October
Evals Comparison Mode shortcuts
October 25th, 2024
We’ve added keyboard shortcuts to the side-by-side comparison view to help you and your domain experts work through review tasks more efficiently and quickly.
While on the review tab, press the arrow keys ⬆️, ⬇️, ⬅️, or ➡️ to navigate between judgment cells, and press Enter to edit the judgment.
You can also press keys J and K to switch between datapoints without having to use your mouse or trackpad.
Onboarding improvements
October 24th, 2024
We’ve improved how we introduce Humanloop to new users. We’ve highlighted more the common workflow of triggering evals from code for existing AI apps.
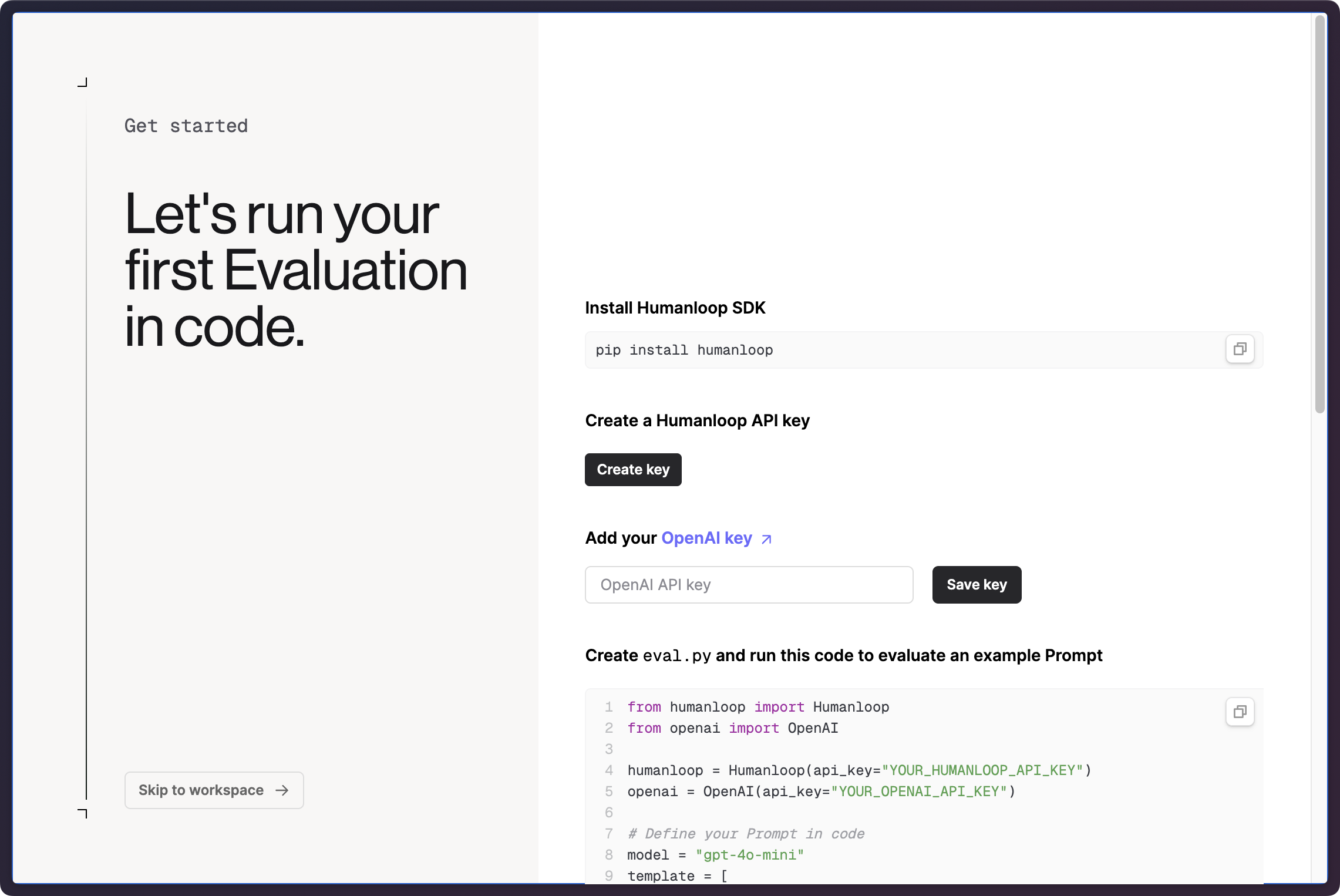
Evals code example
When you first enter Humanloop, we’ll give you a code snippet demonstrating how to run an eval on a simple Prompt - you can skip this step and continue in the UI and we’ll create an example Prompt for you.
