Humanloop is moving to General Availability
Humanloop is moving to General Availability — continuing to set the standard for AI engineering
Today we’re excited to open access to Humanloop for all enterprises building AI products with LLMs.
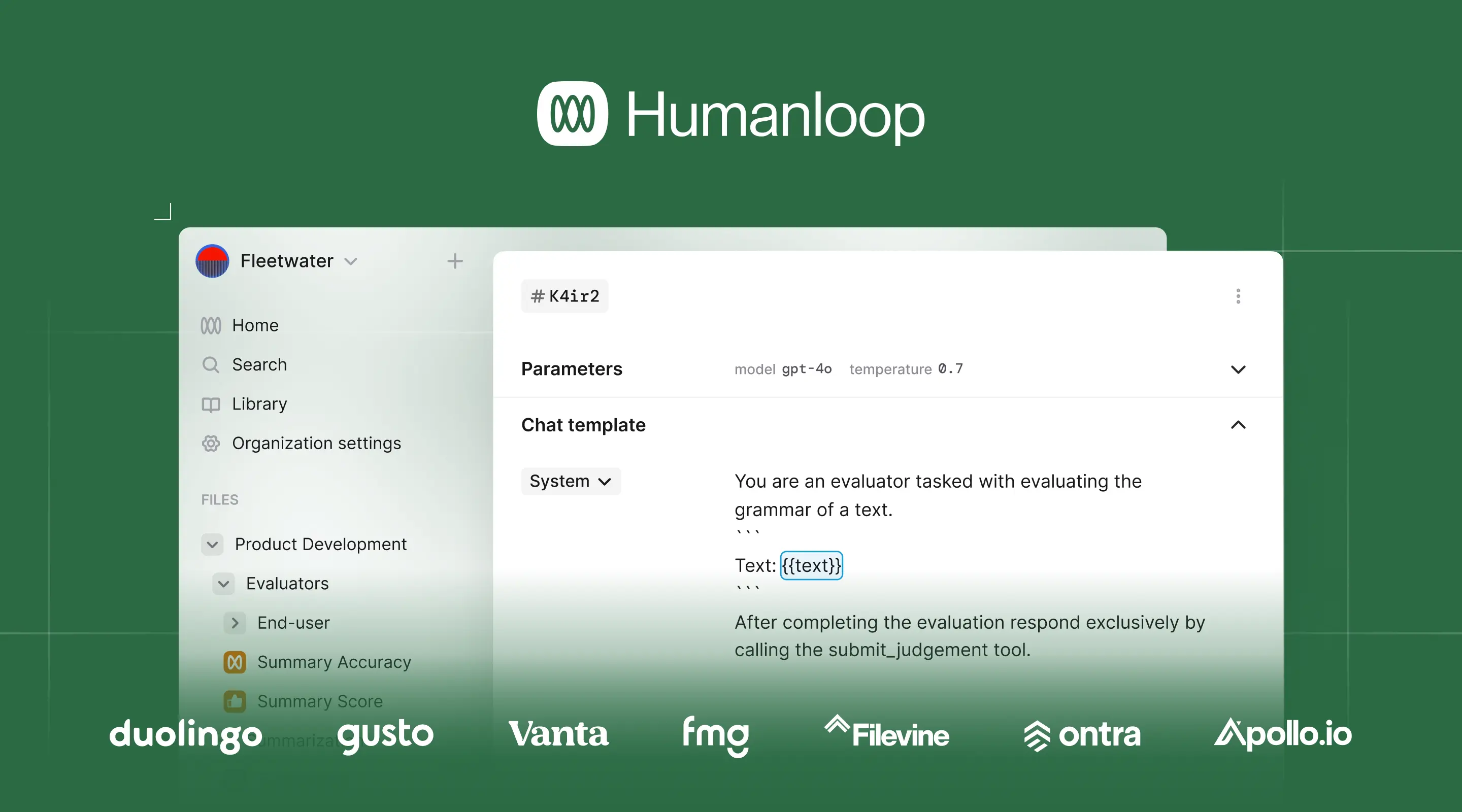
When we first launched early access, the ecosystem was incredibly young – ChatGPT hadn't been released, and the most advanced model available was GPT-3. We had the privilege of working closely with pioneering teams building the first generation of LLM products at companies like Duolingo, Gusto, and Vanta.
We used the experience to deeply understand the challenges of developing with this new technology and design a new way of building software.
