Evals in the UI
Evaluate and improve your LLM apps by running Evals in the Humanloop UI.
This tutorial will take you through running your first Eval. You’ll learn how to assess multiple Prompt versions to improve the quality of your AI products.
Account setup
Create a Humanloop Account
If you haven’t already, create an account or log in to Humanloop
Add an OpenAI API Key
If you’re the first person in your organization, you’ll need to add an API key to a model provider.
- Go to OpenAI and grab an API key.
- In Humanloop Organization Settings set up OpenAI as a model provider.
Using the Prompt Editor will use your OpenAI credits in the same way that the OpenAI playground does. Keep your API keys for Humanloop and the model providers private.
Running Evals
For this tutorial, we’re going to evaluate the performance of a simple Support Agent that responds to user queries.
Create a Prompt File
When you first open Humanloop you’ll see your File navigation on the left. Click +New and create a Prompt. In the Prompt Editor, add the following Prompt instructions:
Save this version.
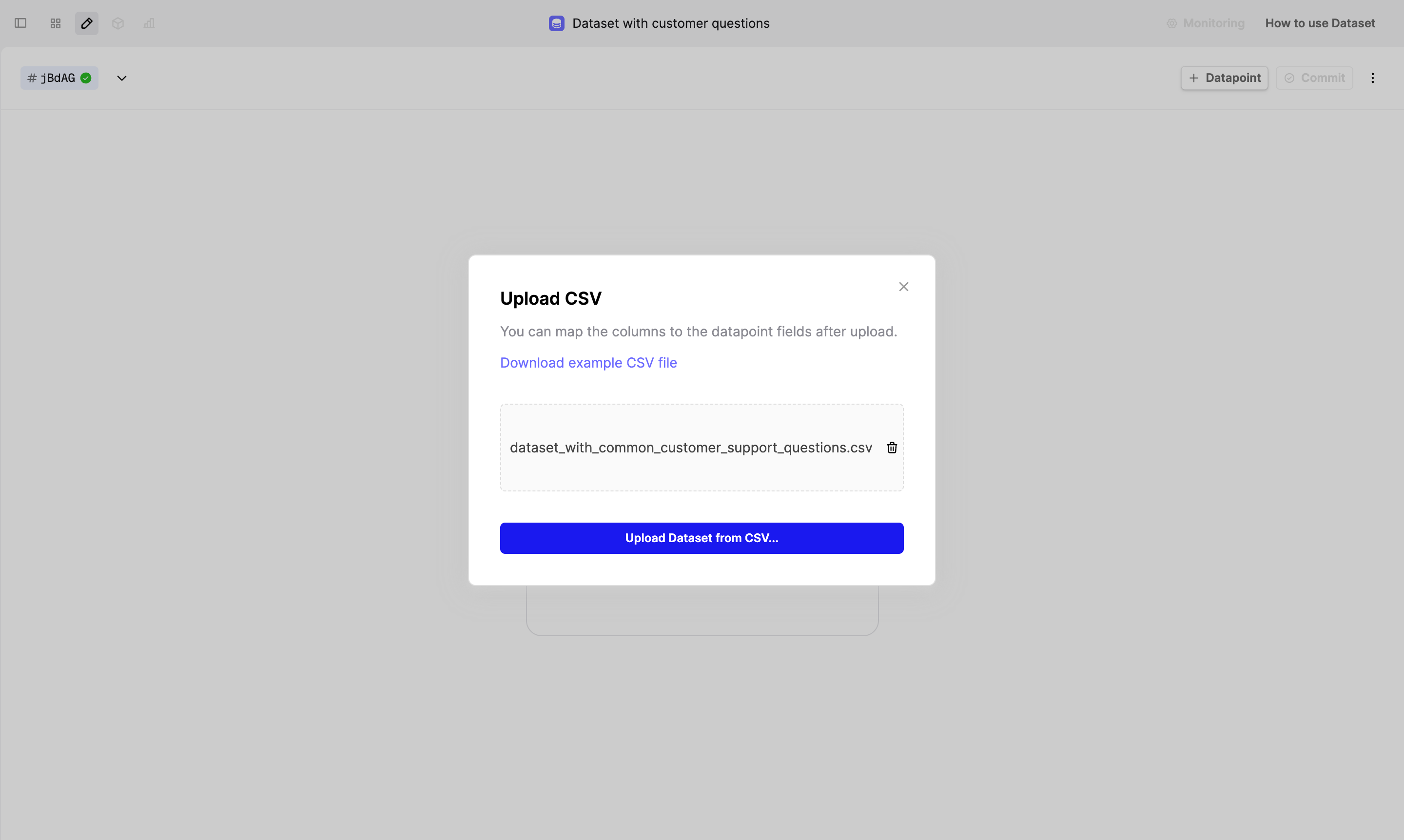
Create a Dataset
The Dataset contains datapoints describing the inputs and, optionally, the expected results for a given task.
