Run a Human Evaluation
Collect judgments from subject-matter experts (SMEs) to better understand the quality of your AI product.
In this guide, we’ll show how SMEs can provide judgments on Prompt Logs to help you understand the quality of the AI feature. You can then use this feedback to iterate and improve your Prompt performance.
Prerequisites
- You have set up a Human Evaluator appropriate for your use-case. If not, follow our guide to create a Human Evaluator.
- You have a Dataset with test data to evaluate model outputs against. If not, follow our guide to create a Dataset from already existing Logs.
Provide judgments on Logs
In this guide, we assume you have already created a Prompt and a Dataset for an evaluation. Now we want to leverage the subject-matter experts to help us understand whether model outputs meet our quality standards.
Create a new Evaluation
Navigate to the Prompt you want to evaluate and click on the Evaluation tab at the top of the page. Click on Evaluate to create a new Evaluation.
Create a new Run
To evaluate a version of your Prompt, click on the +Run button, then select the version of the Prompt you want to evaluate and the Dataset you want to use. Click on +Evaluator to add a Human Evaluator to the Evaluation.
You can find example Human Evaluators in the Example Evaluators folder.
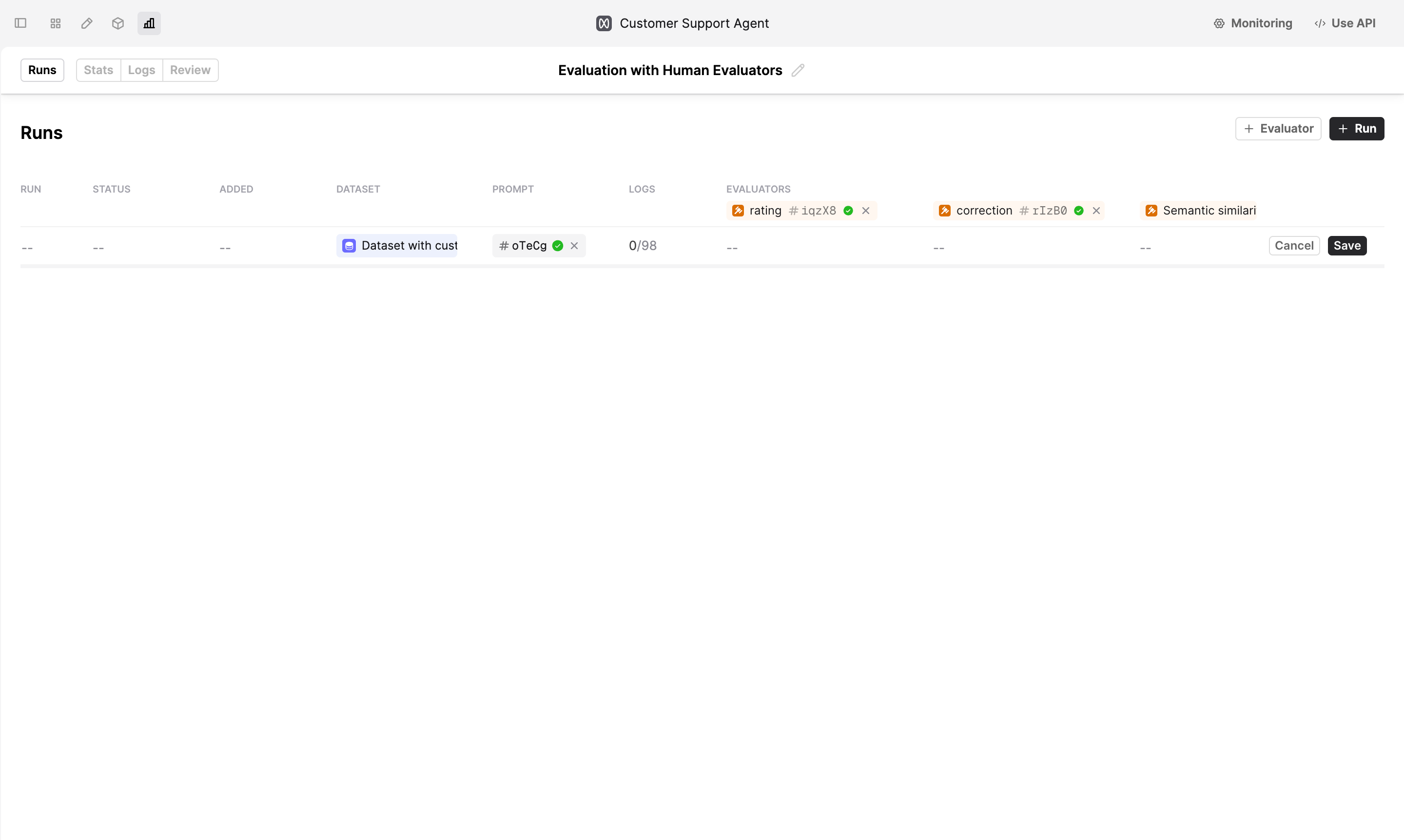
Click Save to create a new Run. Humanloop will start generating Logs for the Evaluation.