If you’re new to Humanloop, these will introduce our key concepts of our Prompts and Evals. If you’re already on Humanloop, you can find a similar example in our updated doc quickstarts.
Example Evaluators
As part of these improvements, Humanloop will now provide new organizations with a set of example Evaluators to showcase the range of use cases and what the different Evaluator types (AI, code, and Human) can be used for.
SDK utility
We’ve also continuing to extend the utilities within our SDKs, adding a humanloop.prompts.populate_template(...) utility function to the Python SDK to make it easier to use Prompt templates while making your own calls to the model provider. Coming to TypeScript soon.
Claude 3.5 Sonnet
October 20th, 2024
We added same day support for Anthropic’s new Claude 3.5 Sonnet model. This latest version is reported to have improved performance across the board over its predecessor, in particular on coding tasks - read more here.
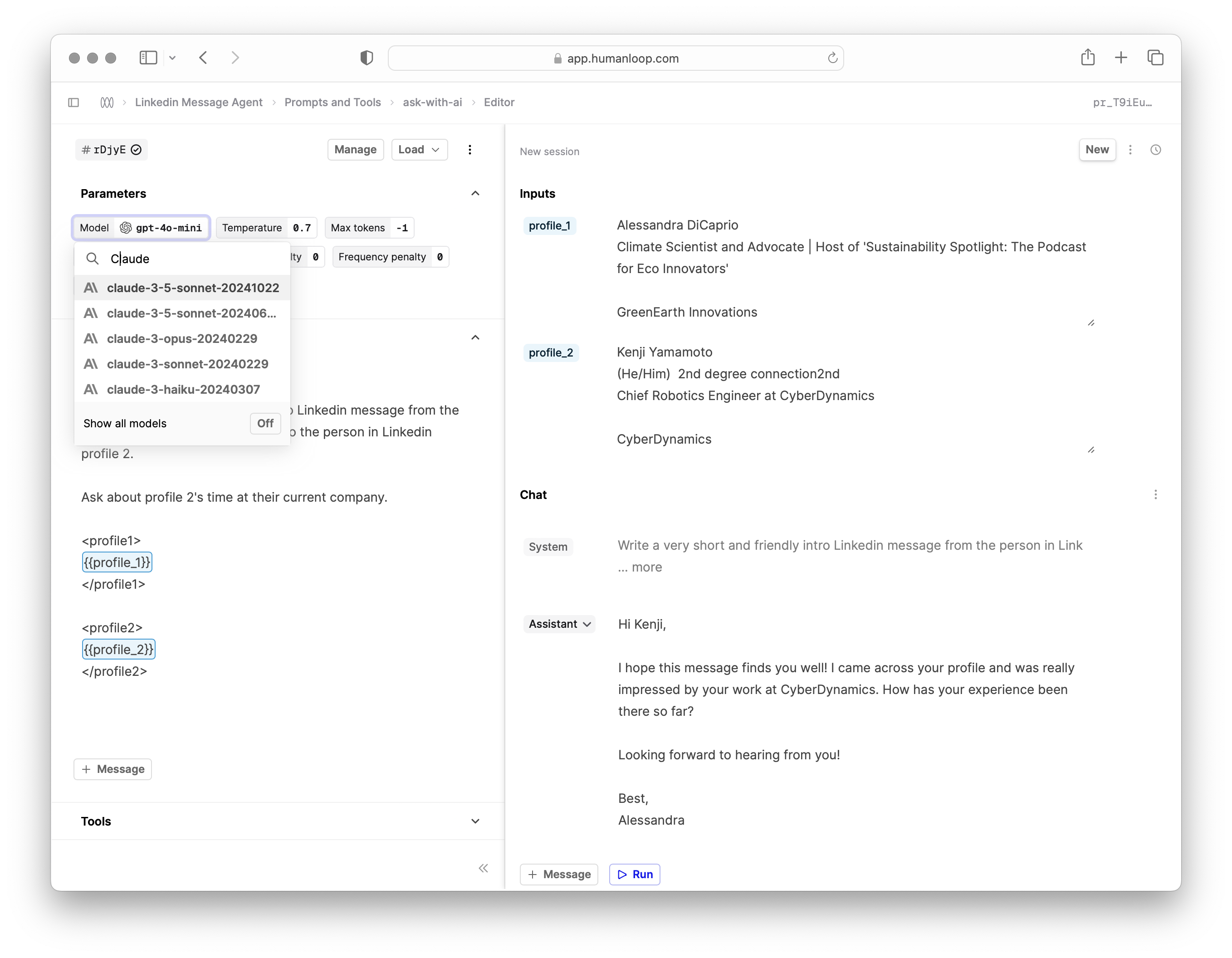
We’ve added support both for our Anthropic and Bedrock provider integrations.
