ChatGPT clone with streaming
At the end of this tutorial, you’ll have built a simple ChatGPT-style interface using Humanloop as the backend to manage interactions with your model provider, track user engagement and experiment with model configuration.
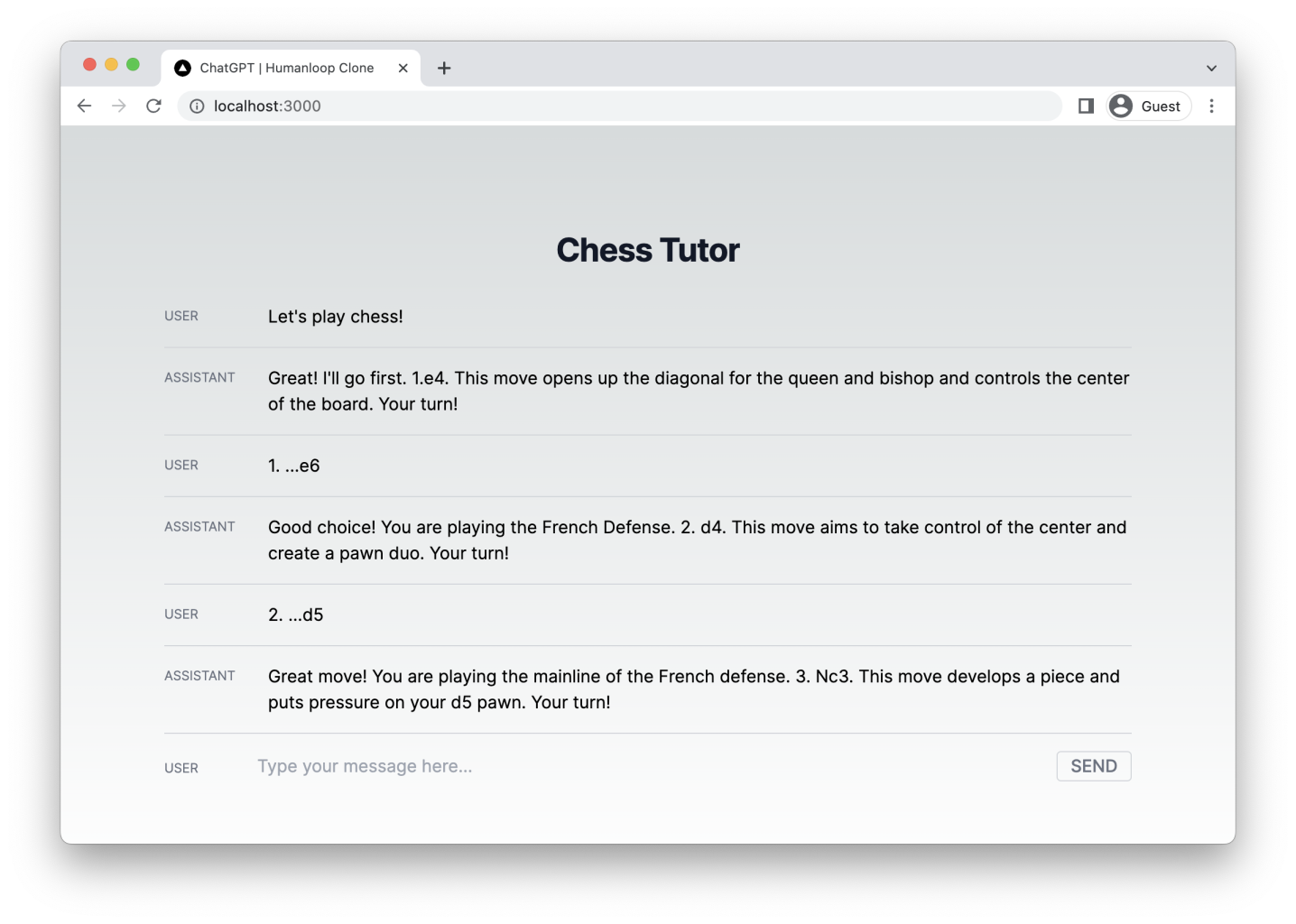
Step 1: Create a new Prompt in Humanloop
First, create a Prompt with the name chat-tutorial-ts. Go to the Editor tab on the left. Here, we can play with parameters and prompt templates to create a model which will be accessible via the Humanloop SDK.
Model Provider API keys
If this is your first time using the Prompt Editor, you’ll be prompted to enter an OpenAI API key. You can create one by going here.
The Prompt Editor is an interactive environment where you can experiment with prompt templates to create a model which will be accessible via the Humanloop SDK.