For this tutorial, we created a csv file with 100 common customer support questions.
Create a new Dataset file, then click on the Upload CSV button to upload the file.
Run your first Evaluation
Navigate to the Prompt you’ve just created and click on the Evaluation tab. Click on the Evaluate button to create a new Evaluation.
Create a new Run by clicking on the +Run button. Select the Dataset and Prompt version we created earlier.
Add Evaluators by clicking on +Evaluator button. For this tutorial, we selected Semantic similarity, Cost and Latency Evaluators. You can find these Evaluators in the Example Evaluators folder.
“Semantic similarity” Evaluator measures the degree of similarity between the model’s response and the expected output provided on a scale from 1 to 5 (1 is very dissimilar and 5 is very similar).
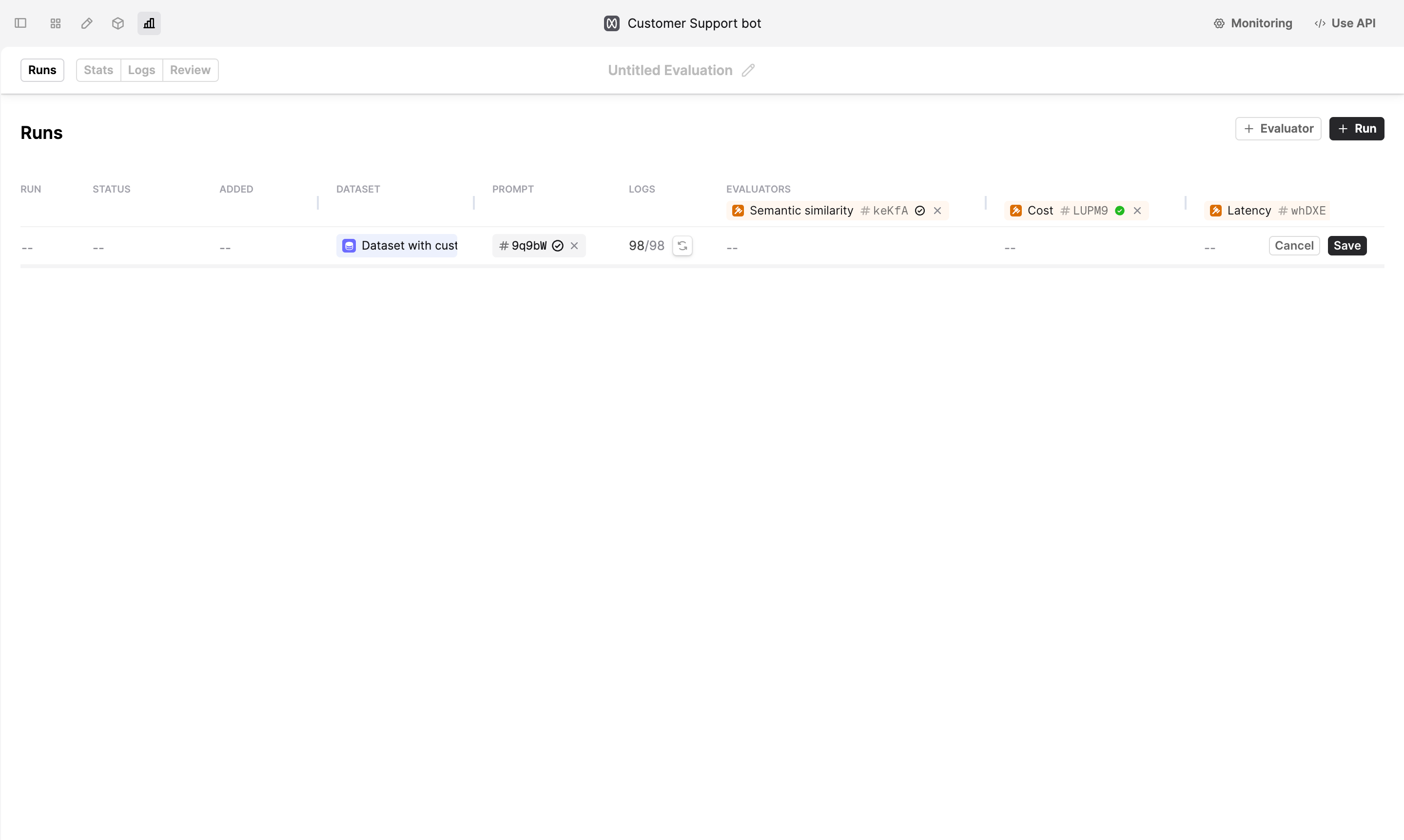
Click Save. Humanloop will start generating Logs for the Evaluation.