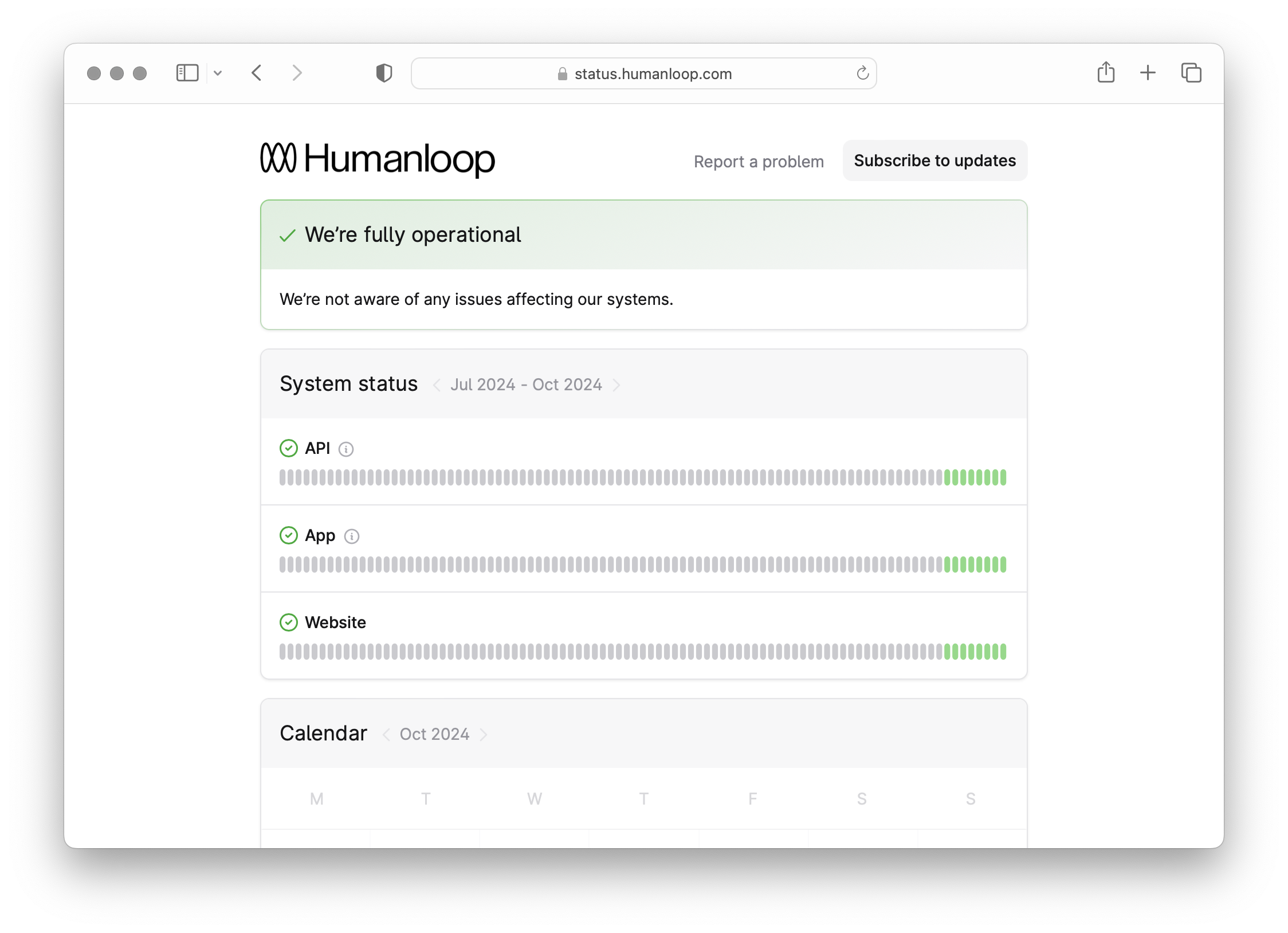
Humanloop Status Page
October 18th, 2024
We’ve published a public status page for any incidents or maintenance that may affect the Humanloop app, api, or website moving forward.
You can use this page to report problems and subscribe to timely updates on the status of our services.
This is part of an ongoing initiative to maintain reliability and trust in our services as we continue to scale.
Improved Dataset Upload
October 17th, 2024
We’ve added the ability to map your input and target columns to the columns in your .csv on upload. This provides more flexibility to users who predominately use the UI to manage Datasets.
When you upload a CSV via the Dataset Editor you will see a new mapping step that allows you to select which columns will be mapped to which dataset fields.