Humanloop has evolved from a simple system to A/B test prompts into a fully fledged evals-platform — at the core is a new workflow based around systematic evaluation, coupled with a collaborative development environment for AI engineering and tools for observability in production.
Today we're excited to make the whole platform available to all enterprises.
I'd like to walk you through what we've learned and how we can help you build production-ready AI products. For more details of engineering and product velocity over the year, read our accompanying post from Peter our CTO here.
LLMs broke traditional software development
Large Language Models (LLMs) make writing tests extremely challenging. They're inherently stochastic – the same input can produce different outputs. Without good tests it’s easy to accidentally introduce regressions or endlessly tweak prompts without measurable improvement.
Prompts blur the boundary between logic and data. Even small wording changes can lead to dramatically different behaviors. IDEs weren’t designed for this kind of development.
Perhaps most importantly, building great LLM applications requires deep domain expertise. The person best placed to write prompts or evaluate performance is rarely a software engineer. However, storing prompts in code and versioning them only with Git creates barriers between technical experts and domain experts – precisely when close collaboration is most critical.
The solution is an eval-driven workflow powered by Humanloop
Evals are at the core of every successful AI product
At the heart of our new release is opening up access to our evaluation framework. We’ve seen that the differentiating factor between successful AI products and projects that stall as demos is evals. Evals are the LLM equivalent of unit-tests — they eliminate guesswork out of AI engineering, establish quality gates for deployment, prevent regressions, and provide confidence in your AI application before it reaches production.
With Humanloop, teams can define custom evaluation functions that are either automated code checks, LLM-as-judge, or human review. Running evaluations against versioned datasets and produces reports that inform and accelerate iteration cycles.
Evals can be integrated into CI/CD pipelines, making it easier to catch issues early. They also augment production logs so you can debug more easily. For most teams evals becomes a critical part of their development workflow to ensure every iteration is an improvement.
Humanloop empowers both engineers and domain experts
Building effective AI products with LLMs requires seamless collaboration between technical teams and domain experts. At Duolingo, linguists refine prompts to create engaging learning experiences. At Gusto, the customer support team directly contributes to evaluations. And at Filevine, legal professionals drive the development of AI features tailored to their industry. Who better to evaluate AI outputs than the experts who best understand the domain?
We built an updated interactive editor and prompt repository, designed specifically for AI engineering. Production data flows directly into the development environment, providing teams with immediate insight into real-world performance. Every input is validated, every change is tracked, and prompts or tools can be deployed as callable functions, enabling fast and reliable iteration.
External data sources and tools integrate seamlessly into this workflow, allowing teams to build sophisticated AI applications that connect LLMs to existing systems. Whether it’s working on prompts, retrieval-augmented generation (RAG) systems, or AI agents, Humanloop empowers your entire team to collaborate effectively enabling you to build faster. As Alex McLaughlin, VP of Product at Filevine, explains:
Lightweight Infrastructure for AI agents
To support complex AI systems, we’ve designed a minimalist system of new abstractions that will allow you to adopt AI agents and futureproof your applications. It consists of a file system with 4 core types: “prompts”, “tools”, “evaluators” and “flows”. Each of these files is versioned, callable and can be hosted on Humanloop’s runtime or your own . We give you the flexibility to manage these files using both a code-first or UI-first approach.
AI capabilities are still rapidly evolving. LLMs have become multi-modal, added function calling, dramatically extended context lengths, slashed token costs, and their reasoning capabilities continue to improve. Developers also now have many choices across a variety of model providers.
The earliest LLM applications were simple – single calls to a well crafted prompt. Modern AI applications are far more complex systems. They're increasingly agents and RAG systems, involving multiple models, knowledge retrieval, and external tools calling.
