Manage multiple reviewers
How to split a review between multiple subject-matter experts to effectively and quickly evaluate your AI product.
Who is this for: This guide is for large teams that want to leverage their internal subject matter experts (SMEs) to evaluate the performance of their AI features.
Prerequisites
- You have set up Evaluators. If not, follow our guide to create a Human Evaluator.
- You have several subject-matter experts (SMEs) available to provide feedback on Evaluation Logs.
Divide work between SMEs
When you have a large Dataset to evaluate, it’s helpful to split the work between your SMEs to ensure that the evaluation is completed quickly and effectively.
Split the Dataset into chunks
Each Dataset consists of datapoints. Add an identifier to each datapoint to group them into chunks.
For example, we created a Dataset with 100 common customer support questions. In the csv file, we added an identifier called “chunk” to each datapoint, splitting the whole Dataset into 10 equal parts.
To upload this CSV on Humanloop, create a new Dataset file, then click on the Upload CSV button.
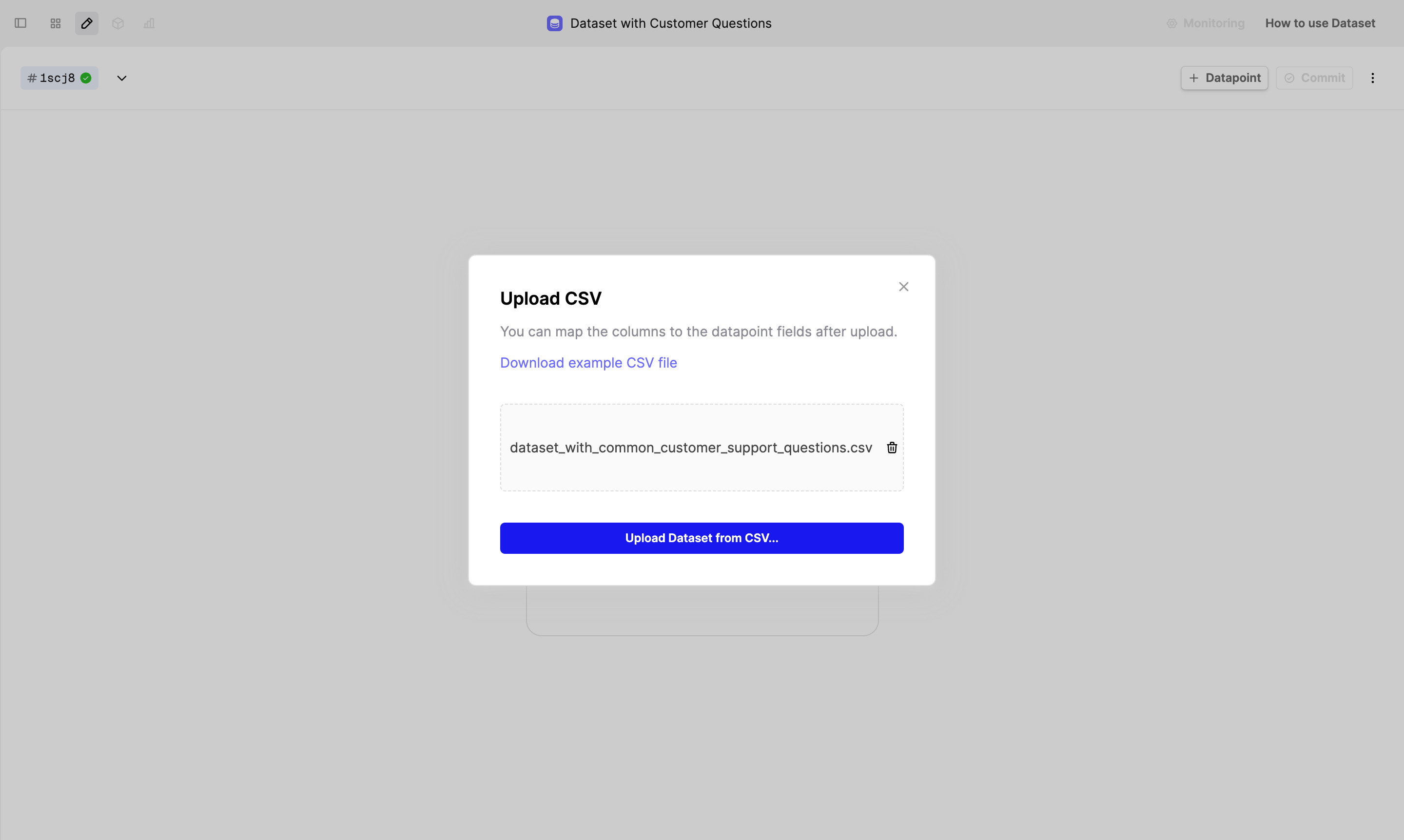
Alternatively, you upload Dataset via our SDK
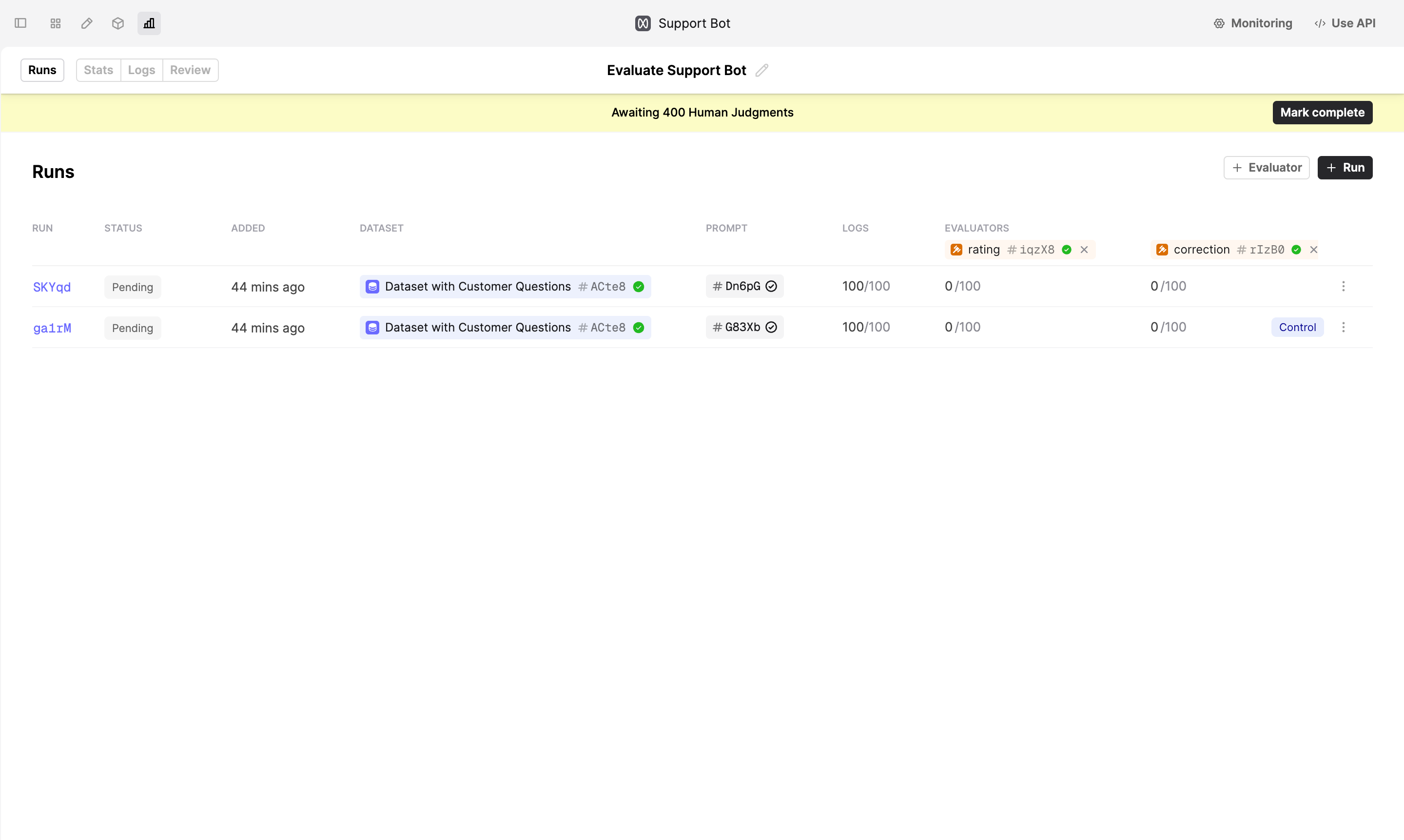
Run an Evaluation
Navigate to a Prompt you want to evaluate and create a new Evaluation Run.