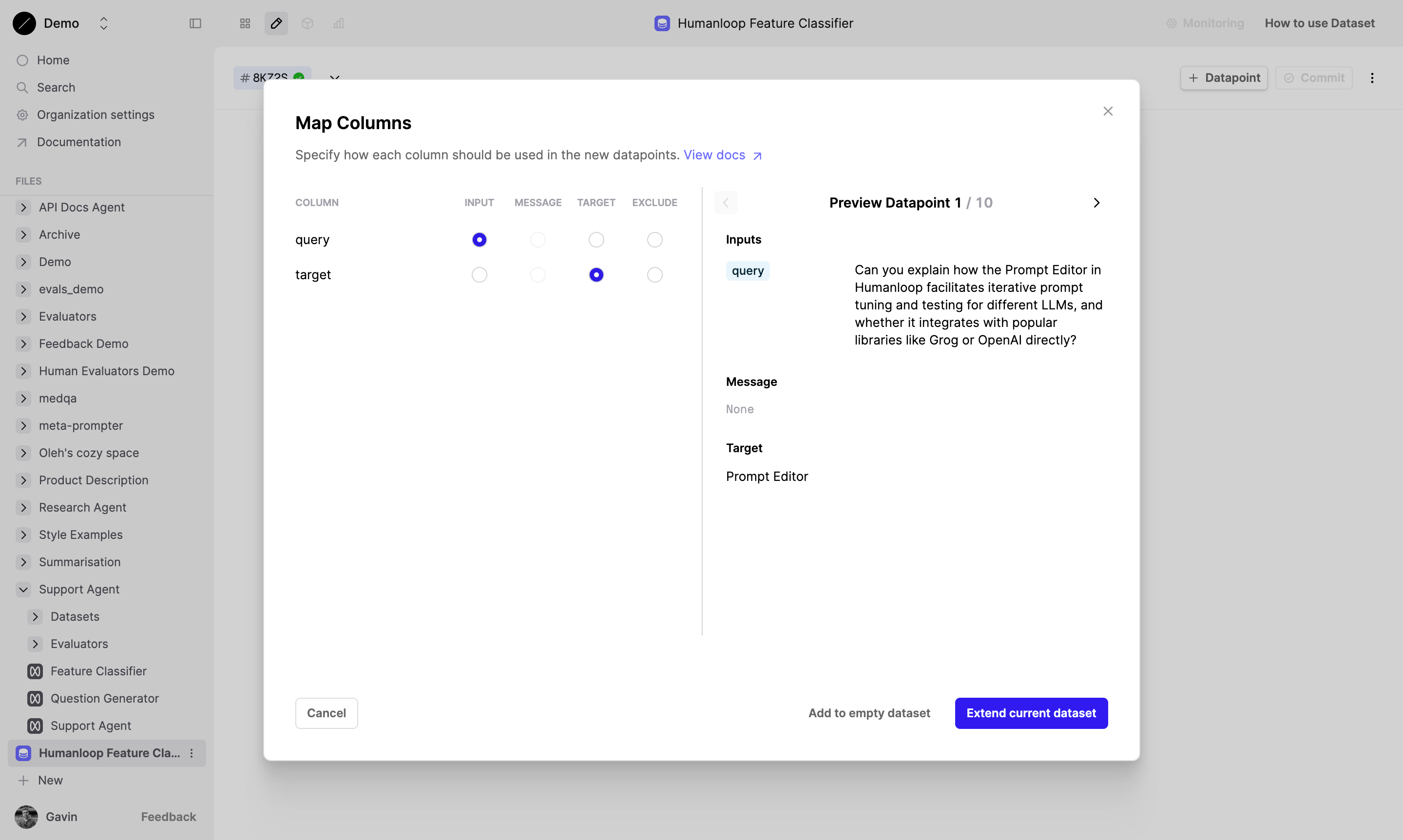
To learn more about Datasets on Humanloop you can check out our Datasets page.
Evaluate Flow Log contents
October 16th, 2024
Flow Logs allow users to represent complex multi-step apps on Humanloop. Each step can be a Prompt, Tool, or Evaluator Log; or even another Flow Log. Logs can also be nested so that you can represent your app’s execution trace.
Prior to now, Evaluators could only reference the inputs and outputs of Flow Logs when providing Judgments. We’ve now added the ability to access the entire contents of a Flow Log in an Evaluator. This allows you to write more complex Evaluators that can inspect the entire execution trace of your app.
