Model Distillation
Model Distillation: What is it and how does it work?
Model Distillation is a technique designed to enhance the computational efficiency of large language models (LLMs) by taking the outputs of a larger, more complex model and using them to fine-tune a smaller model with the goal of reaching similar performance. If you've been grappling with high resource demands or latency issues, model distillation offers a practical solution.
This blog explains how model distillation works, its benefits and challenges, and guide you on getting started with OpenAI model distillation and other alternatives.
What is Model Distillation?
Model distillation involves fine-tuning smaller, more cost-efficient langauge models using the outputs from larger, more capable models. The goal is to make the performance of the fine-tuned model comparable to that of the larger model in a given task. If successful, this results in the deployment of a faster and more cost-effective AI application without sacrificing accuracy or reliability.
How Does Model Distillation Work?
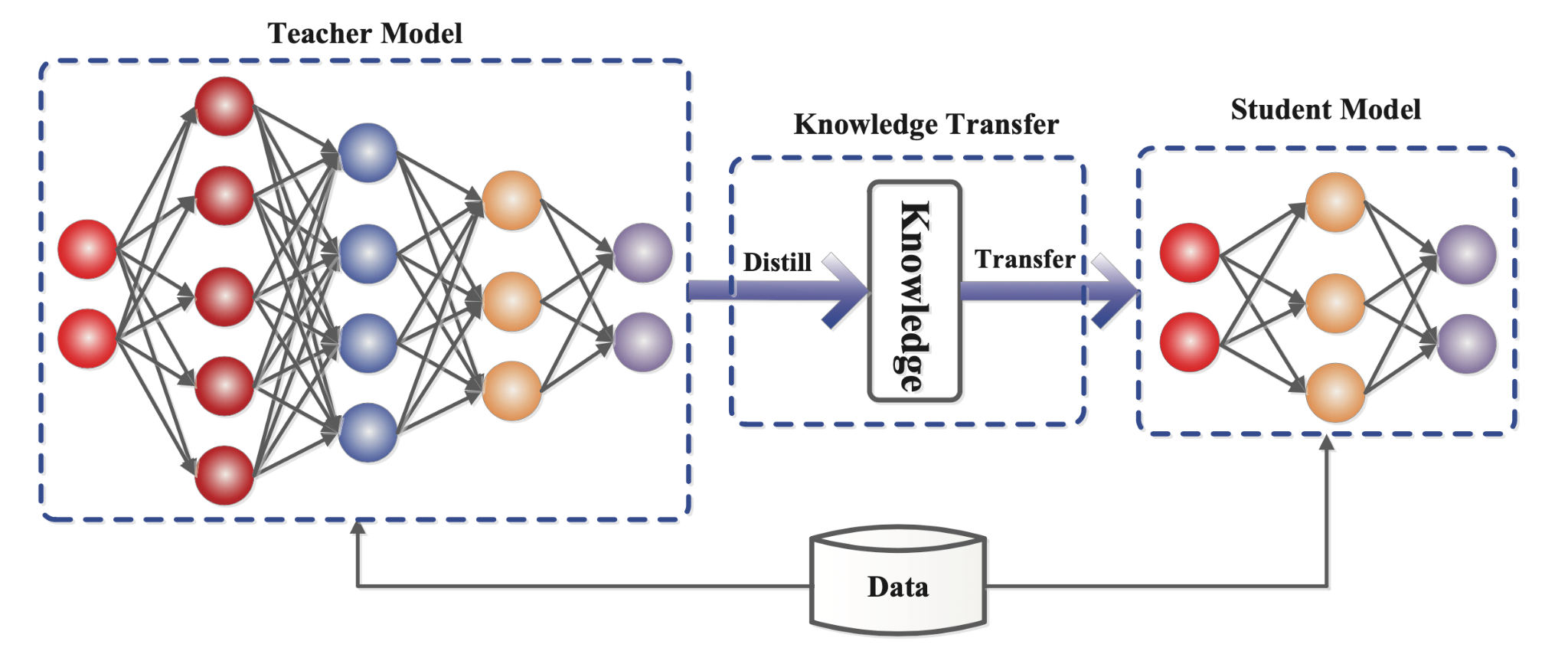
Model distillation operates by transferring knowledge from a large, complex language model—the "teacher"—to a smaller, more efficient model known as the "student." The process begins by generating a dataset where the teacher model provides outputs for a wide range of inputs. This dataset captures the behavior and decision-making patterns of the teacher, serving as a rich source of information for the student model.
The student model is then fine-tuned using this dataset, learning to mimic the teacher's responses to various inputs. Techniques like temperature scaling are often employed to soften the output probabilities of the teacher, making it easier for the student to learn nuanced patterns. This approach is central to the knowledge distillation of large language models, enabling the student to grasp complex concepts without the need for extensive training data.
Benefits of Model Distillation
Model distillation offers several significant advantages for enterprises utilizing large language models (LLMs).
Increased computational efficiency
One of the primary benefits is the reduction in computational resources required for deployment. By distilling large language models into smaller, more efficient versions, enterprises can maximize LLM performance while reducing computational overhead and latency.