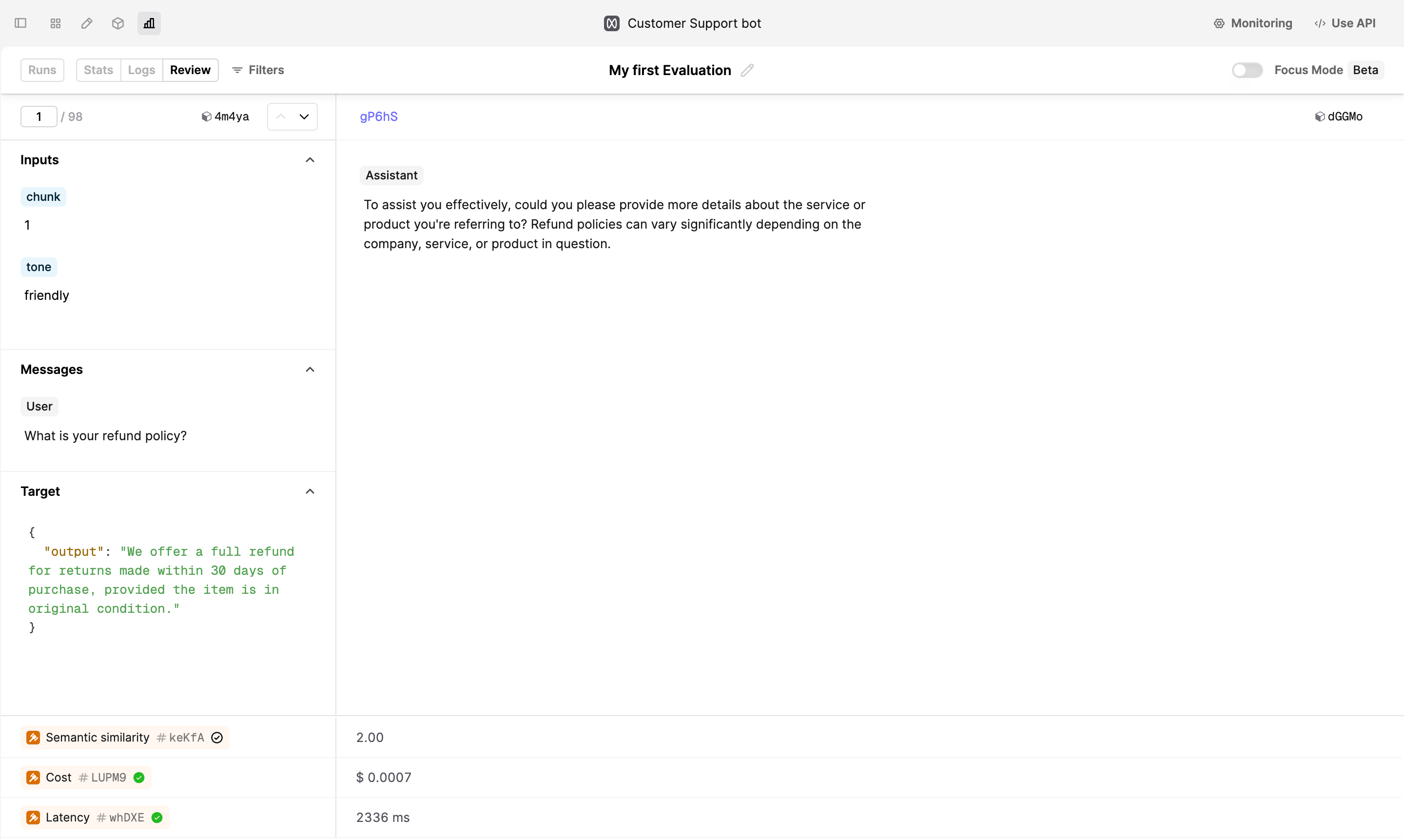
Review results
After the Run is completed, you can review the Logs produced and corresponding judgments in the Review tab. The summary of all Evaluators is displayed in the Stats tab.