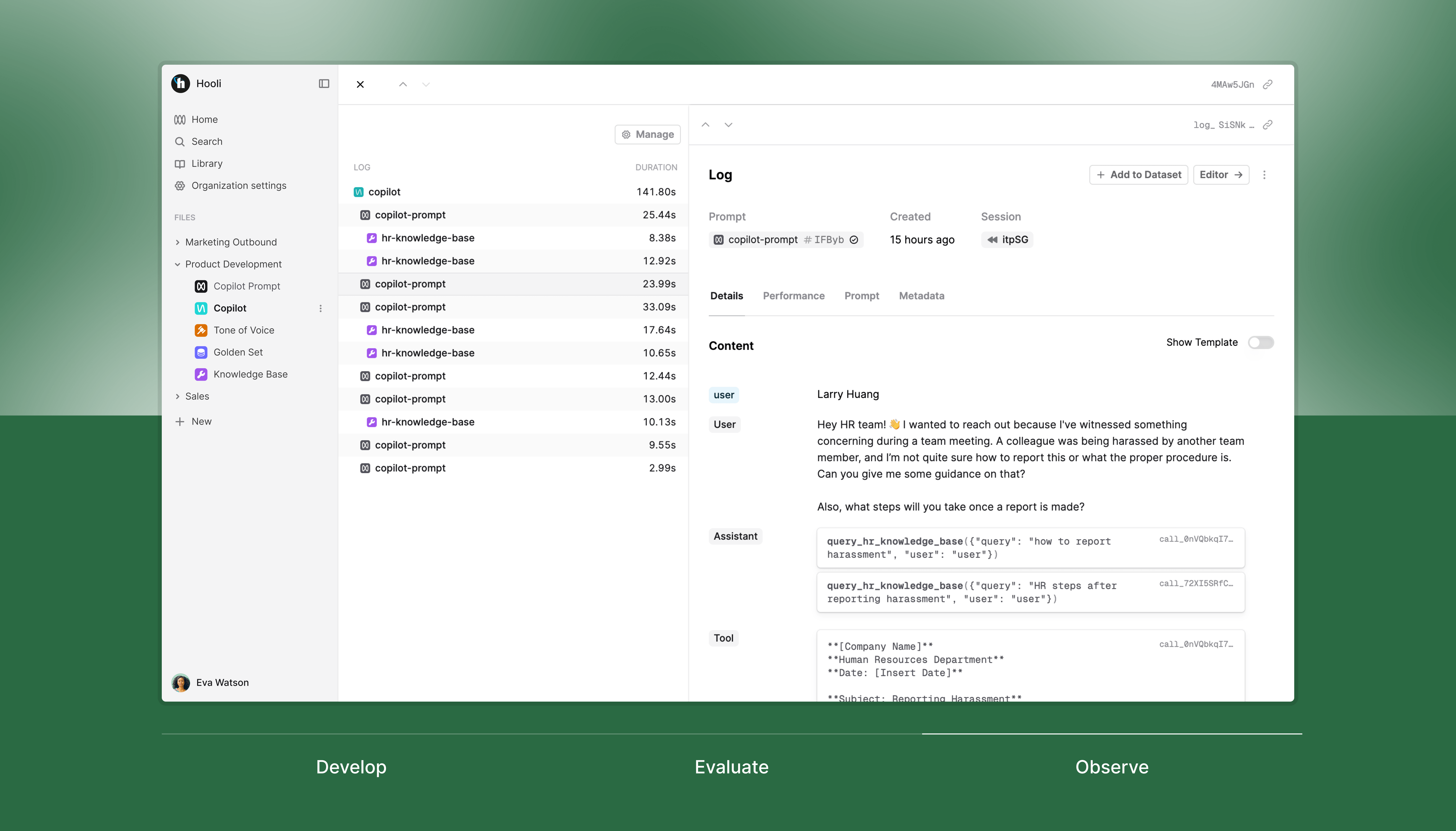
We built tracing to provide complete visibility into how your AI agents behave in production. From prompt execution history and RAGworkflows to performance metrics and user feedback, Humanloop gives you a complete understanding of how your agents operate and where to improve them.
Explore the full platform from today
Starting today, the full Humanloop platform is now available to everyone. Get all the tools you need to develop, evaluate, and observe your AI product. Here’s what’s included:
Collaborative environment
A workspace where domain experts and engineers work seamlessly together. Built-in version control, designed specifically for prompts and evaluation artifacts, enabling teams to track changes, experiment safely, and roll back when needed.
