Foundation Models: Explained
What are Foundation Models and How Do They Work?
This article is an introduction to foundation models, explaining how they work, and the most popular applications for them.
What is a Foundation Model?
Foundation models are large neural networks, trained on large amounts of unlabelled data. Unlike more narrow traditional AI models, foundation models are general-purpose and can be easily adapted to many different tasks without new training data. Examples of Foundation Models include Large Language Models like GPT-4, Claude or Llama as well as large-scale image and audio models.
How Does a Foundation Model Work?
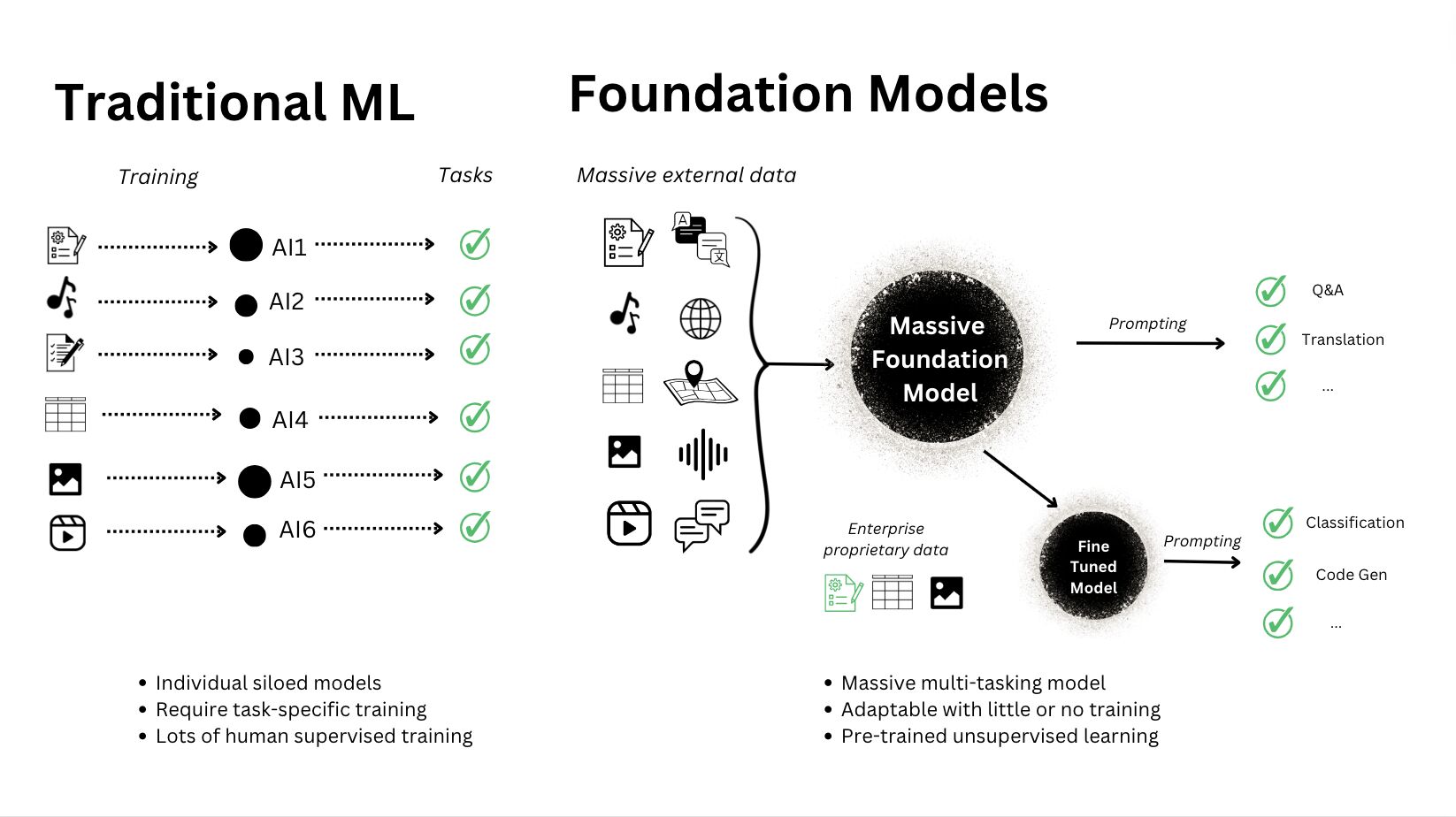
Traditionally, machine learning models have been designed to perform narrow, specific tasks. They are trained on highly curated datasets, limiting their capabilities to a specific context. Typically, a team of in-house data scientists or machine learning engineers are responsible for the development and training of these models. For each task, they need to design and train a new model, tailoring it to the unique requirements of that task.
