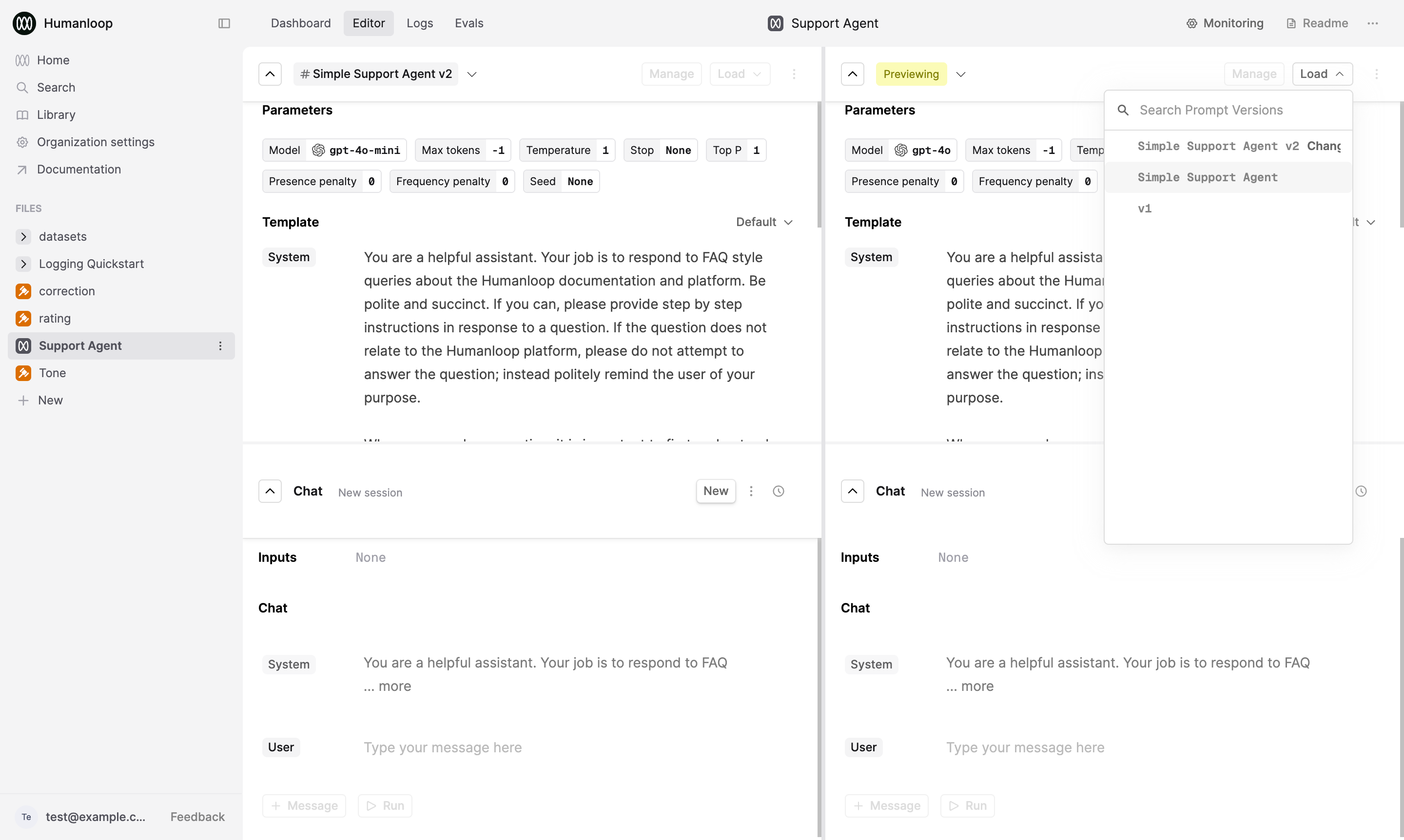
View Prompt diff for debugging
When debugging more complex Prompts, it’s important to understand what changes were made between different versions. Humanloop provides a diff view to support this.
