Flows
Instrument and monitor multi-step AI systems.

Introduction
LLM-powered systems are multi-step processes, leveraging information sources, delegating computation to tools, or iterating with the LLM to generate the final answer.
Looking at the inputs and output of such a system is not enough to reason about its behavior. Flows address this by tracing all components of the feature, unifying Logs in a comprehensive view of the system.
Basics
To integrate Flows in your project, add the SDK flow decorator on the entrypoint of your AI feature.
Python
TypeScript
The decorator will capture the inputs and output of the agent on Humanloop.
You can then start evaluating the system’s performance through code or through the platform UI.
Tracing
Additional Logs can be added to the trace to provide further insight into the system’s behavior.
On Humanloop, a trace is the collection of Logs associated with a Flow Log.
Python
TypeScript
The agent makes multiple provider calls to refine the response to the question. It makes function calls to search_wikipedia to retrieve additional information from an external source.
Calling the other functions inside call_agent creates Logs and adds them to the trace created by call_agent.
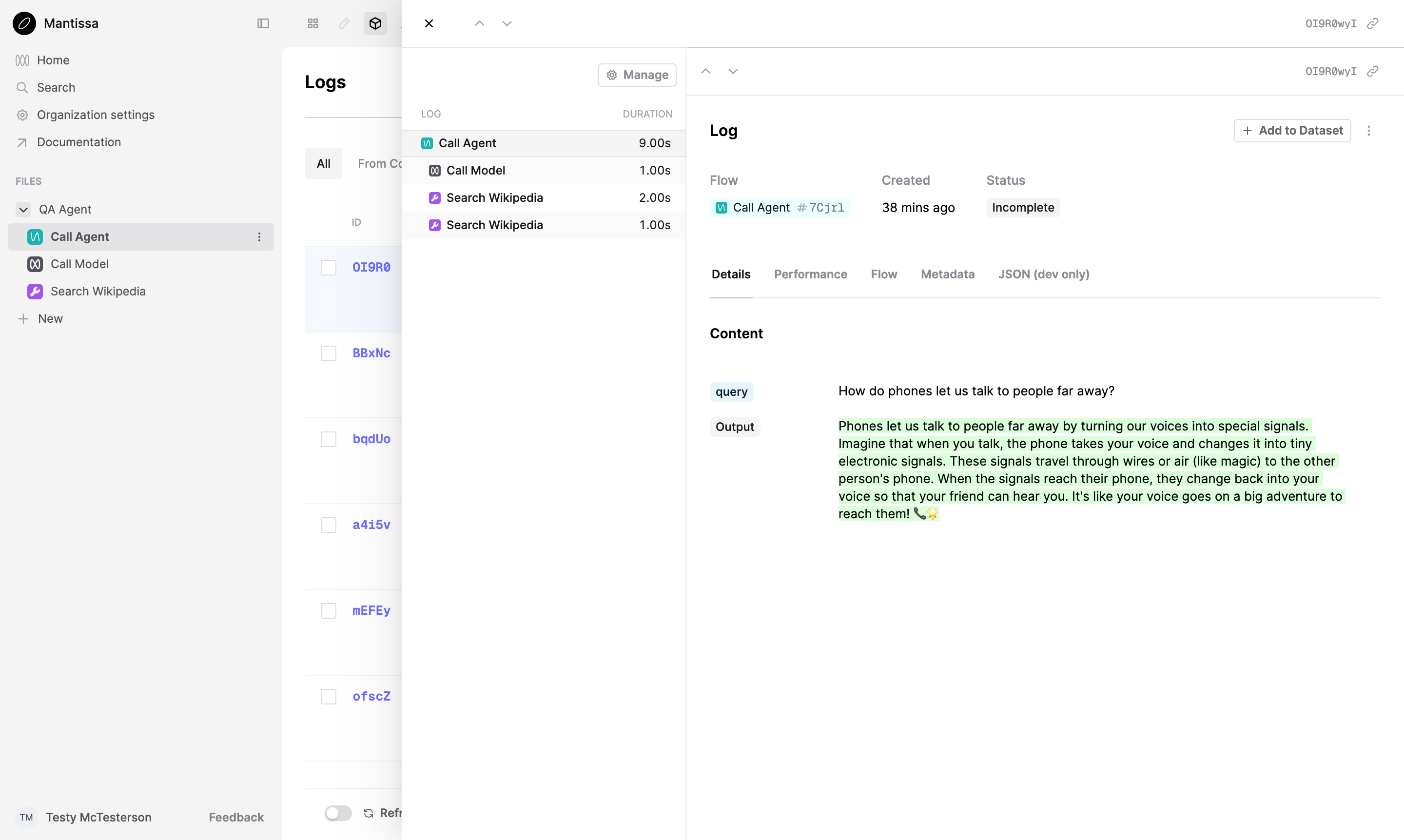
Manual Tracing
If you don’t want to use decorators, first create a Flow Log, then pass its id when creating Logs you want to add to the trace.
Code for Manual Tracing
Python
TypeScript
Versioning
Any data you pass into attributes will contribute to the version of the Flow. If you pass in a new value, the version will be updated.
Python
TypeScript
Completing Flow Logs
Flow Logs can be marked as complete in order to prevent further Logs from being added to the trace. The flow decorator will mark a trace as complete when the function returns.
A Flow Log’s metrics, such as cost, latency and tokens, are computed as Logs are added to the trace.
A Flow Log’s start_time and end_time are computed automatically to span the earliest start and latest end of the Logs in its trace. If start_time and end_time already span the Logs’ timestamps, they are kept as they are.
If you don’t want to use the decorator, you can complete the Flow Log via the SDK directly.
Code for Manual Tracing
Python
TypeScript
Evaluation
Unlike Prompts, which can be evaluated via the Humanloop UI, you must run evaluations on your Flows through code.
To do this, provide a callable argument to the evaluations.run SDK method.
Unlike other Logs, Evaluators added to Flows can access all Logs inside a trace:
Python
TypeScript
Every time a Log is added to a Flow trace, monitoring Evaluators and Evaluations re-evaluate the Log. This behaviour is throttled, so adding multiple Logs in quick succession will result in a single re-evaluation.
Next steps
You now understand the role of Flows in the Humanloop ecosystem. Explore the following resources to apply Flows to your AI project:
-
Check out our logging quickstart for an example project instrumented with Flows.