Spot-check your Logs
Spot-check your Logs
How to create an Evaluation Run to review a sample of your Logs, ensuring your model generations remain high-quality.
By regularly reviewing a sample of your Prompt Logs, you can gain valuable insights into the performance of your Prompts in production, such as through reviews by subject-matter experts (SMEs).
For real-time observability (typically using code Evaluators), see our guide on setting up monitoring. This guide describes setting up more detailed evaluations which are run on a small subset of Logs.
Prerequisites
- You have a Prompt with Logs. See our guide on logging to a Prompt if you don’t yet have one.
- You have a Human Evaluator set up. See our guide on creating a Human Evaluator if you don’t yet have one.
Install and initialize the SDK
First you need to install and initialize the SDK. If you have already done this, skip to the next section.
Open up your terminal and follow these steps:
- Install the Humanloop SDK:
- Initialize the SDK with your Humanloop API key (you can get it from the Organization Settings page).
Set up an Evaluation
Create an Evaluation
Create an Evaluation for the Prompt. In this example, we also attach a “rating” Human Evaluator so our SMEs can judge the generated responses.
You have now created an Evaluation Run with a sample of Logs attached to it. In the Humanloop app, go to the Prompt’s Evaluations tab. You should see the new Evaluation named “Monthly spot-check”. Click on it to view the Run with the Logs attached.
Review your Logs
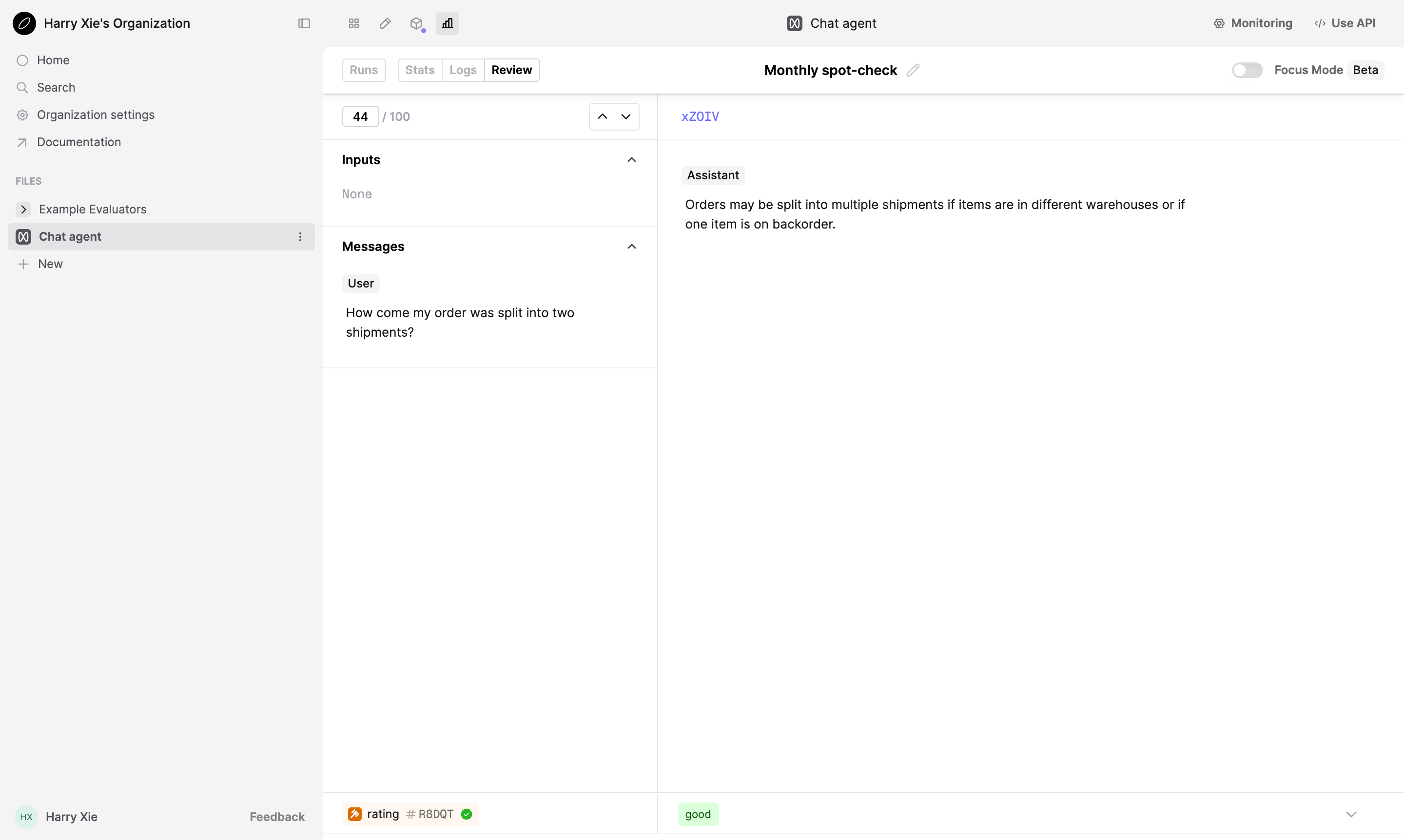
Rate the model generations via the Review tab.