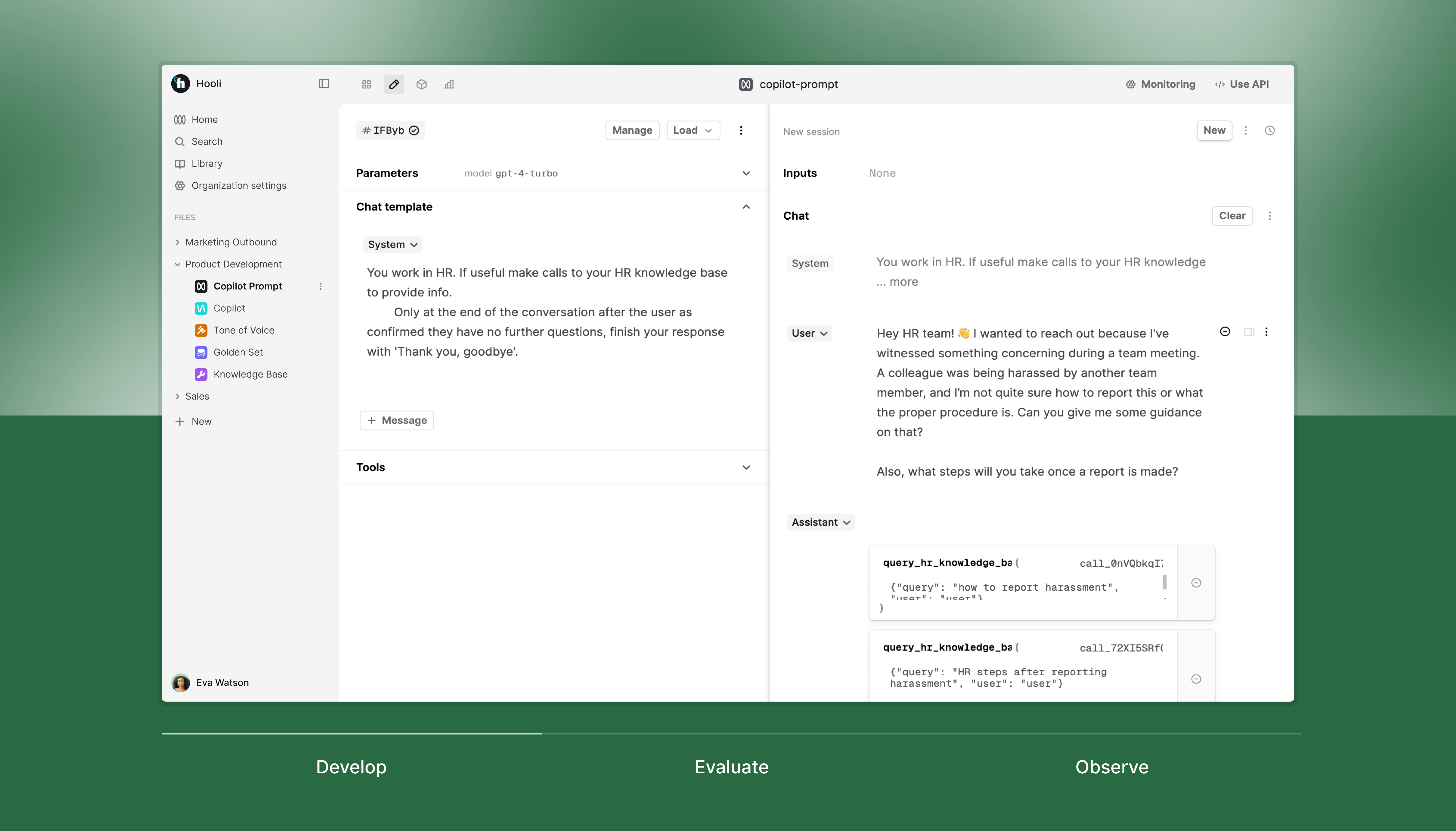
Evaluation framework
Provides the foundation for reliable AI development. Teams can define custom evaluation metrics, run automated tests, and set up quality gates for deployment. This ensures that every change improves your application's performance.
