Overview
A Log is created every time a Prompt is called. The Log contain contains the inputs and the output (the generation) as well as metadata such as which version of the Prompt was used and any associated feedback.
There are two ways to get your Logs into Humanloop, referred to as ‘proxy’ and ‘async’.
Proxied
In one call you can fetch the latest version of a Prompt, generate from the provider, stream the result back and log the result. Using Humanloop as a proxy is by far the most convenient and way of calling your LLM-based applications.
Async
With the async method, you can fetch the latest version of a Prompt, generate from the provider, and log the result in separate calls. This is useful if you want to decouple the generation and logging steps, or if you want to log results from your own infrastructure. It also allows you to have no additional latency or servers on the critical path to your AI features.
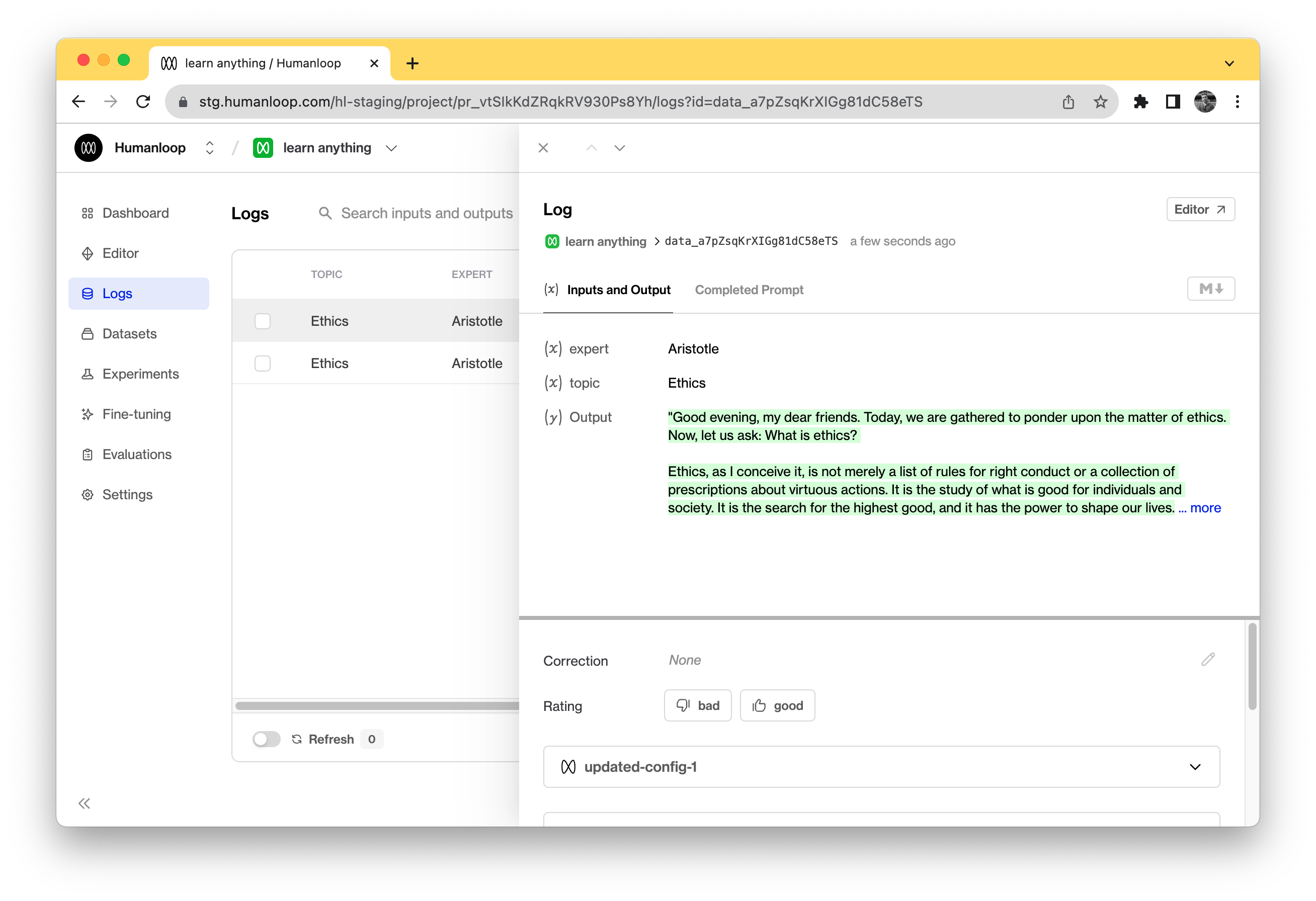
The guides in this section instruct you on how to create Logs on Humanloop. Once this is setup, you can begin to use Humanloop to evaluate and improve your LLM apps.