Improve the Prompt
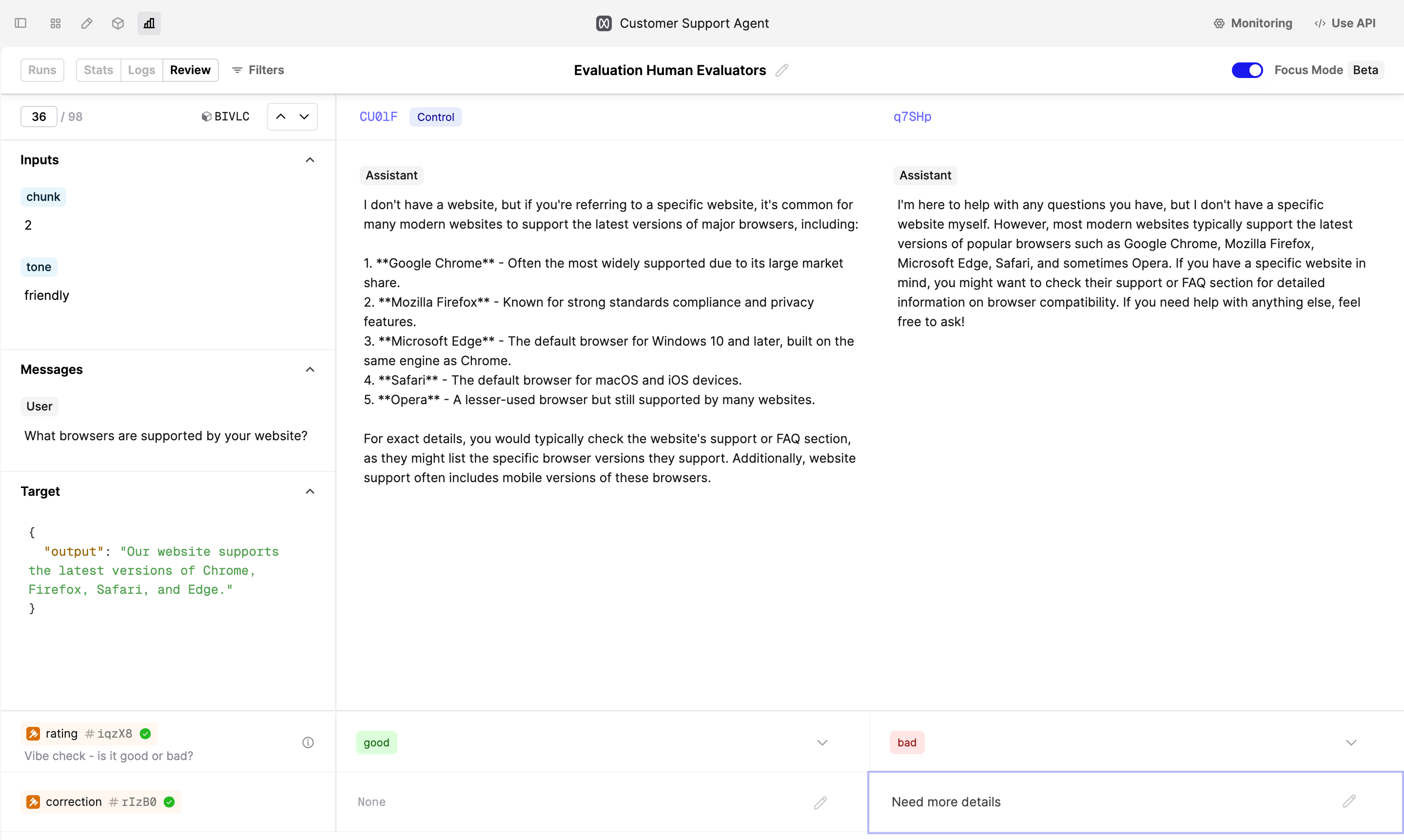
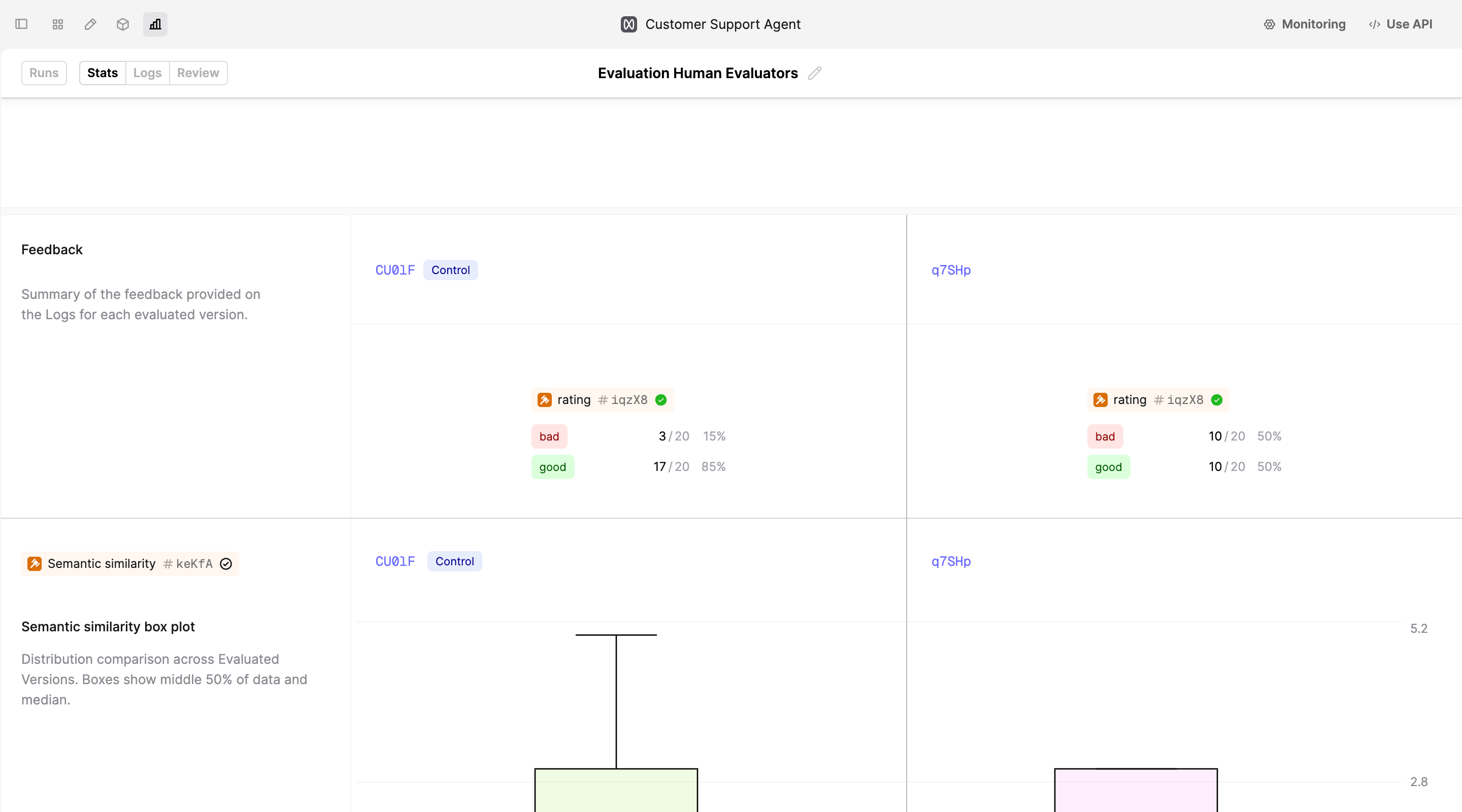
Explore the Logs that the SME flagged in the Review tab.
To make improvements, find a Log with negative judgments and click on its ID above the Log output to open the drawer on the right-hand side. In the drawer, click on the Editor -> button to load the Prompt Editor. Now, modify the instructions and save a new version.
Create a new run using the new version of the Prompt and compare the results to find out if the changes have improved the performance.
Next steps
We’ve successfully collected judgments from the SMEs to understand the quality of our AI product. Explore next:
- If your team has multiple internal SMEs, learn how to effectively manage evaluation involving multiple SMEs.
- If SMEs provided negative judgments on the logs, please refer to our guide on Comparing and Debugging Prompts.