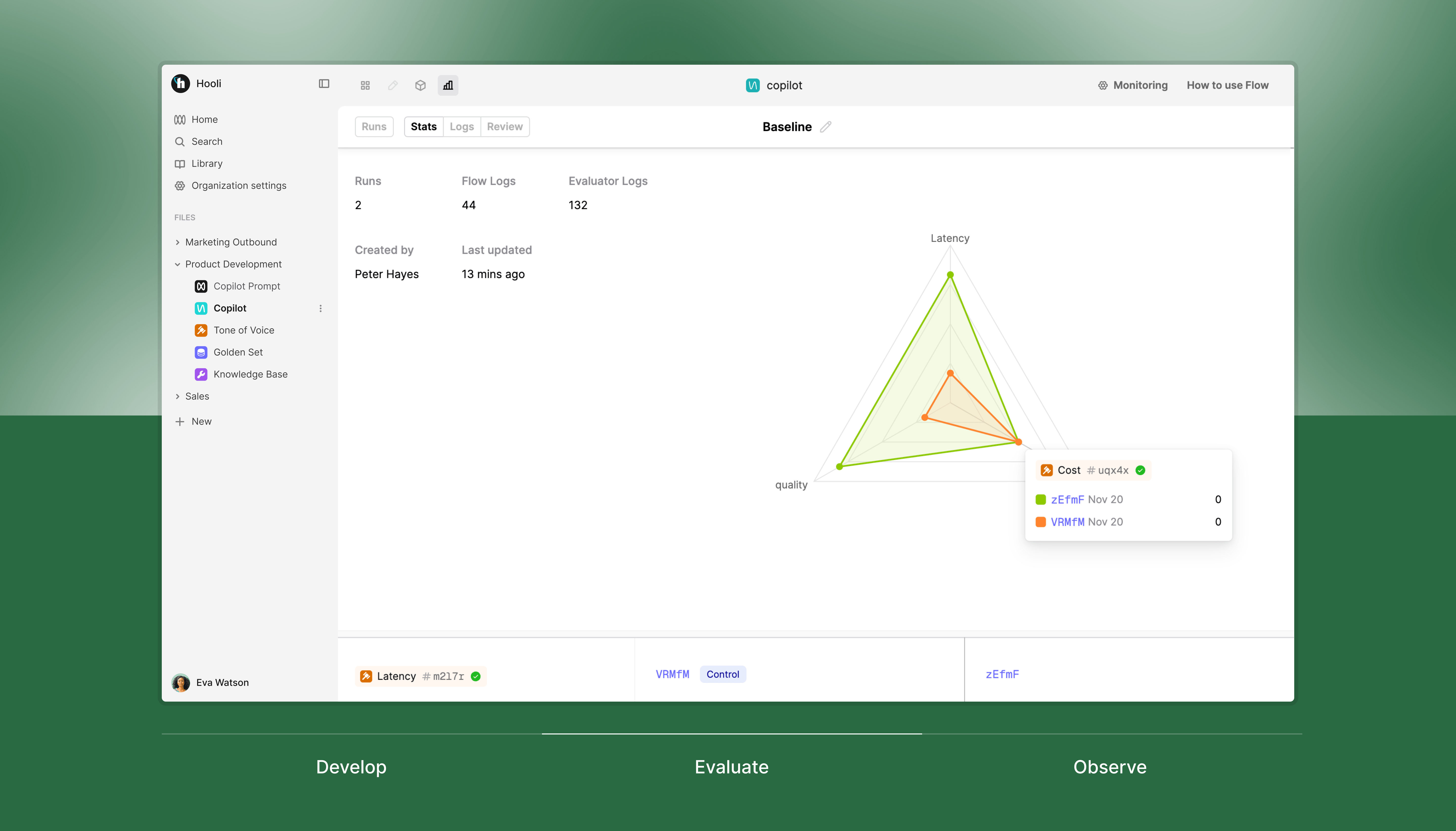
Enhanced tracing system
Complete visibility into complex AI applications. You can track entire chains of LLM operations, from initial prompts through RAG retrievals and tool usage, providing actionable insights to optimize your AI systems' behavior in production.
Ready to build successful AI products? Book a demo to see how we can support your team’s AI goals.
Help us build the future
AI will transform society in unprecedented ways. If we get it right, everyone will have access to a personal doctor, every child to amazing tutors, and scientists to AI assistants that accelerate their research. Companies will automate mundane tasks, freeing teams to focus on creative and meaningful work. But realizing this vision will involve building the right new infrastructure. To make AI reliable, to make it trustworthy and accessible for anyone who wants to build with it.

At Humanloop, we're committed to building the foundation that makes this possible. If you're building with LLMs, we'd love to help you move faster and ship with confidence.
To support our vision, we've raised $8M in total funding from YC Continuity, Index Ventures, Localglobe; and industry leaders including the founders of Datadog and Segment, people who understand what it takes to create transformative development platforms.
Ready to build successful AI products? Book a demo to see how we can support your team’s AI goals
A special thank you to our customers, team, and early supporters who have helped shape Humanloop into what it is today. Come celebrate with our team and community in SF today and London next week.
About the author

- 𝕏@RazRazcle