For further details on how you can manage reviewing your Logs with multiple SMEs, see our guide on managing multiple reviewers.
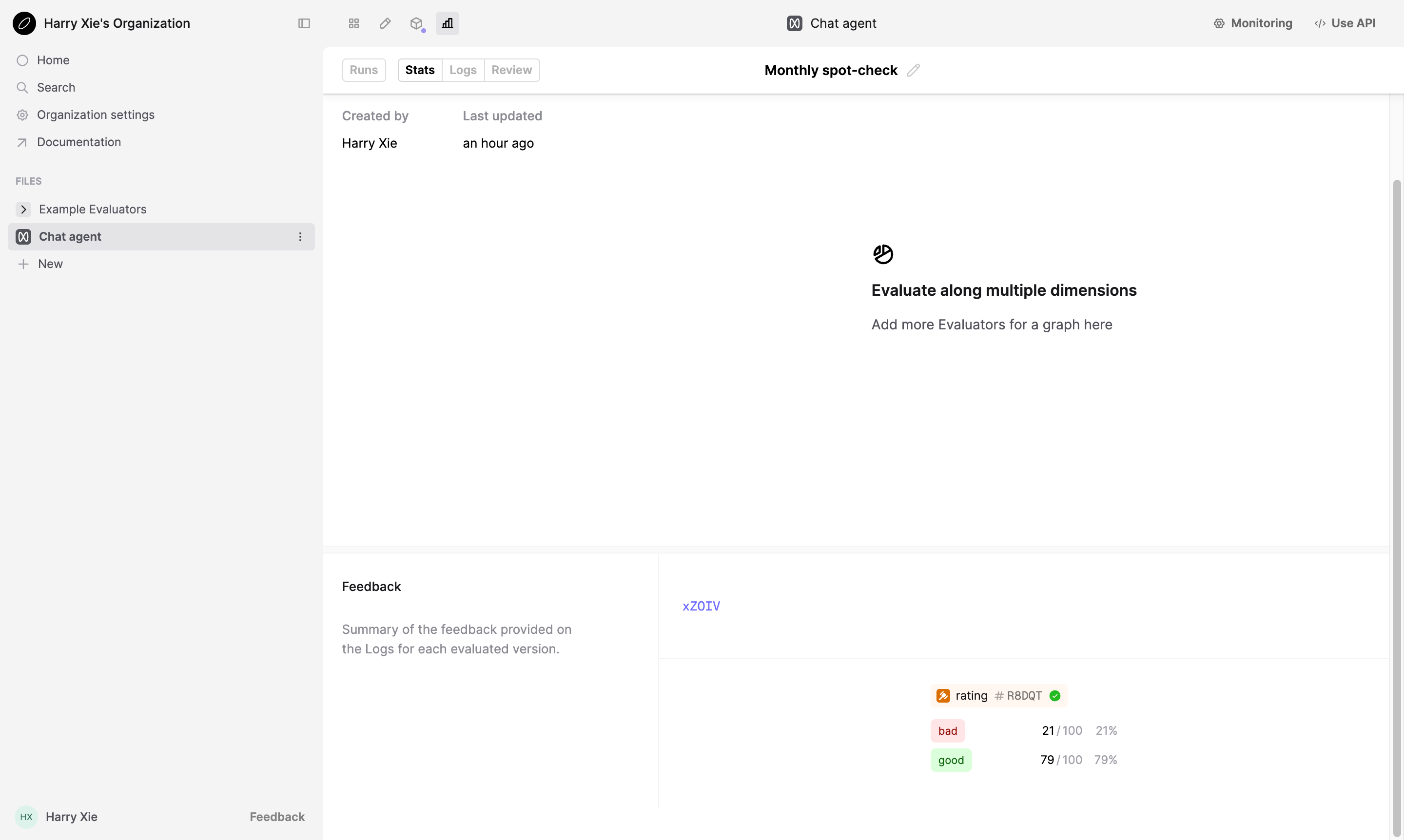
After your Logs have been reviewed, go to the Stats tab to view aggregate stats.
Repeating the spot-check
To repeat this process the next time a spot-check is due, you can create a new Run within the same Evaluation, repeating the above steps from “Create a Run”. You will then see the new Run alongside the previous ones in the Evaluation, and can compare the aggregate stats across multiple Runs.
Next Steps
- If you have performed a spot-check and identified issues, you can iterate on your Prompts in the app and run further Evaluations to verify improvements.