How to use
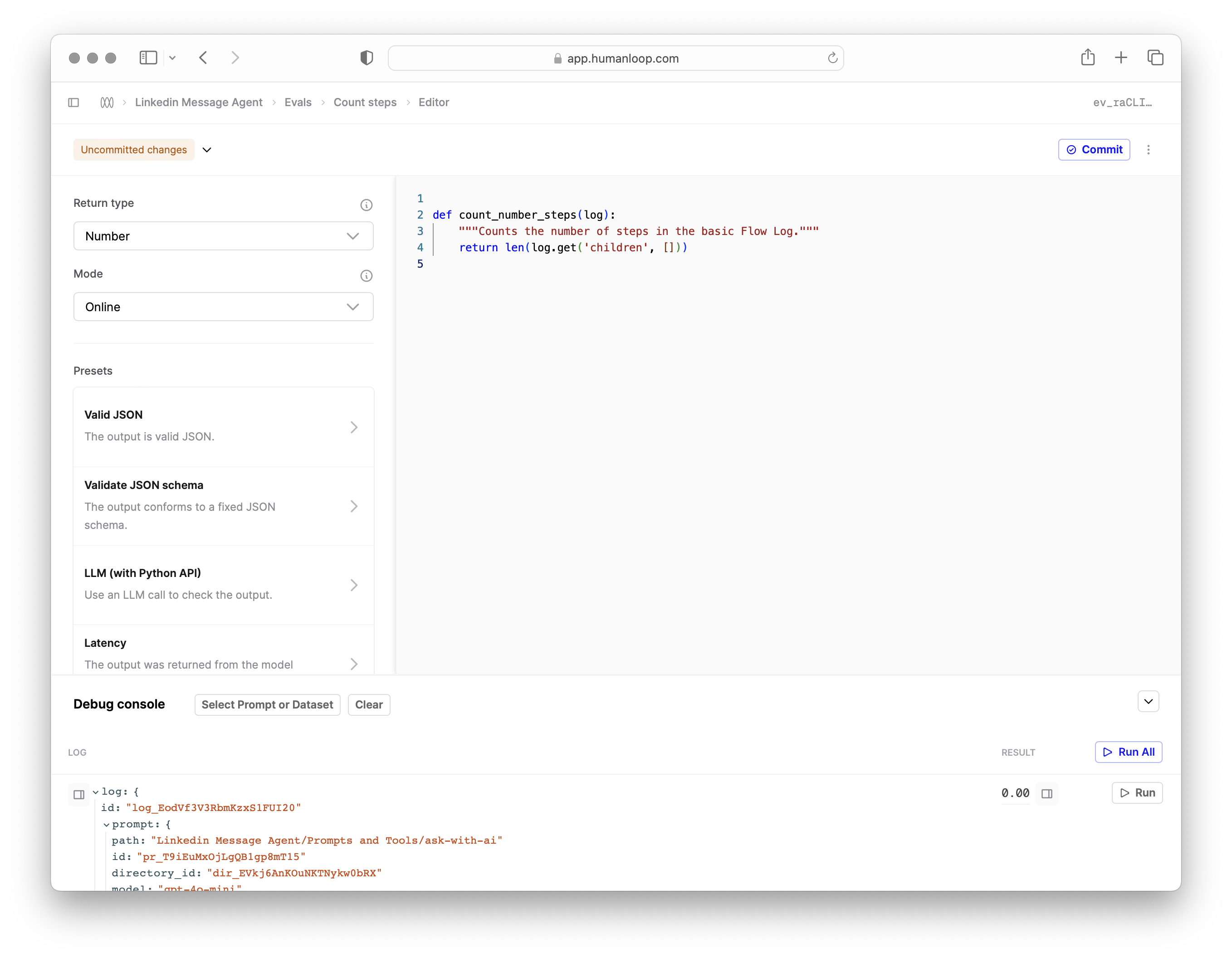
The contents of the Flow Log are accessible via the newchildren field. Logs within the trace can also have children depending on the level of nesting in your code.For example, if your Flow Log represent a conversation between a user and a chatbot, you can now write an Evaluator that inspects the entire conversation to make a judgement. Below is a simple example of checking how many steps there were in the conversation:
Or maybe you want to count how many Logs in the trace returned an empty output, where there may have been nesting:
You can access children within any of the Evaluator Editors.
Export Datasets
October 14th, 2024
You can now export your Datasets on Humanloop to .csv directly from within the UI. This allows you to more rapidly iterate on your Dataset in spreadsheet tools before re-uploading.
