September
Evaluations Comparison Mode
September 25th, 2024
We’ve added a side-by-side comparison view to evaluations on Humanloop. This new view enables domain experts to view multiple outputs side-by-side and provide judgments with easy-to-use, configurable controls.
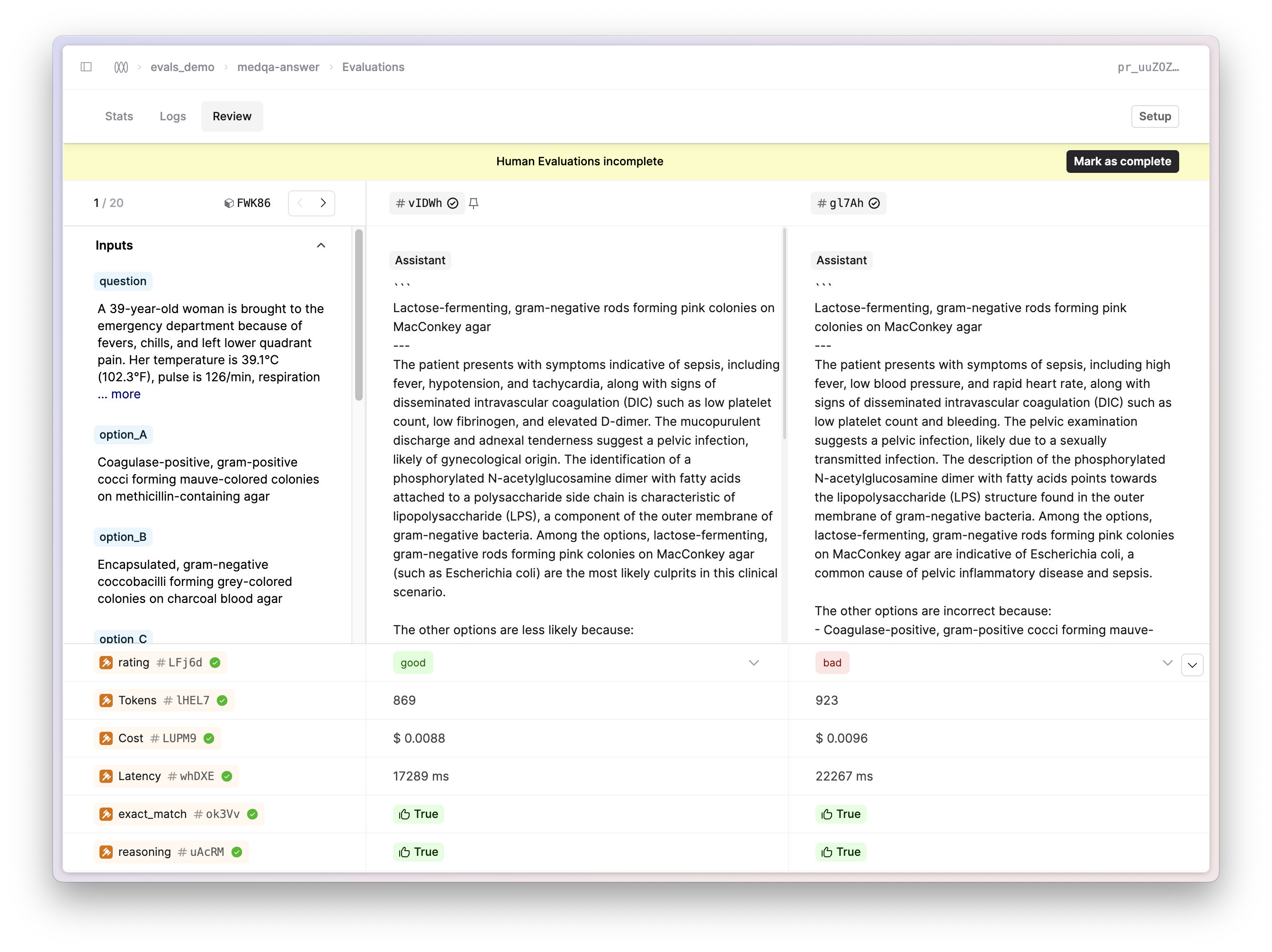
To start using this new view, choose a File and click on the Evaluations submenu. Select the eval you want to view and navigate to the Review tab. This is particularly useful when trying to compare and contrast the outputs from different versions of your AI apps when providing relative judgements.
Bedrock support for Llama models
September 20th, 2024
We’ve added support for Llama models through our AWS Bedrock integration.