Reduced model costs
Cost efficiency is another major advantage. Smaller models consume less energy and require less powerful hardware, leading to reduced operational expenses. This makes the knowledge distillation of large language models an attractive strategy for businesses looking to scale their AI solutions without incurring prohibitive costs.
Enhanced scalability
LLM model distillation enhances scalability and accessibility. By making advanced AI capabilities available on a wider range of platforms—including mobile and edge devices—enterprises can reach a broader audience and offer more versatile services.
Challenges of Model Distillation
Despite its benefits, model distillation presents several challenges that organizations need to address.
Loss of accuracy
When you distill a large language model into a smaller one, there's a risk that the student model may not fully capture the nuances of the teacher model, leading to diminished performance on complex tasks.
Creating the right dataset
Another challenge lies in the data generation process. Creating a comprehensive dataset of teacher model outputs for training the student model can be time-consuming and computationally intensive. Ensuring that this dataset adequately represents the full capabilities of the teacher is crucial for effective large language model distillation.
Technical complexity
Technical complexity is also a factor. Fine-tuning the student model requires expertise in selecting appropriate hyperparameters and optimization techniques. Additionally, during LLM model distillation, careful attention must be paid to prevent the propagation of biases present in the teacher model, which can complicate the training process.
Getting Started with Model Distillation
Model Distillation with OpenAI
OpenAI provides a structured process for distilling models, leveraging tools like Evaluations and Stored Completions. Here's a step-by-step guide:
-
Create an Evaluation: Begin by creating an evaluation to measure the performance of the larger model you wish to distill from—let's say GPT-4o. This evaluation will help you quantify how well the distilled model needs to perform, and serves as a benchmark to continuously test the distilled model's performance against the original, ensuring it meets your criteria before deployment.
-
Generate a Distillation Dataset with Stored Completions: Use the larger model to generate outputs for a variety of input prompts relevant to your application. When making API calls to the Chat Completions endpoint, set the
store:trueflag. This automatically saves the input-output pairs without impacting latency.
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "what's the capital of the USA?"
}
]
}
],
store=True,
metadata={"username": "user123", "user_id": "123", "session_id": "123"}
)
Source: OpenAI model distillation
Review, filter, and tag these stored completions to create a high-quality dataset suitable for fine-tuning. This dataset captures the knowledge from the larger model, essential for the knowledge distillation of large language models.
-
Fine-Tune the Smaller Model: Use the curated dataset as your training file. Upload it to OpenAI's platform to initiate the fine-tuning process. Adjust settings such as learning rate, batch size, and number of epochs to optimize the training before starting the fine-tuning process to distill the large language model into your chosen smaller model. This helps the smaller model—like GPT-3.5-turbo—learn effectively from the distilled data.
-
Evaluate the Distilled Model: Use the evaluation set up earlier to assess the distilled model's performance. Compare its outputs to those of the original larger model. Checking key metrics like accuracy, relevance, and coherence against established LLM benchmarks to determine if the model meets your performance standards.
-
Iterate and Refine: If the distilled model isn't performing as desired, identify areas where it's underperforming. Add more examples, especially focusing on the problematic areas: this enhances the dataset's ability to teach the smaller model. Fine-tune the hyperparameters to see if performance improves. Iterate through fine-tuning and evaluation until the distilled model's performance is satisfactory.
-
Deploy the Distilled Model: Once the model meets your criteria, deploy it using OpenAI's API. Leverage the efficiency of the smaller model to scale your application across various platforms and devices.
Benefits of OpenAI Model Distillation
-
Reduced API costs: Model distillation can be a very effective way to reduce API costs without sacrificing performance, providing the distilled model matches larger model performance.
-
Faster response times: Smaller models will run faster, making model distillation an effective way to reduce latency.
-
Integrated platform: Model distillation is integrated with OpenAI’s platform, making it easier to get started if you’re already using OpenAI.
Challenges of OpenAI Model Distillation
-
Restricted selection of models: OpenAI model distillation is restricted to the models which they serve, such as GPT-4o. Meaning you can’t fine-tune small but powerful models like Claude Haiku.
-
Limited evaluations: OpenAI requires that you upload a JSON file with prompts and completions before creating an evaluator. The evaluators and judgment types are currently restricted.
-
Technical User-interface: The user-interface for collecting data and running evaluations on OpenAI is designed for technical users, making it difficult for non-technical domain experts to provide critical feedback on model output.
-
Inability to self-host: OpenAI doesn’t allow you to self-host evaluations or model data to distill open-source models which can be self-hosted.
Alternatives to OpenAI Model Distillation
Humanloop is an LLM evaluations platform for enterprises with best-in-class tooling for prompt management and observability. Humanloop’s interface is friendly for technical and non-technical users and contains a suite of collaborative features. This enables teams to adopt best practices for putting LLMs into production, while having the freedom to choose model providers and preferred hosting options.
Enterprises use Humanloop to enable model distillation as it offers a comprehensive feature set for evaluations and prompt management with more flexibility for deployment. To learn more, chat with our team today.
About the author

- 𝕏@conorkellyai