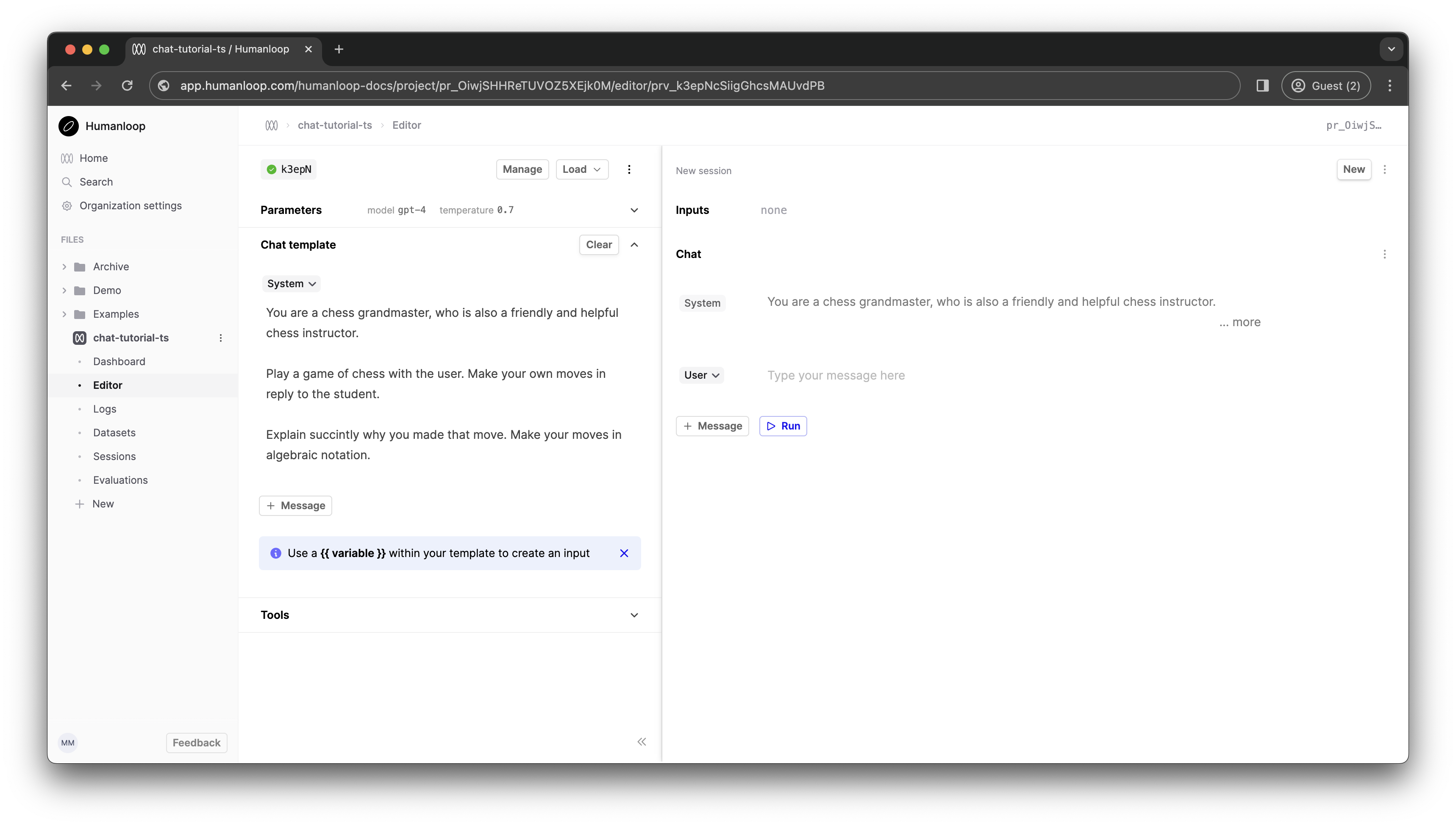
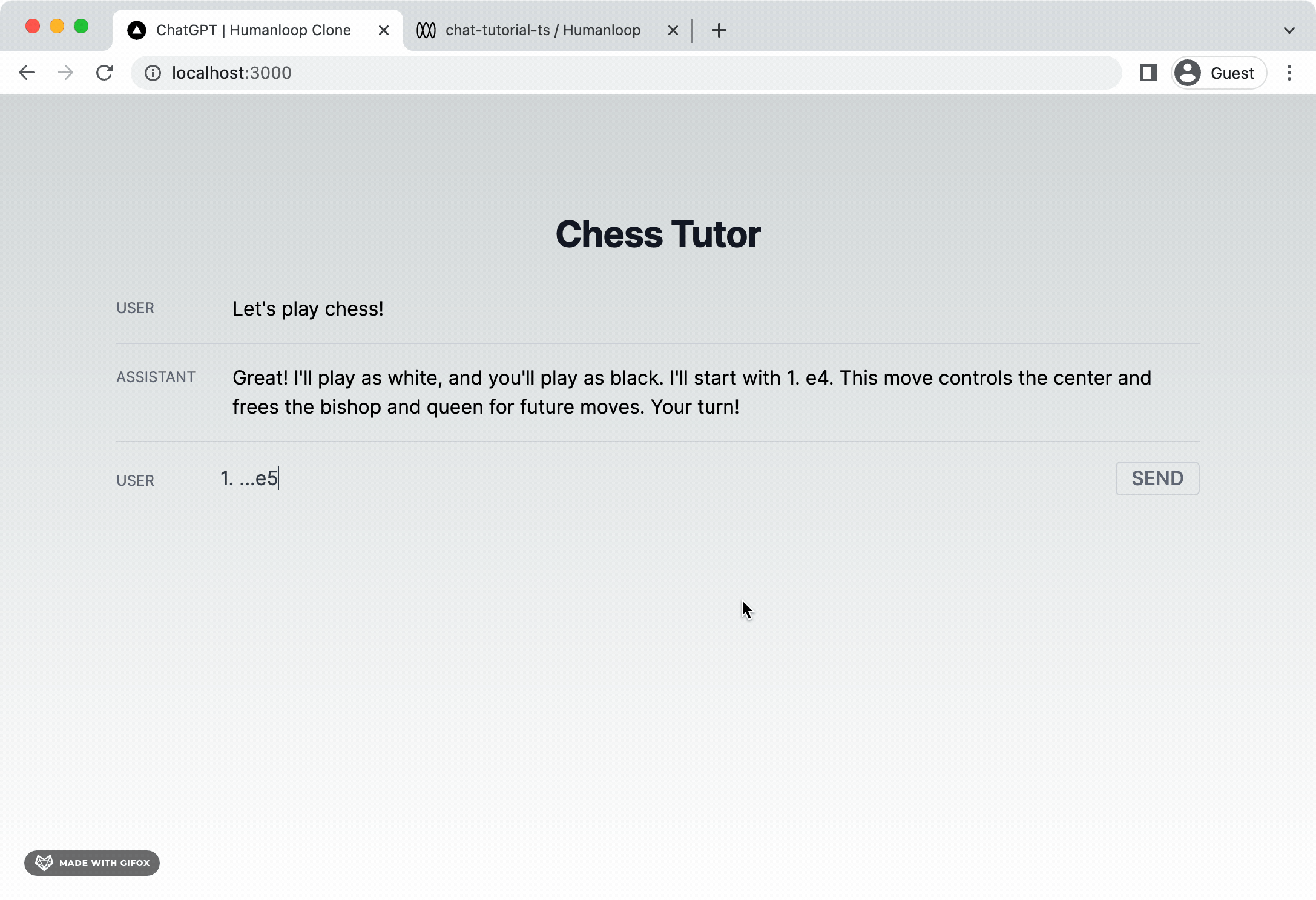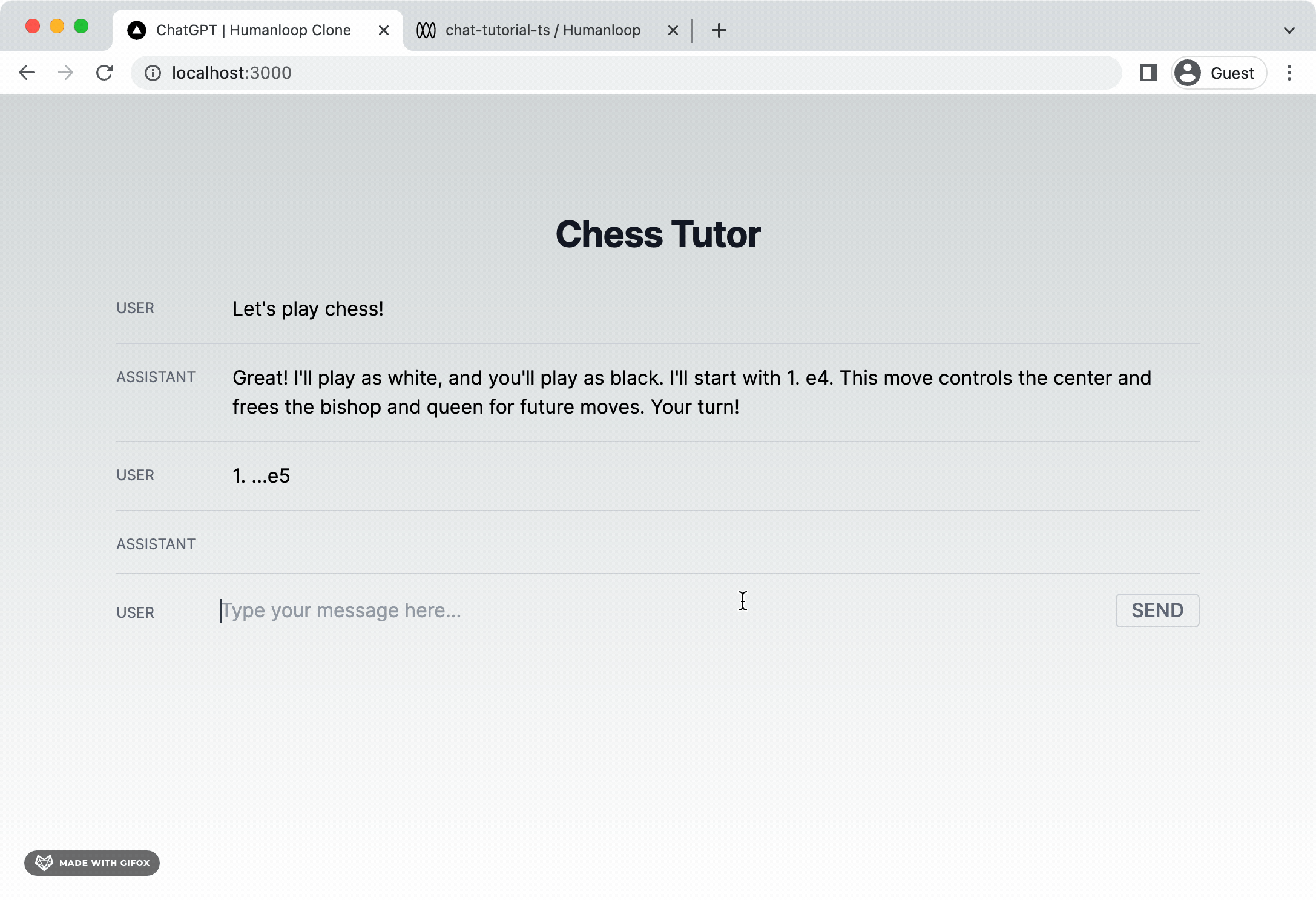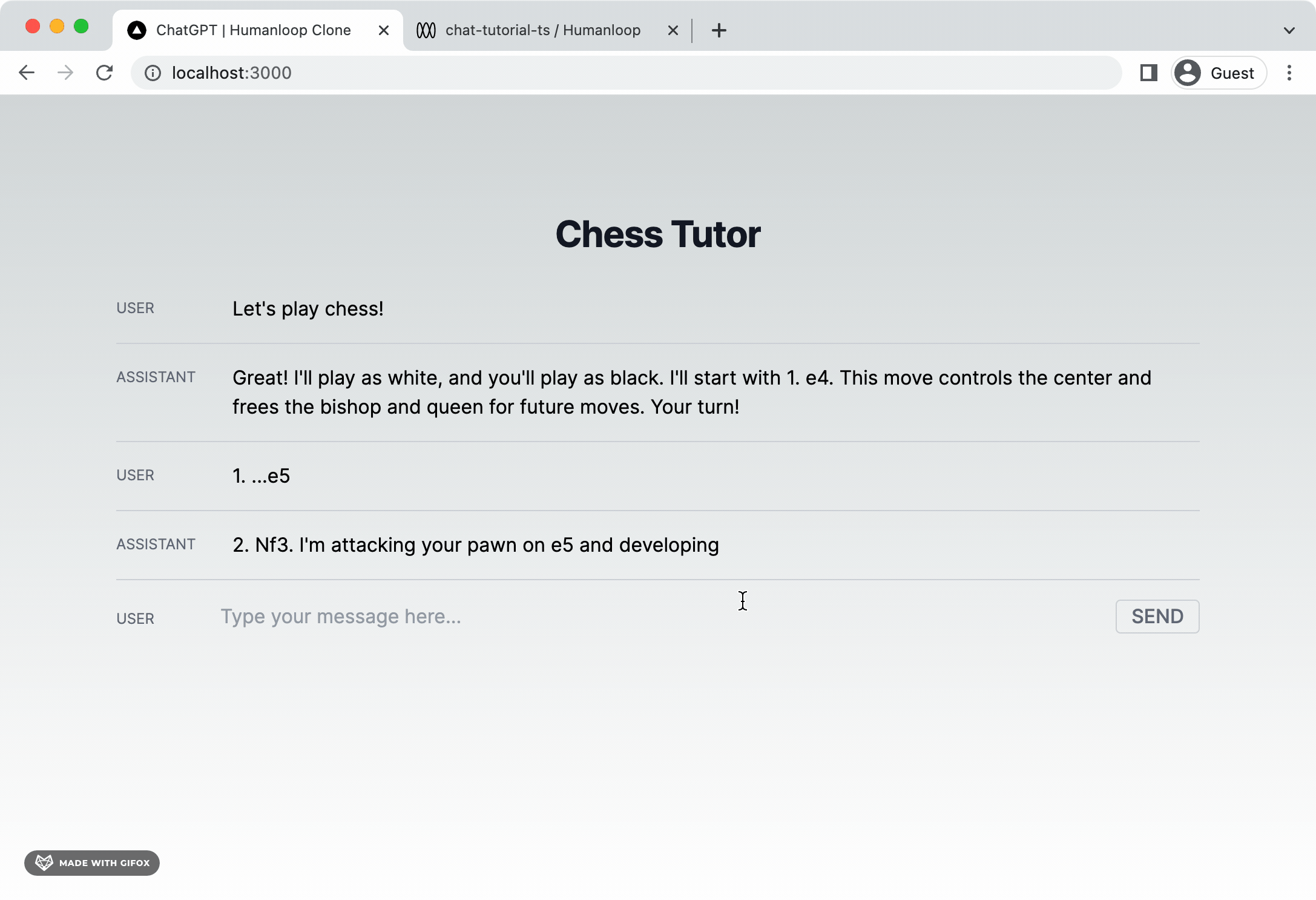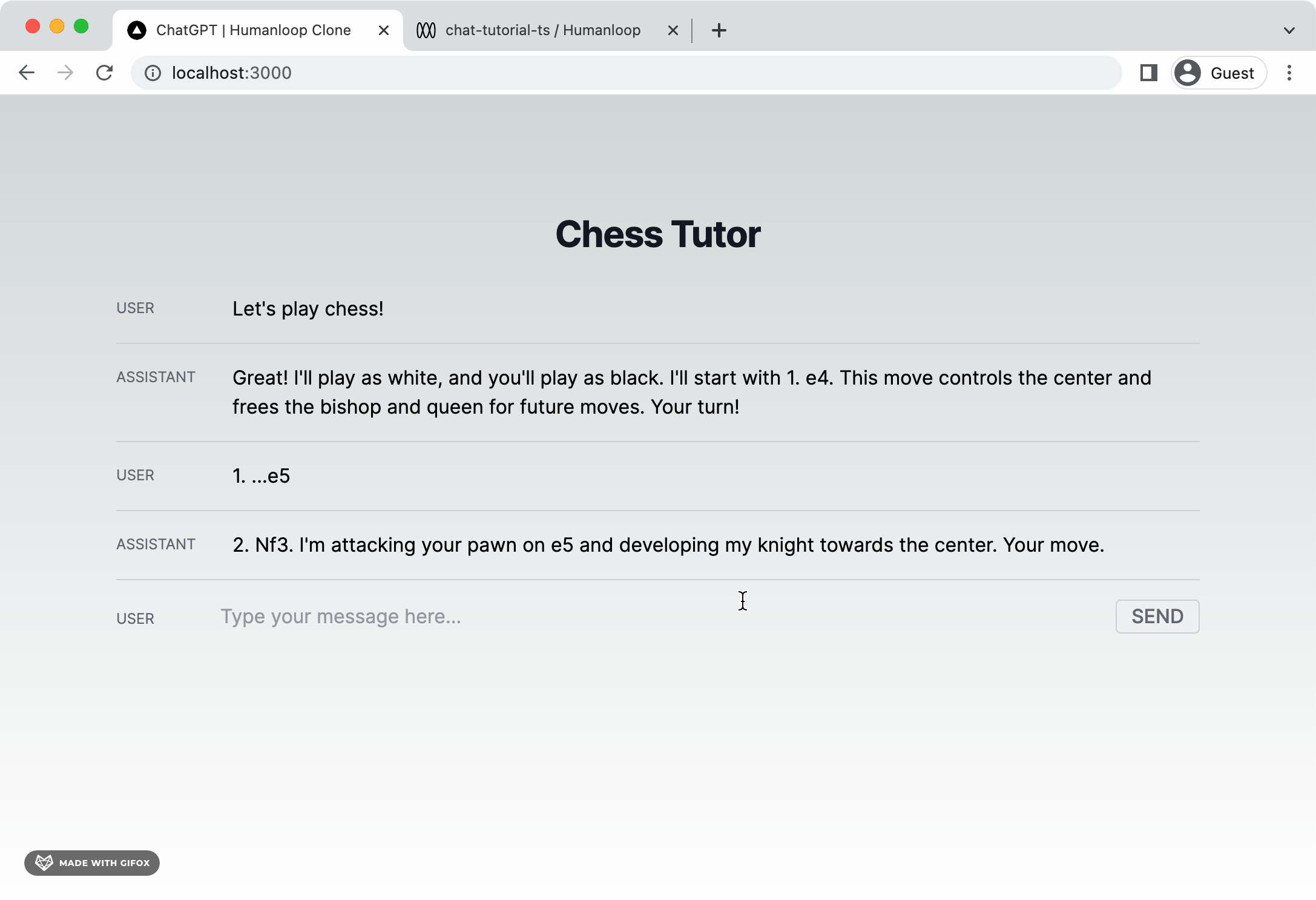
Let’s try to create a chess tutor. Paste the following system message into the Chat template box on the left-hand side.
In the Parameters section above, select gpt-4 as the model. Click Commit and enter a commit message such as “GPT-4 Grandmaster”.
Navigate back to the Dashboard tab in the sidebar. Your new Prompt Version is visible in the table at the bottom of the Prompt dashboard.
Step 2: Set up a Next.js application
Now, let’s turn to building out a simple Next.js application. We’ll use the Humanloop TypeScript SDK to provide programmatic access to the model we just created.
Run npx create-next-app@latest to create a fresh Next.js project. Accept all the default config options in the setup wizard (which includes using TypeScript, Tailwind, and the Next.js app router). Now npm run dev to fire up the development server.
Next npm i humanloop to install the Humanloop SDK in your project.
Edit app/page.tsx to the following. This code stubs out the basic React components and state management we need for a chat interface.
We shouldn’t call the Humanloop SDK from the client’s browser as this would require giving out the Humanloop API key, which you should not do! Instead, we’ll create a simple backend API route in Next.js which can perform the Humanloop requests on the Node server and proxy these back to the client.
Create a file containing the code below at app/api/chat/route.ts. This will automatically create an API route at /api/chat. In the call to the Humanloop SDK, you’ll need to pass the project name you created in step 1.