Make changes to your Prompt
After reviewing the results, we now have a better understanding of the Prompt’s behavior. We can improve its performance. Navigate back to the Prompt Editor and change the instructions to:
Save this new version.
Run another Evaluation
We can now create a new Run with the new Prompt version. Click on the +Run button and select the newly created Prompt version.
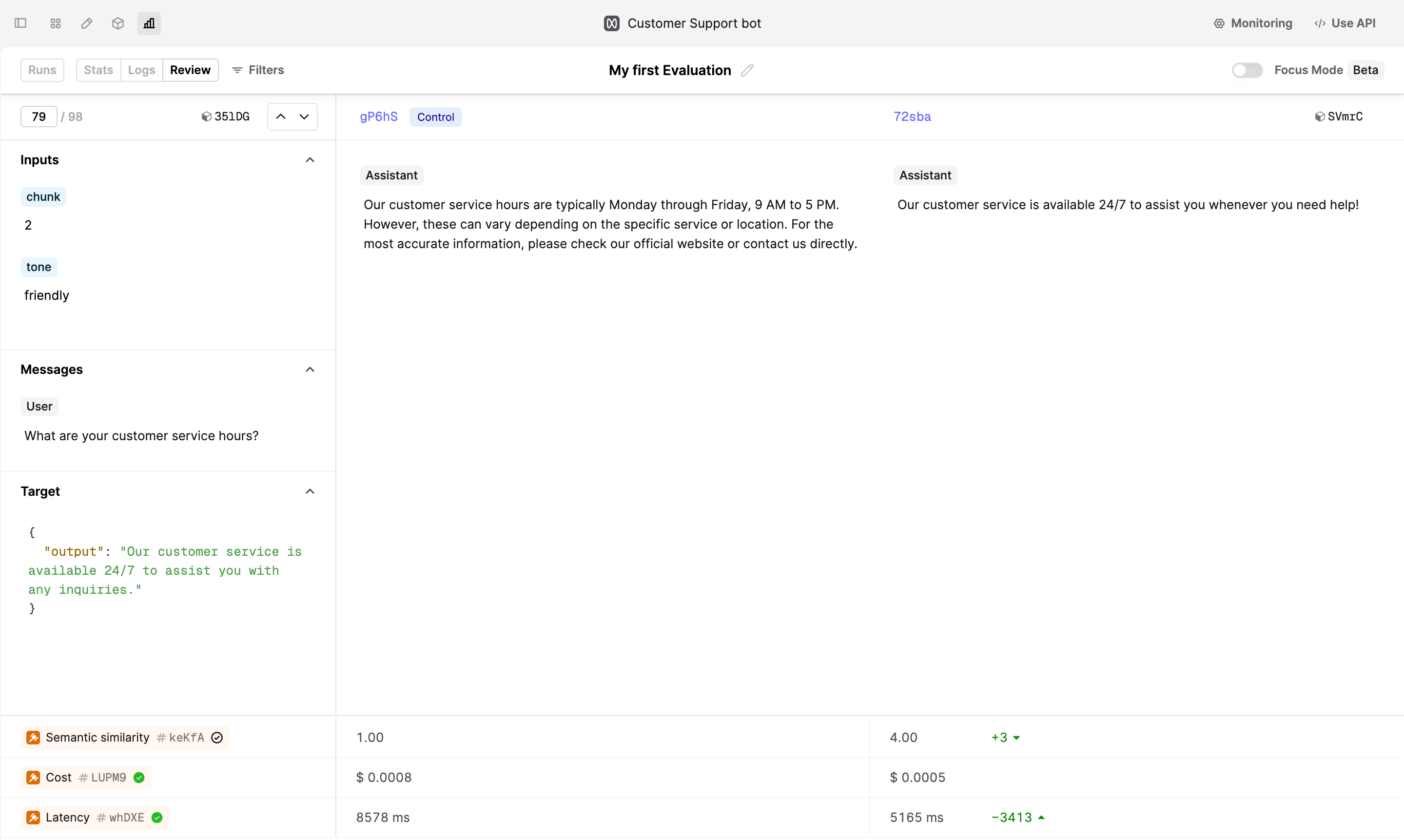
We can now see from the Stats view that the updated version performs better across the board. To get a detailed view, navigate to Logs or Stats tabs.