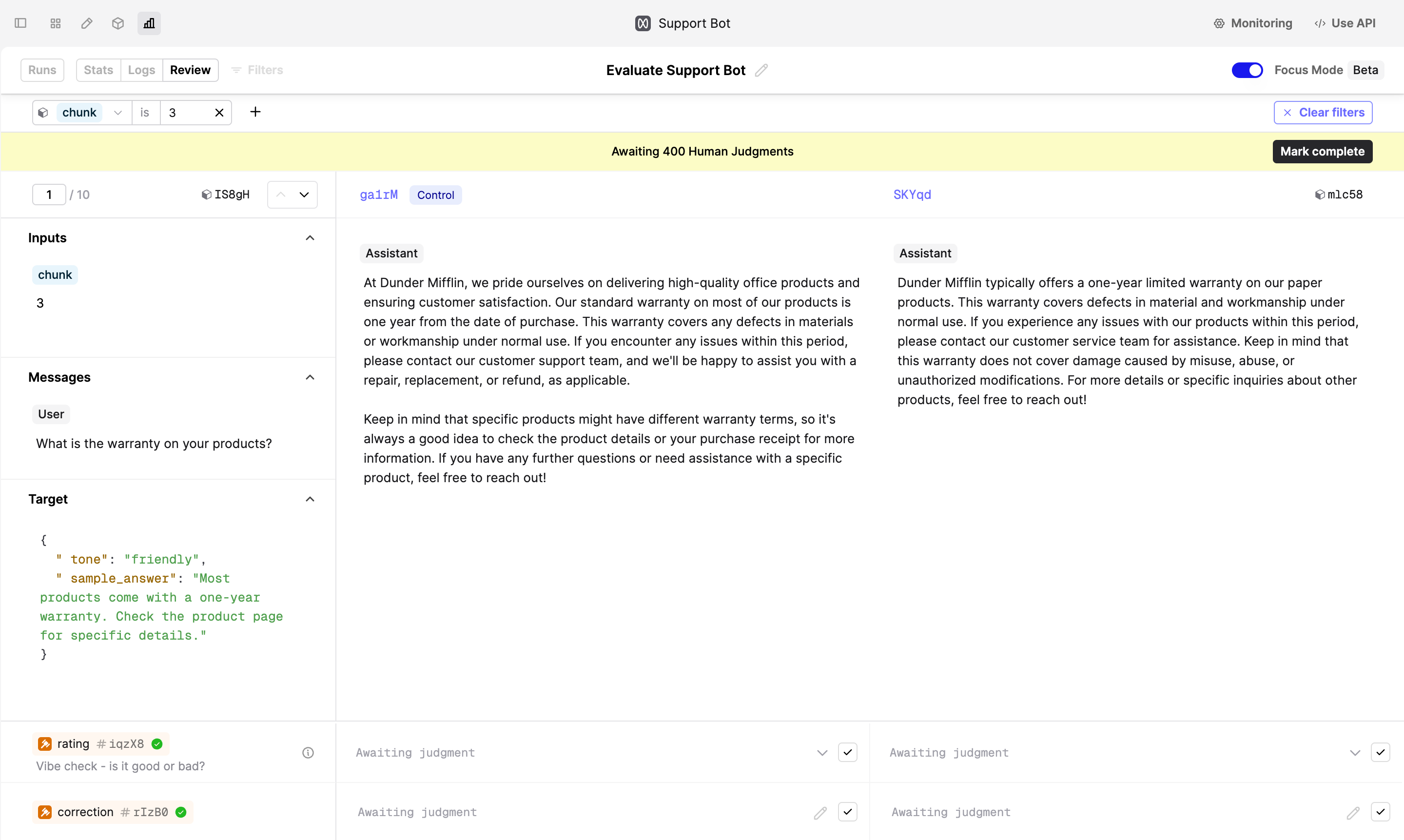
Split the workload between SMEs
To split the workload between your SMEs, navigate to the Review tab, turn on Focus mode, and click on the Filters button. Filter the Dataset by identifiers, such as “chunk”, to split the review work into smaller pieces.
Improve the Prompt
With judgments from your SMEs, you can now better understand the model’s performance and iterate on your Prompt to improve the model outputs.