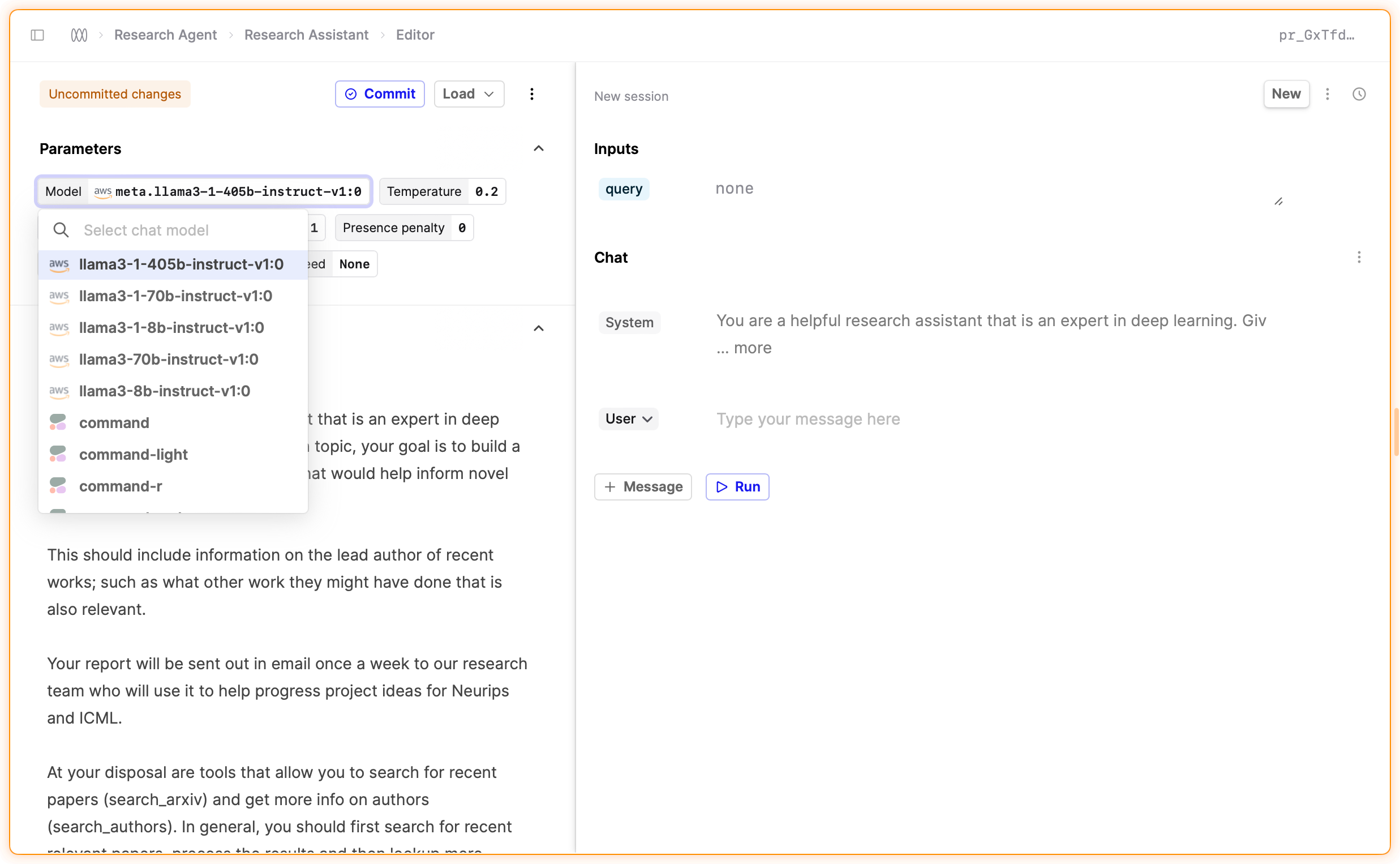
You can now select Llama models in the model selection dropdown in the Prompt Editor and start using them in your Prompts. Humanloop supports tool calling for Llama 3.1 models, helping you to build more powerful AI applications.
Evaluation Names
September 17th, 2024
You can now name your Evaluations in the UI and via the API. This is helpful for more easily identifying the purpose of your different Evaluations, especially when multiple teams are running different experiments.