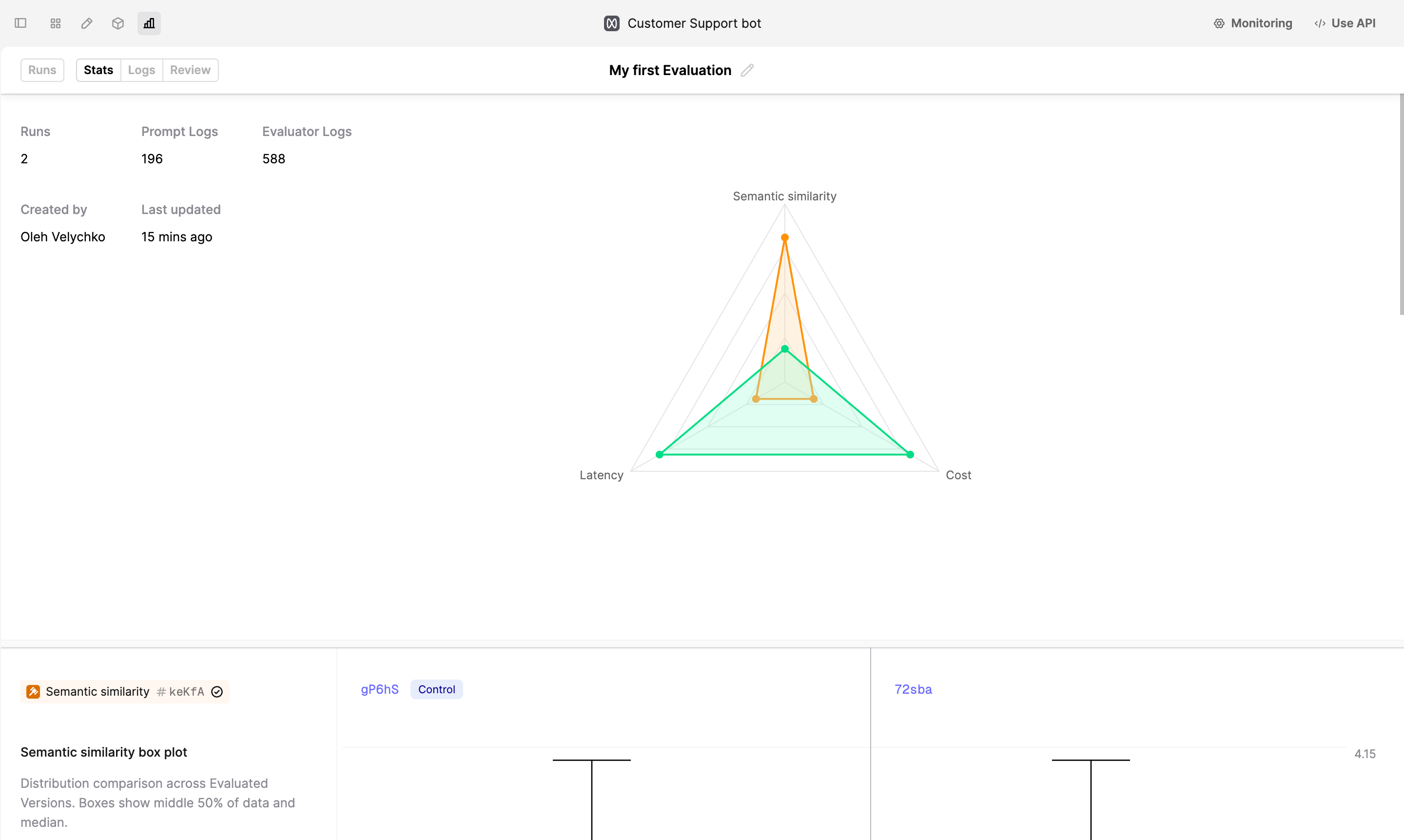
Next steps
Now that you’ve successfully run your first Eval, you can explore customizing for your use case:
- Explore how you set up Human Evaluators to get human feedback on your Prompt Logs
- Learn how internal subject-matter experts can evaluate model outputs and improve your AI product