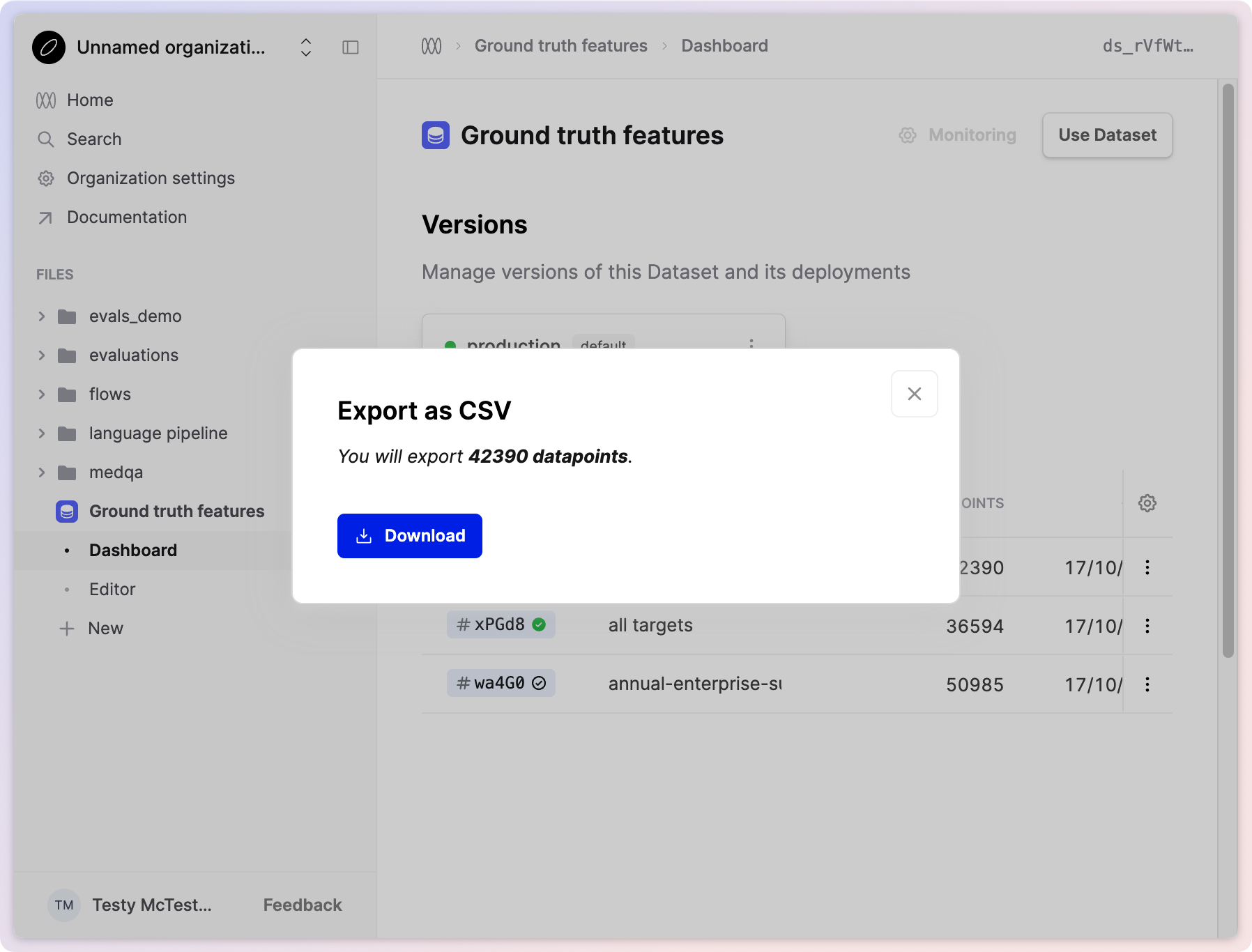
You can find this option both within the Dataset Editor and from your existing versions on the Dataset Dashboard.
Evals Comparison Mode Improvements
October 12th, 2024
We’re continuing to invest in our review UI to make it easier for you and your domain experts to work through review tasks more efficiently and quickly.