In this code, we’re calling humanloop.chatDeployed. This function is used to target the model which is actively deployed on your project - in this case it should be the model we set up in step 1. Other related functions in the SDK reference (such as humanloop.chat) allow you to target a specific model config (rather than the actively deployed one) or even specify model config directly in the function call.
When we receive a response from Humanloop, we strip out just the text of the chat response and send this back to the client via a Response object (see Next.js - Route Handler docs). The Humanloop SDK response contains much more data besides the raw text, which you can inspect by logging to the console.
For the above to work, you’ll need to ensure that you have a .env.local file at the root of your project directory with your Humanloop API key. You can generate a Humanloop API key by clicking your name in the bottom left and selecting API keys. This environment variable will only be available on the Next.js server, not on the client (see Next.js - Environment Variables).
Now, modify page.tsx to use a fetch request against the new API route.
You should now find that your application works as expected. When we send messages from the client, a GPT response appears beneath (after a delay).
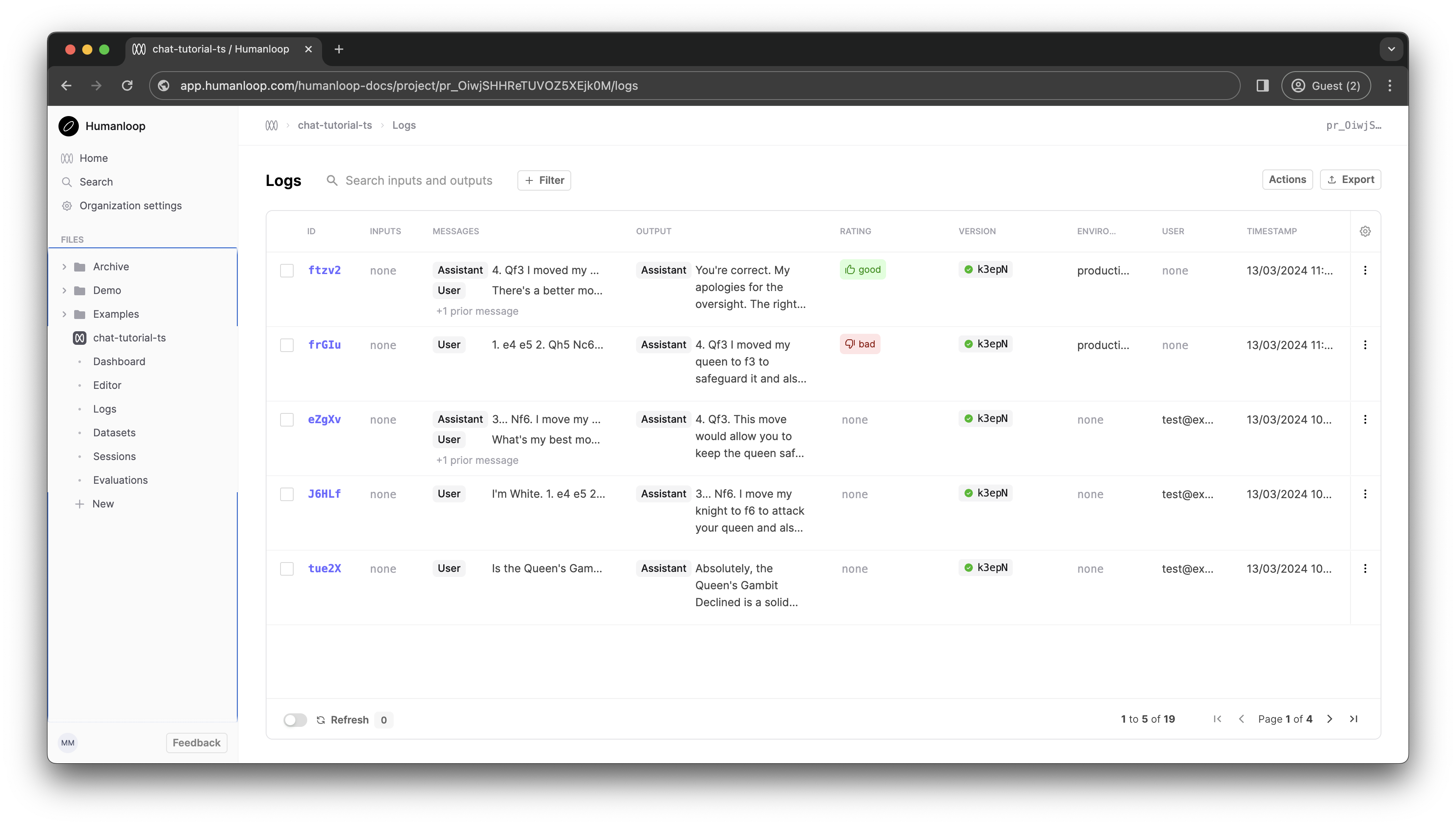
Back in your Humanloop Prompt dashboard you should see Logs being recorded as clients interact with your model.