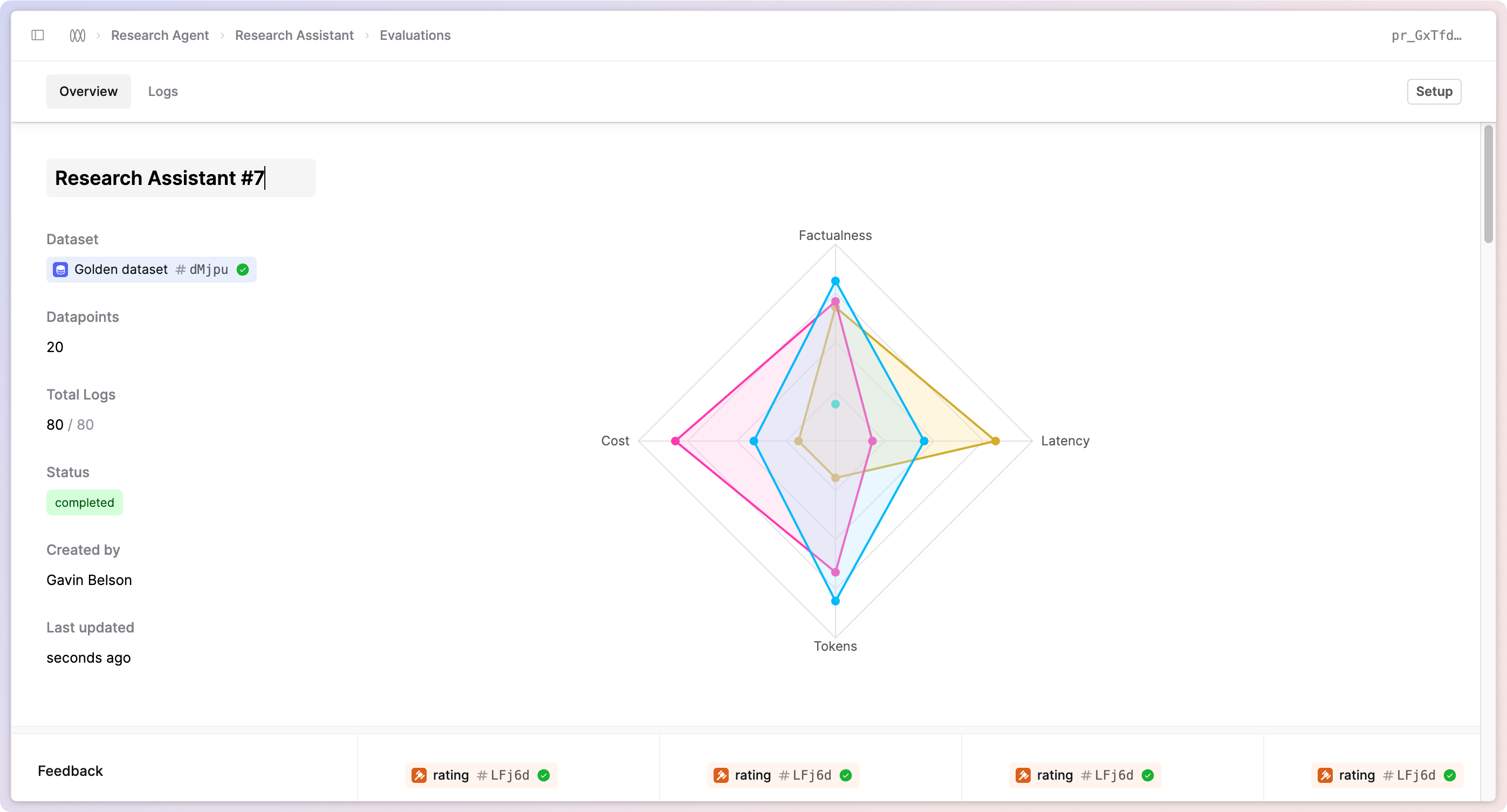
In the API, pass in the name field when creating your Evaluation to set the name. Note that names must be unique for all Evaluations for a specific file. In the UI, navigate to your Evaluation and you will see an option to rename it in the header.
Introducing Flows
September 15th, 2024
We’ve added a new key building block to our app with the first release of Flows. This release focuses on improving the code-first workflows for evaluating more complex AI applications like RAG and Agent-based apps.
Flows allow you to version your whole AI application on Humanloop (as opposed to just individual Prompts and Tools) and allows you to log and evaluate the full trace of the important processing steps that occur when running your app.
See our cookbook tutorial for examples on how to use Flows in your code.
What’s next
We’ll soon be extending support for allowing Evaluators to access all Logs inside a trace. Additionally, we will build on this by adding UI-first visualisations and management of your Flows.
We’ll sunset Sessions in favour of Flows in the near future. Reach out to us for guidance on how to migrate your Session-based workflows to Flows.