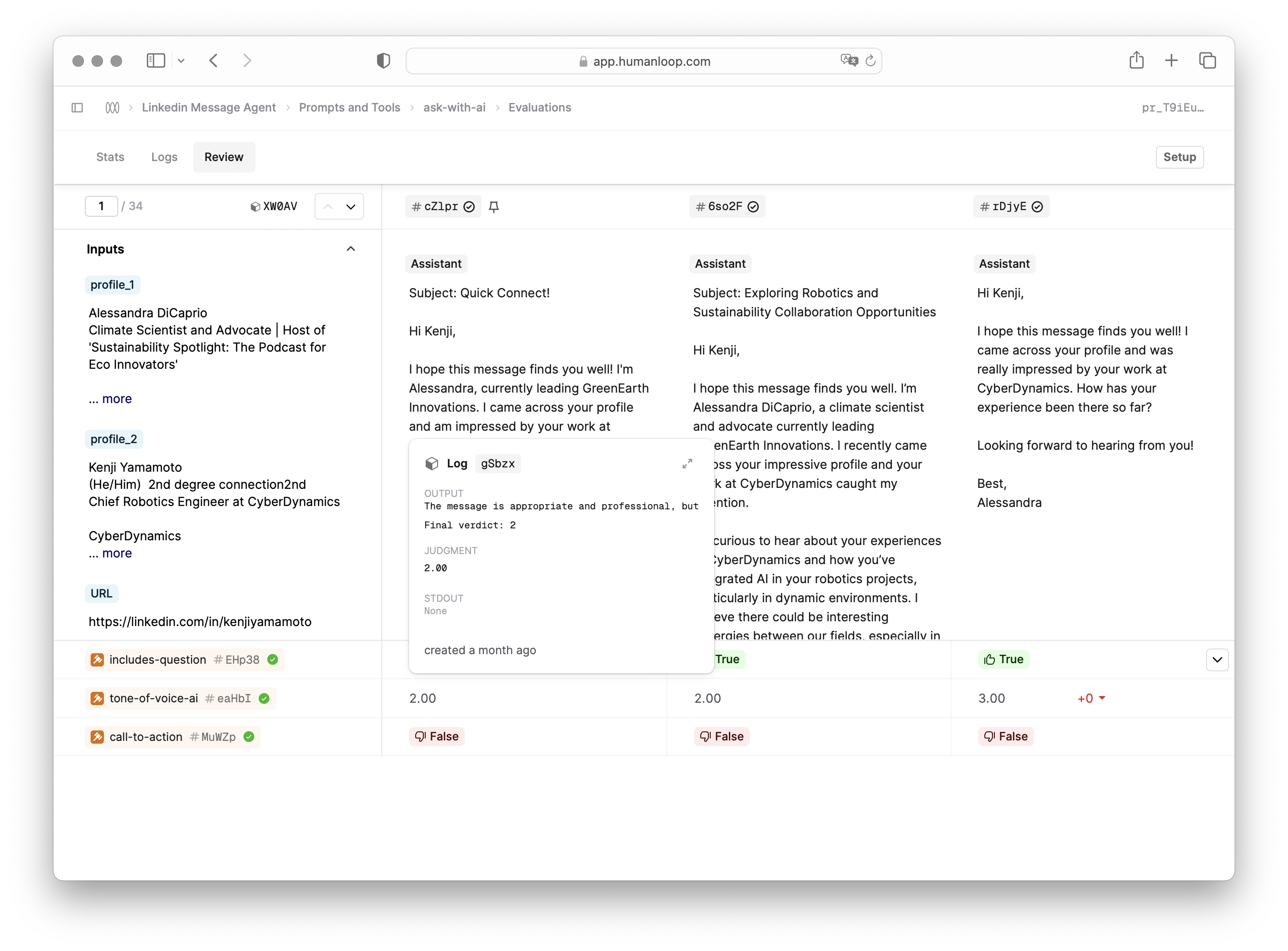
More easily access additional context
You can now hover over judgments in the Review tab to access additional context. It’s especially useful to get information like instructions and additional outputs (such as when an LLM evaluator outputs rationale alongside the final judgment). You can also click to expand to the full drawer view.
Share deep links to specific datapoints
You can now share links to a specific datapoint in the Review tab. Simply select the desired datapoint and copy the URL. Team members who open the link will be directed to the same datapoint.
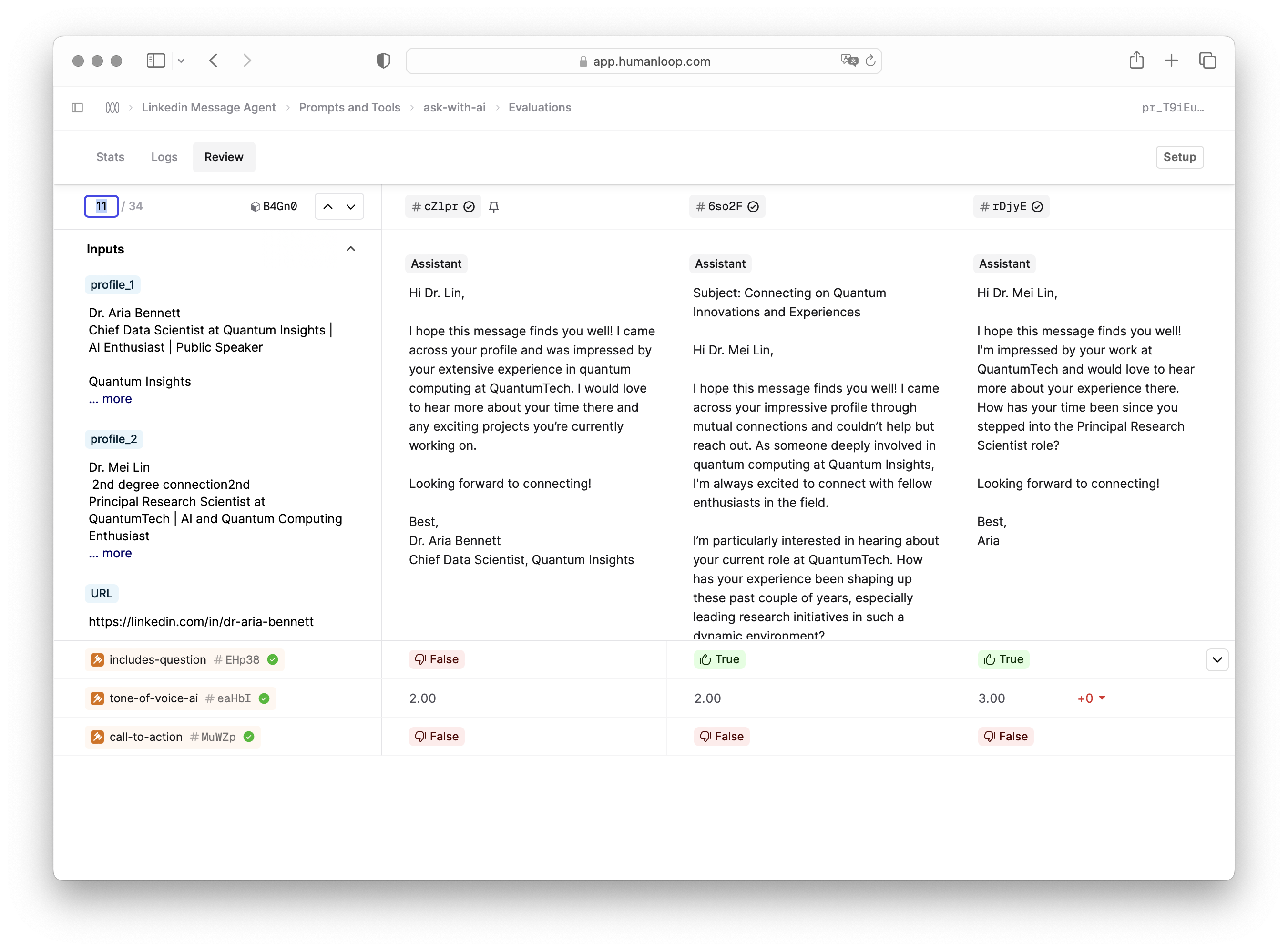
Navigate to specific datapoints by index
Using the new text box at the top left of the Review tab, you can now jump to a specific datapoint by index.
This can be helpful when you need to split up the review amongst multiple team members; each can take a different range of datapoints to review.
Improved Dataset Upload
October 10th, 2024
We’ve added the ability to map your input and target columns to the columns in your .csv on upload. This provides more flexibility to users who predominately use the UI to manage Datasets.
When you upload a CSV via the Dataset Editor you will see a new mapping step that allows you to select which columns will be mapped to which dataset fields.
To learn more about Datasets on Humanloop you can check out our Datasets page.
Evaluations SDK Improvements
October 3rd, 2024
We’ve added a new run method for evaluations to our SDK. This provides a simpler
entry point for evaluating your existing pipelines, both in your CICD and experimentation
workflows. This is currently available in Beta on Python and will soon be added to the major versions of both Py and TS SDKs.
In order to run an eval via the SDK, you need to provide:
- A callable function that takes your inputs/messages and returns a string