Step 3: Streaming tokens
(Note: requires Node version 18+).
You may notice that model responses can take a while to appear on screen. Currently, our Next.js API route blocks while the entire response is generated, before finally sending the whole thing back to the client browser in one go. For longer generations, this can take some time, particularly with larger models like GPT-4. Other model config settings can impact this too.
To provide a better user experience, we can deal with this latency by streaming tokens back to the client as they are generated and have them display eagerly on the page. The Humanloop SDK wraps the model providers’ streaming functionality so that we can achieve this. Let’s incorporate streaming tokens into our app next.
Edit the API route at to look like the following. Notice that we have switched to using the humanloop.chatDeployedStream function, which offers Server Sent Event streaming as new tokens arrive from the model provider.
Now, modify the onSend function in page.tsx to the following. This streams the response body in chunks, updating the UI each time a new chunk arrives.
You should now find that tokens stream onto the screen as soon as they are available.
Step 4: Add Feedback buttons
We’ll now add feedback buttons to the Assistant chat messages, and submit feedback on those Logs via the Humanloop API whenever the user clicks the buttons.
Modify page.tsx to include an id for each message in React state. Note that we’ll only have ids for assistant messages, and null for user messages.
Modify the onSend function to look like this:
Now, modify the MessageRow component to become a ChatItemRow component which knows about the id.
And finally for page.tsx, modify the rendering of the message history to use the new component:
Next, we need to create a Next.js API route for submitting feedback, similar to the one we had for making a /chat request. Create a new file at the path app/api/feedback/route.ts with the following code:
This code simply proxies the feedback request through the Next.js server. You should now see feedback buttons on the relevant rows in chat.
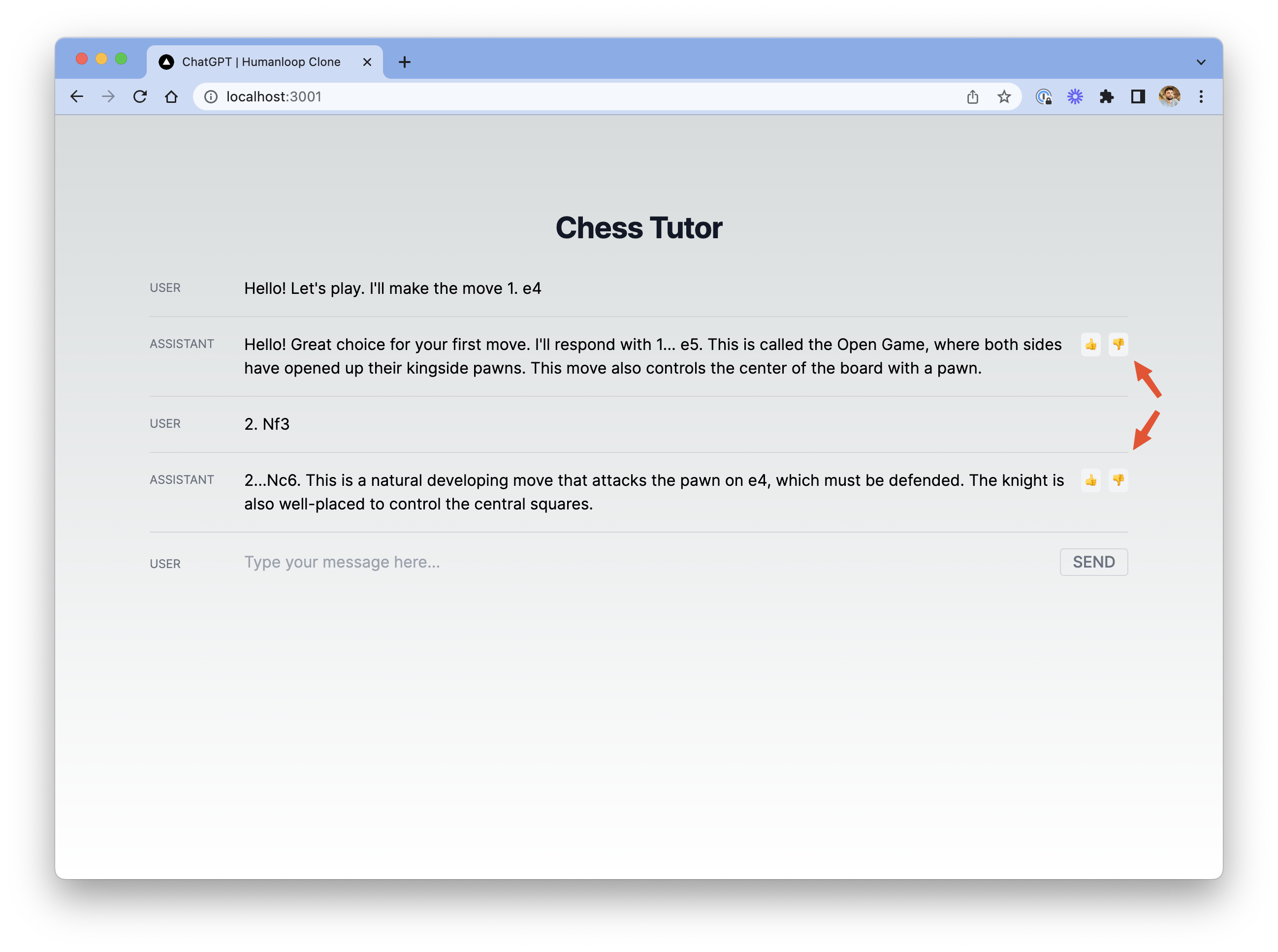
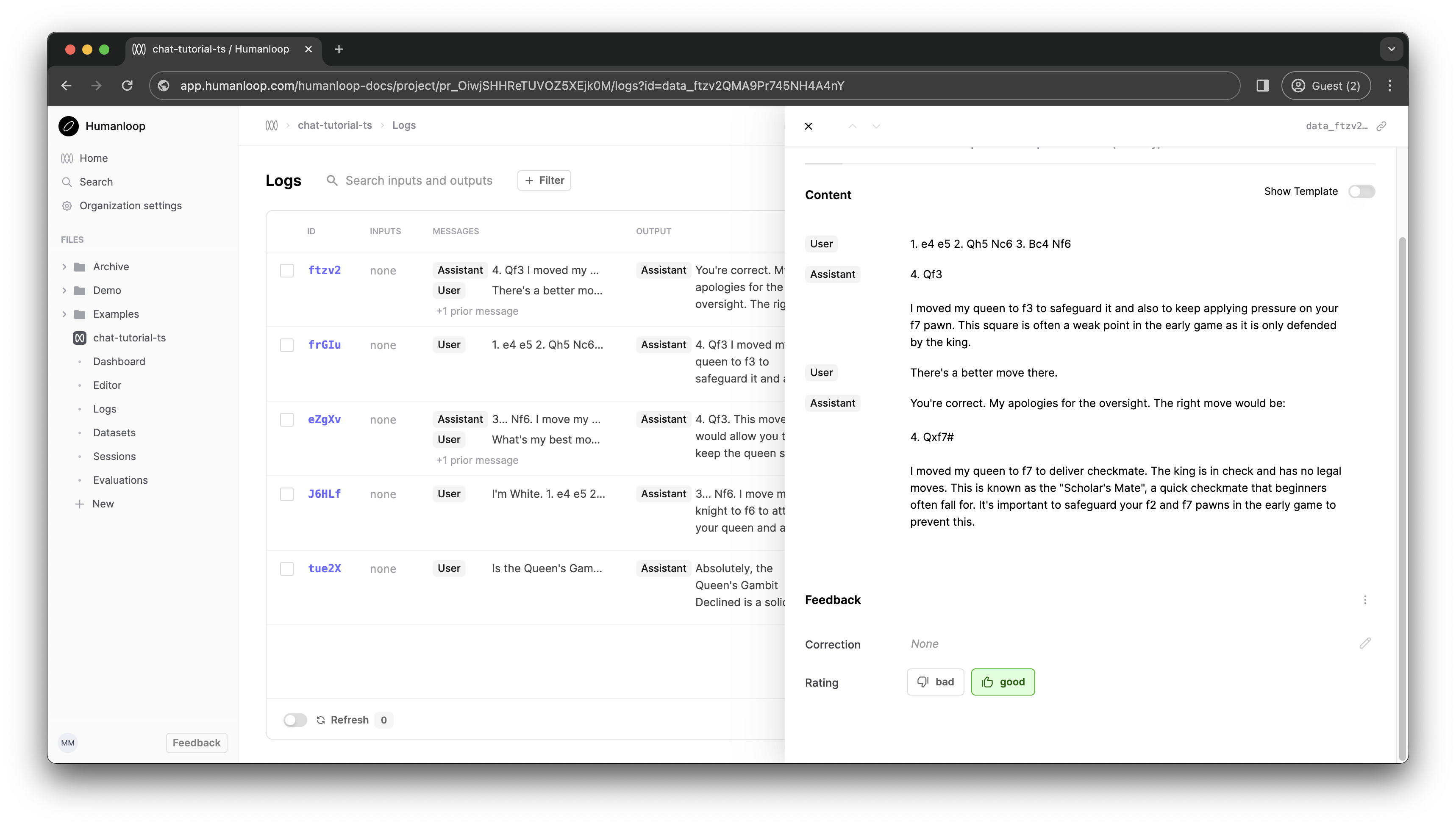
When you click one of these feedback buttons and visit the Prompt in Humanloop, you should see the feedback logged against the log.
Conclusion
Congratulations! You’ve now built a working chat interface and used Humanloop to handle interaction with the model provider and log chats. You used a system message (which is invisible to your end user) to make GPT-4 behave like a chess tutor. You also added a way for your app’s users to provide feedback which you can track in Humanloop to help improve your models.
Now that you’ve seen how to create a simple Humanloop project and build a chat interface on top of it, try visiting the Humanloop project dashboard to view the logs and iterate on your model configs. You can also create experiments to learn which model configs perform best with your users. To learn more about these topics, take a look at our guides below.