Bedrock support for Anthropic models
September 13th, 2024
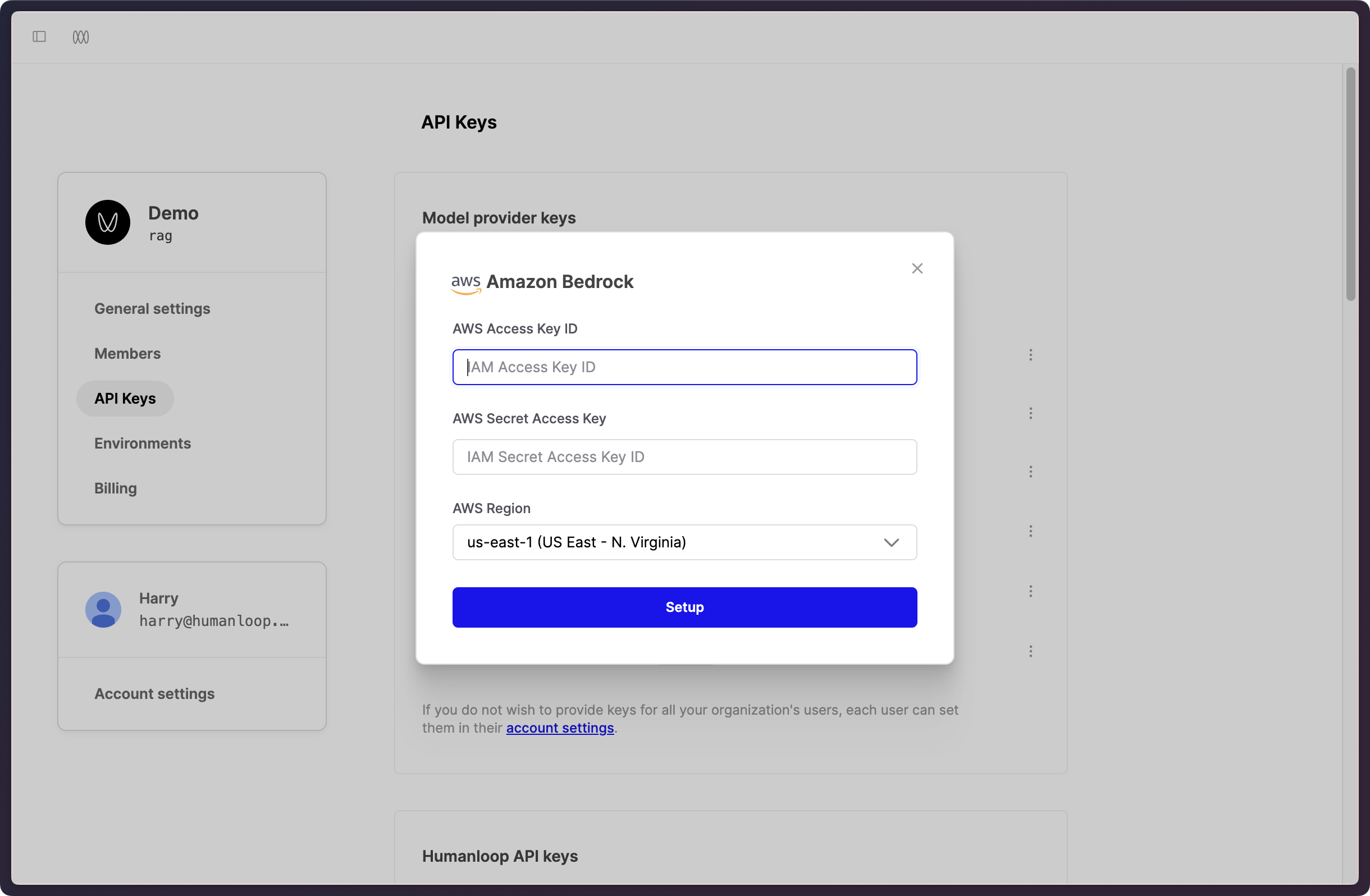
We’ve introduced a Bedrock integration on Humanloop, allowing you to use Anthropic’s models via the Bedrock API, leveraging your AWS-managed infrastructure.
To set this up, head to the API Keys tab in your Organization settings here. Enter your AWS credentials and configuration.
Once you’ve set up your Bedrock keys, you can select the Anthropic models in the model selection dropdown in the Prompt Editor and start using them in your Prompts.
OpenAI o1
September 10th, 2024
We added same day support for OpenAI’s new models, the o1 series. Unlike their predecessors, the o1 models have been designed to spend more time thinking before they respond. In practise this means that when you call the API, time and tokens are spent doing chain-of-thought reasoning before you receive a response back.
Read more about this new class of models in OpenAI’s release note and their documentation.
These models are still in Beta and don’t yet support streaming or tool use, the temperature has to be set to 1 and there are specific rate limits in place.
Evaluations CICD Improvements
September 5th, 2024
We’ve expanded our evaluations API to include new fields that allow you to more easily check on progress and render summaries of your Evaluations directly in your deployment logs. Note: /stats endpoint has been deprecated in V4
The stats response now contains a status you can poll and progess and report fields that you can print:
See how you can leverage Evaluations as part of your CICD pipeline to test for regressions in your AI apps in our reference example.