- A Dataset of inputs/message to evaluate the function against
- A set of Evaluators to use to provide judgments
Here is a toy example using a simple OpenAI call as the function to evaluate.
Running this will provide status info and an eval summary in your CLI and a new eval will appear on Humanloop at the
displayed URL. Running it again under the same name will add runs to the existing eval.
It returns a set of checks you can use to determine whether the eval passed or failed.
Introduce versioning
The only thing distinguishing different eval runs under the same eval name so far is the time stamp they were run.
It can also be helpful to record what the configuration of your system was when running the eval.
You can include arbitrary config within the version field of the file. If this
version has been used before, Humanloop will automatically associate it to your run. If the
config is new, we will automatically create a new version of your file for future reference.
Leverage native Prompts
Using hl.evaluations.run(...) will by default create a Flow on Humanloop. Flows have
the advantage of being able to represent more complex traces, but can’t be run natively
within the Humanloop Editor.
It’s also possible to adapt the run call to instead evaluate Prompts
by defining the type as prompt and providing valid Prompt params in the version field.
Add Evaluator thresholds
You can also now provide a threshold value for each of your Evaluators.
If provided, the checks return will determine whether the average performance
of the Evaluator met the threshold or not.
Manage Directories via API
October 1st, 2024
You can now manage directories directly using our API. This can be helpful for programmatically managing your workspace for bulk changes or dynamically creating folder structures.
To learn more about directories on Humanloop you can check out our Directories page.