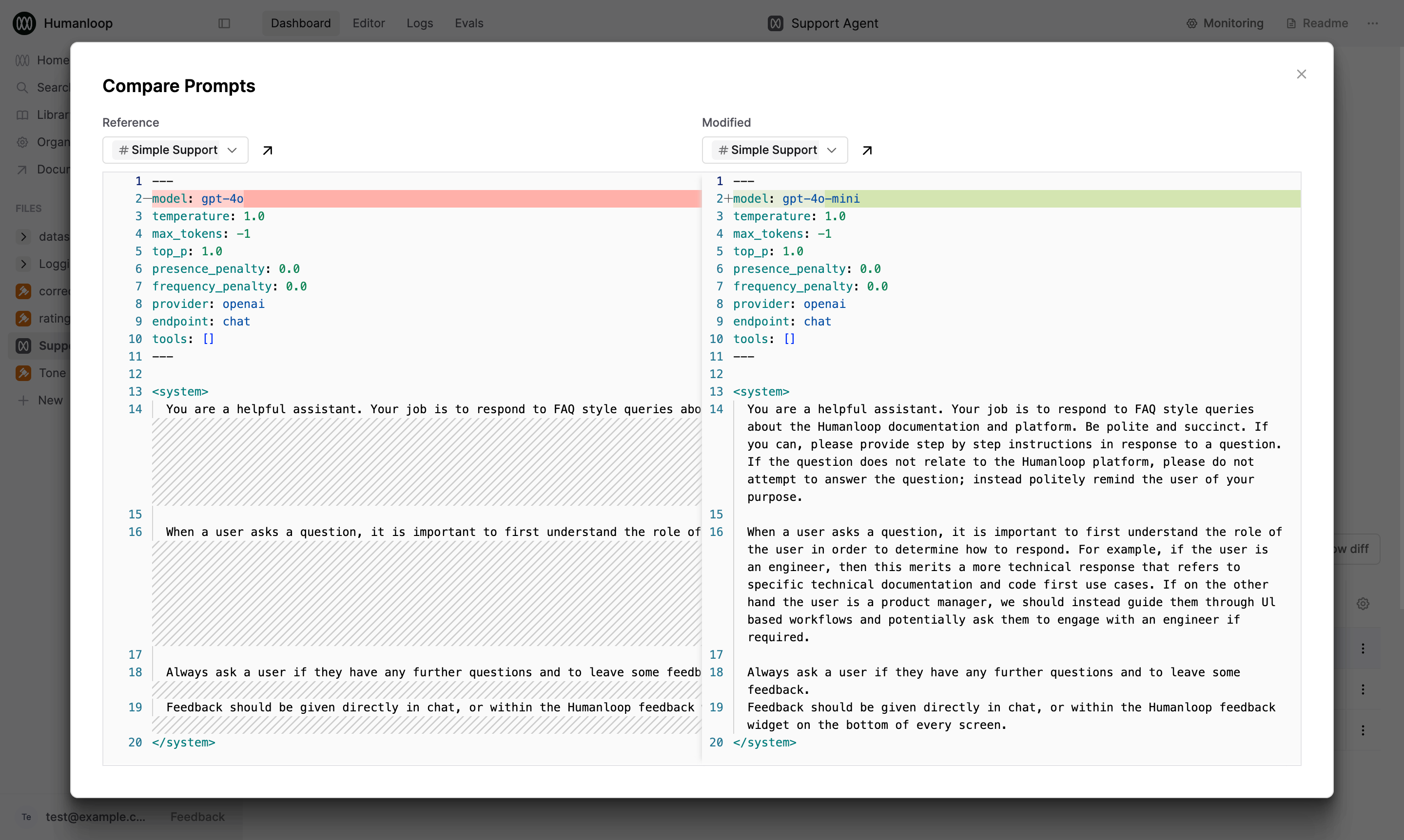
- In the comparison view, you’ll see a diff that highlights the changes between the selected versions.
- The diff shows additions in green and deletions in red. Modified content appears as a combination of red (for removed text) and green (for added text).
- Use this view to understand how specific changes affect the output.
By following these steps, you can effectively compare different versions of your Prompts and iterate on your instructions to improve performance.