Foundation models take a broader approach. They’re constructed upon a deep neural network architecture which is trained on a large, diverse and importantly unlabeled dataset. This process requires large amounts of data gathering/cleaning, computational resources and technical expertise. However, once the foundation model has completed training, it can be adapted to perform a wide range of tasks and made generally available. This means that any organization can leverage the existing knowledge of a pre-trained foundation model (like GPT-4) and prompt or tune it to perform a specific task rather than training their own model from scratch.
Much less machine learning knowledge is required to adapt a foundation model rather than training from scratch so modern generative AI teams are often made up of domain experts and product managers, not necessarily data scientists or machine learning specialists.
Examples of Foundation Models
Foundation models have opened a new frontier in artificial intelligence, particularly over the last half-decade as more computing resources have become available. Here are some notable foundation models that have changed the course of progress in artificial intelligence:
BERT (Bidirectional Encoder Representations for Transformers)
BERT was one of the breakthrough models in natural language processing (NLP) in 2018. Traditional language models at the time, such as Word2Vec and GloVe, relied on unidirectional context, which was inherently limited because it failed to capture the full contextual nuances of language. BERT aimed to overcome these limitations by introducing bi-directional training objectives and used two unsupervised learning objectives - masked language model (MLM) and next-sentence prediction (NSP) for this purpose. The pre-trained BERT model generates token-level embeddings, which facilitate contextual language comprehension across a range of natural language processing tasks, including sentiment analysis, text summarization, and semantic similarity.
CLIP (Contrastive Language-Image Pre-Training)
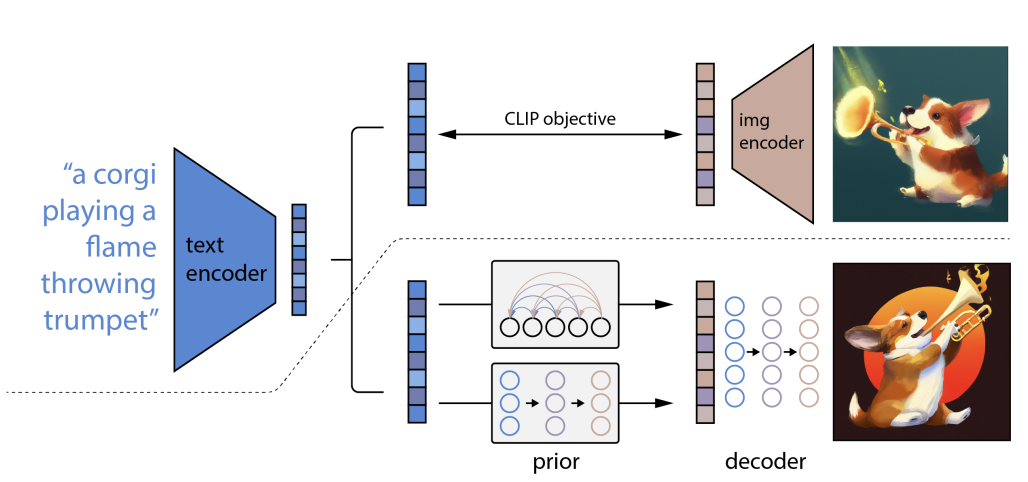
In 2021, a multi-modal vision and language modal, CLIP became popular for its ability to effectively perform tasks it had not been explicitly trained to handle. The model was trained on 400 million image-text pairs with the motive of learning how to connect language and images. It utilized an objective of contrastive learning to learn language-guided image representations and has now found many applications in image retrieval and image-text matching tasks.
GPT (Generative Pre-trained Transformers)
GPT was first introduced by OpenAI in the paper Improving Language Understanding by Generative Pre-training, which trained a generative language model with unsupervised learning objectives with unlabelled text corpus and then used supervised fine-tuning for specific tasks with labelled data. This semi-supervised learning approach used in the GPT architecture outperformed previously introduced language models in generative and language understanding tasks, leading to the release of its subsequent series, GPT-2 and GPT-3, in 2019 and 2020, respectively. Constructed with a decoder-only style from transformers, GPT was built on learning the next-word prediction objective, which has made it a significant foundation model for many text-generative tasks. Notably, this is the same architecture behind ChatGPT and GPT-4.
Capabilities of Foundation Models
Some of the most successful domain-specific applications of foundation models include:
Language Processing
Since foundation models don’t need labelled data and there’s an abundance of text on the internet, language-based foundation models were some of the earliest to be trained. Natural language preprocessing (NLP) has benefitted from the development of foundation models like GPT and BERT, which capture semantic relations in text. This has helped with tasks such as text generation, classification and summarization and has led to the advances in reasoning capabilities which we see in large language models today.
