Run an Evaluation via the API
An Evaluation on Humanloop leverages a Dataset, a set of Evaluators and different versions of a Prompt to compare.
In this guide, we use a Dataset to evaluate the performance of different Prompt versions. To learn how to evaluate Prompts without a Dataset, see the guide on Spot-check your Logs.
Prerequisites
- A set of Prompt versions you want to compare - see the guide on creating Prompts.
- A Dataset containing datapoints for the task - see the guide on creating a Dataset via API.
- At least one Evaluator to judge the performance of the Prompts - see the guides on creating Code, AI and Human Evaluators.
Run an Evaluation
For this guide, we’re going to evaluate the performance of a Support Agent that responds to user queries about Humanloop’s product and documentation.
Our goal is to understand which base model between gpt-4o, gpt-4o-mini and claude-3-5-sonnet-20241022 is most appropriate for this task.
Create a Dataset
We defined sample data that contains user messages and desired responses for the Support Agent Prompt. We will now create a Dataset with these datapoints.
Create an Evaluation
We create an Evaluation Run to compare the performance of the different Prompts using the Dataset we just created.
For this guide, we selected Semantic Similarity, Cost and Latency Evaluators. You can find these Evaluators in the Example Evaluators folder in your workspace.
“Semantic Similarity” Evaluator measures the degree of similarity between the model’s response and the expected output. The similarity is rated on a scale from 1 to 5, where 5 means very similar.
Inspect the Evaluation stats
When Runs are completed, you can inspect the Evaluation Stats to see the summary of the Evaluators judgments.
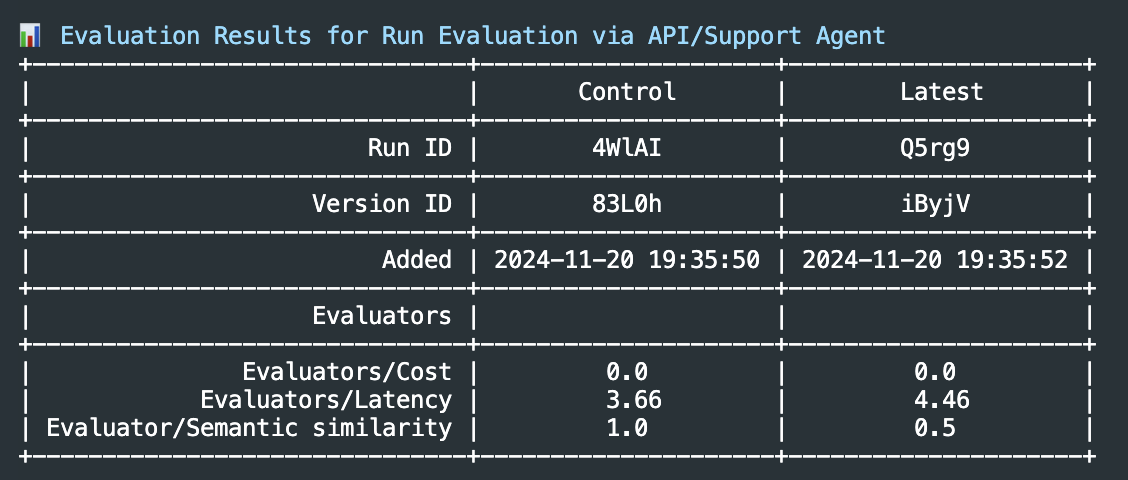
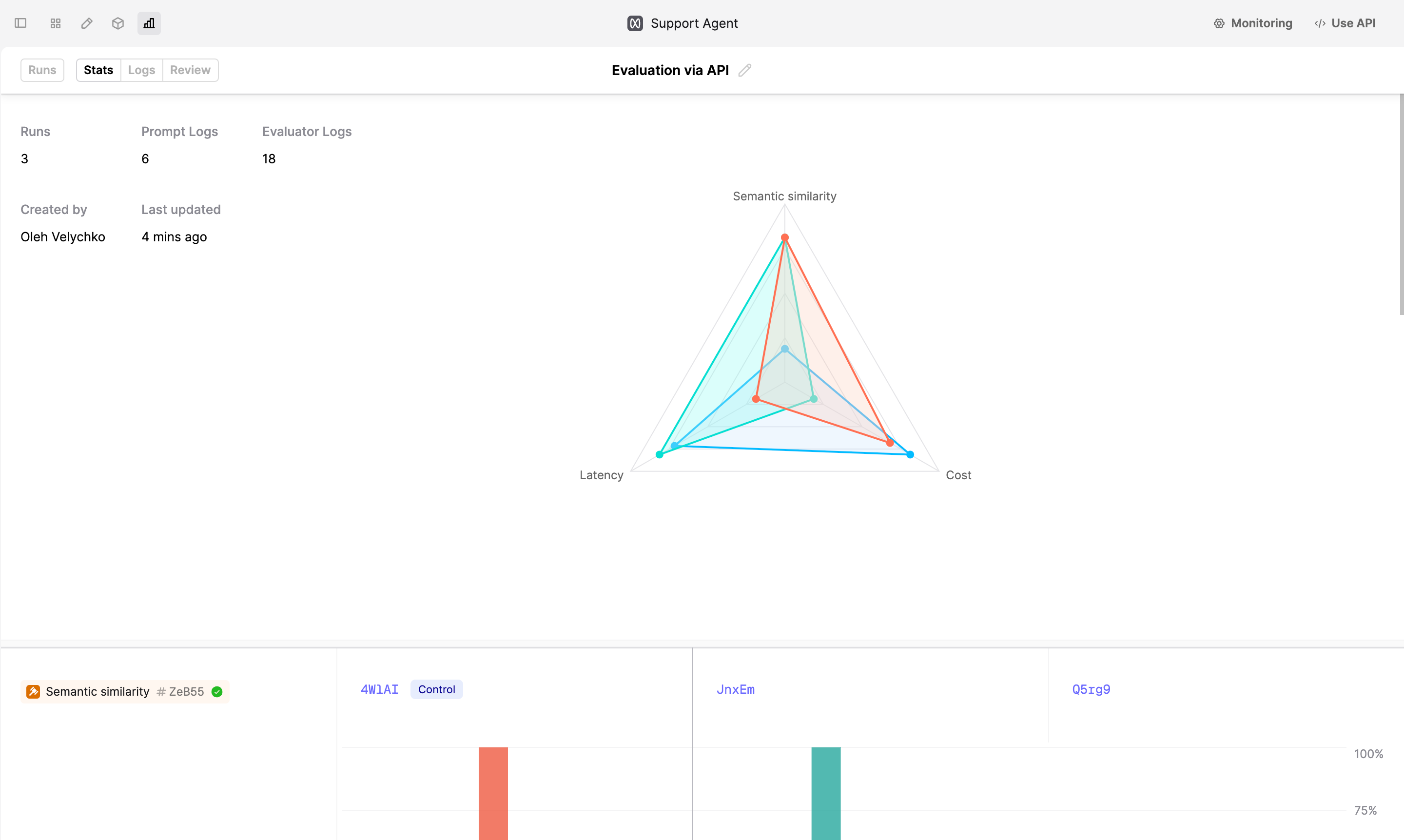
Alternatively you can see detailed stats in the Humanloop UI. Navigate to the Prompt, click on the Evaluations tab at the top of the page and select the Evaluation you just created. The stats are displayed in the Stats tab.
Run an Evaluation using your runtime
If you choose to execute Prompts using your own Runtime, you still can benefit from Humanloop Evaluations. In code snippet below, we run Evaluators hosted on Humanloop using logs produced by the OpenAI client.
Next steps
- Learn how to set up LLM as a Judge to evaluate your AI applications.