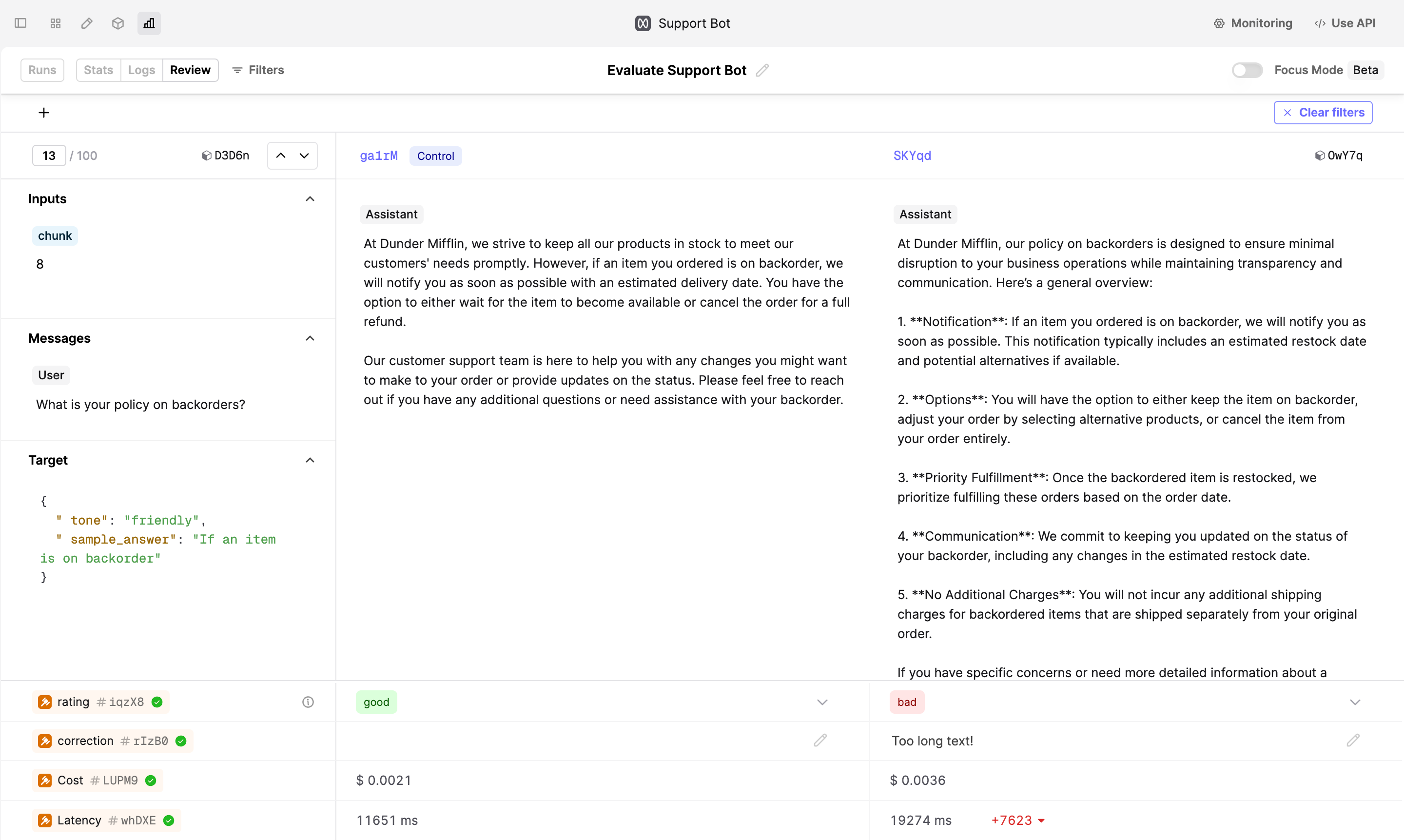
In our example, the SME marked the Log on the right-hand side as “bad” because it’s too long. To take action, click on the Log ID above the Log output to open the Log drawer. In the drawer, click on the Editor -> button to load this Log in the Prompt Editor. Now, modify the instructions to explicitly state that the model should provide a concise answer.
Next steps
We’ve successfully split the work among multiple SMEs to effectively evaluate the performance of our AI product. Explore next:
- If your SMEs gave negative judgments on the Logs, see our guide on Comparing and Debugging Prompts.
- Find out more about Human Evaluators to capture feedback that is most relevant to your use case.