Visual Comprehension
These models have found a wide range of use cases in AI problems involving images and their association with other modalities like text. Computer vision foundation models have the capability to understand the content and style of given imagery, which helps them automate and improve tasks like object detection and image classification. Moreover, advanced models that are trained using multimodal data like CLIP and Kosmos-2 have bridged the gap between images and text by understanding their underlying visual-semantic correspondence.
Code Generation
One of the most common use cases for generative AI is assisting programmers in writing code samples by acquiring a syntactical and logical understanding of programming languages, for example, Python, Java, SQL, etc. Codey is an example of a coding assistant built on top of the foundation model called PaLM 2, released by Google to assist in coding functionality or GitHub Copilot, which is built using OpenAI’s GPT models. Such developments empowered by foundation models show promising growth for the software development sector by helping them with code generation, code debugging, and following structured programming practices.
Speech to Text
Targeting human speech from multiple languages such as English, French, and Chinese, foundation models have many applications in speech-to-text processes. These advancements are already in use by many companies, including Google, with their family of Universal Speech models. These foundation models exhibit the ability to understand audio prompts and provide textual responses.
Benefits of Foundation Models
Apart from the generalization capabilities of foundation models (discussed above), other benefits include:
Low cost to deploy
Once trained, there’s a variety of cost-effective methods available to reliably deploy a foundation model in an application, these include prompt engineering, fine-tuning and retrieval augmented generation. All techniques are significantly cheaper than training a large model from scratch and mixing them can help lead to cutting-edge AI performance. To learn more about this read our guide on optimizing the performance of LLMs.
Enhanced performance
Foundation models often achieve state-of-the-art performance on many tasks due to their ability to leverage vast amounts of training data and complex patterns. This often means they’re better placed than specialized models to perform specific tasks. For this reason, we see smaller foundation models being used in the data labelling, generation and cleaning phases for training larger models. A recent example being that Llama 2 was used to generate the training data for the text-quality classifiers powering Llama 3.
Continuous improvement
Foundation models are continuously improving, meaning that applications built on top of them can benefit from these improvements by switching to upgraded models. For organizations, this means that over time they can expect models to become more accurate, more efficient, and more robust. It’s important that the back-end of applications remain adaptable so that switching to more advanced models can be achieved without a performance disruption. Integration with Humanloop makes it easy to reliably update the model behind an application without changing any code while comparing the performance before and after.
Challenges of Foundation Models
While building a base for different tasks, foundation models face multiple challenges, namely:
Data and computation scarcity
The recent advancements in foundation models have created a surge in demand for computing power, making it more expensive to train models from scratch. Furthermore, data is becoming an increasingly scarce resource, with companies like Google paying Reddit $60M per year for access to real-time content to train their models.
Bias
To avoid producing biased results, foundation models must be trained on a well-balanced dataset. This presents a challenge given the vast amount of data on which models like GPT-4 are trained. Following the initial training phase, the model undergoes a Reinforcement Learning from Human Feedback (RLHF) stage, where its responses are refined based on human evaluations to enhance accuracy and performance. This process must be run neutrally to avoid a foundation model being influenced in a single direction, as it will become apparent in downstream tasks that the model is unreliable.
Lack of standardization
Currently there is a lack of standardized methods for interpreting the outputs of foundation models. Although LLM benchmarks are used to compare LLMs in terms of their general capabilities, understanding how a model will perform within the context of a given application remains a challenge.
Evaluations on Humanloop help to solve this by enabling teams to develop datasets and evalautors customized for their applications, which can be used to rigorously measure and track the performance of LLMs so they can reliably be put into production. Learn more about our approach in our guide to evaluating LLMs applications.
Why Are Foundation Models Important?
Recent advancements in the performance of foundation models represent the beginning of one of the biggest technological shifts in history. Foundation models offer a scalable, adaptable framework that revolutionizes how information can be processed, facilitating the creation of globally accessible intelligent systems. Consequently, they have created a new computing paradigm which is reshaping industries and expanding the boundaries of what humans and machines can achieve.
Foundation Models on Humanloop
Humanloop makes it easy for enterprises to test, evaluate, and deploy large language model (LLM) based applications built on foundation models such as GPT-4 and Claude 3.
Our platform for developing and evaluating LLM applications solves the most critical workflows around prompt engineering and model evaluation with an interactive environment where product managers and engineers can work together to find, manage and measure prompts for LLMs. Coupled with this are tools for rigorously monitoring and evaluating performance, both from user feedback and automated evaluations.
To learn more about how we can help you build reliable applications with foundation models, book a demo with our team.
About the author

- 𝕏@conorkellyai










