Use external Evaluators
LLM and code Evaluators generally live on the Humanloop runtime environment. The advantage of this is that these Evaluators can be used as monitoring Evaluators and to allow triggering evaluations directly from the Humanloop UI.
Your setup however can be more complex: your Evaluator has library dependencies that are not present in the runtime environment, your LLM evaluator has multiple reasoning steps, or you prefer managing the logic yourself.
External Evaluators address this: they are registered with Humanloop but their code definition remains in your environment. In order to evaluate a Log, you call the logic yourself and send the judgment to Humanloop.
In this tutorial, we will build a chat agent that answers questions asked by children, and evaluate its performance using an external Evaluator.
Create the agent
We reuse the chat agent from our evaluating an agent tutorial.
Run the agent and check that it works as expected:
Python
TypeScript
Evaluate the agent
How Evaluators work
Evaluators are callables that take the Log’s dictionary representation as input and return a judgment. The Evaluator’s judgment should respect the return_type present in the Evaluator’s specification.
The Evaluator can take an additional target argument to compare the Log against. The target is provided in an Evaluation context by the validation Dataset.
For more details, check out our Evaluator explanation.
Define external Evaluator
The Evaluator takes a log argument, which represents the Log created by calling call_agent.
Let’s add a simple Evaluator that checks if the agent’s answers are too long. Add this in the agent.py file:
Add Evaluation
Instantiate an Evaluation using the client’s []evaluations.run](/docs/v5/sdk/run-evaluation) utility. easy_to_understand is an external Evaluator, so we provide its definition via the callable argument. At runtime, evaluations.run will call the function and submit the judgment to Humanloop.
Add detailed logging
Up to this point, we have treated the agent as a black box, reasoning about its behavior by looking at the inputs and outputs.
Let’s use Humanloop logging to observe the step-by-step actions taken by the agent.
Python
TypeScript
Modify main.py:
Evaluate the agent again. When it’s done, head to your workspace and click the Agent Flow on the left. Select the Logs tab from the top of the page.
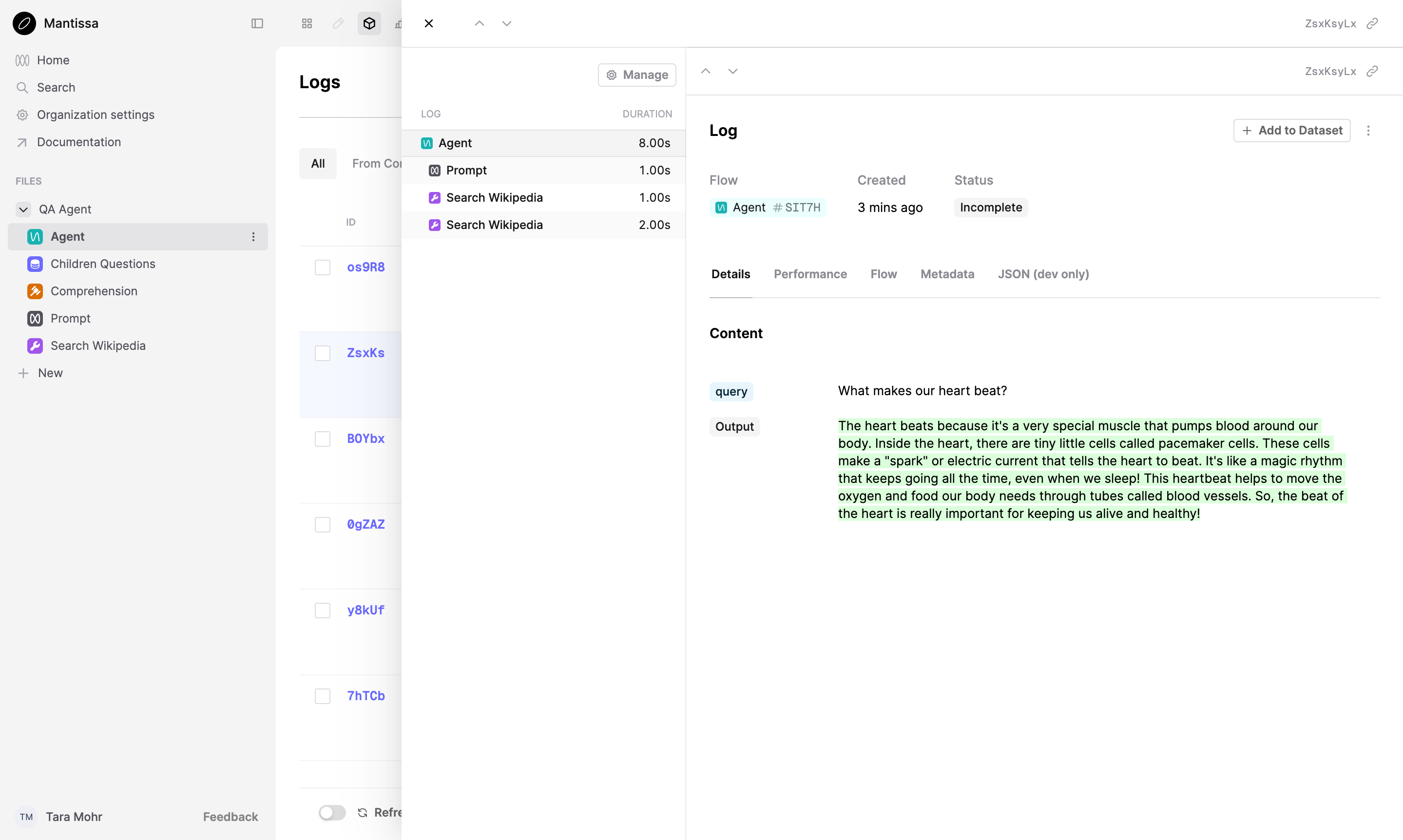
The decorators divide the code in logical components, allowing you to observe the steps taken to answer a question. Every step taken by the agent creates a Log.
Next steps
You’ve learned how to integrate your existing evaluation process with Humanloop.
Learn more about Humanloop’s features in these guides:
-
Learn how to use Evaluations to improve on your feature’s performance in our tutorial on evaluating a chat agent.
-
Evals work hand in hand with logging. Learn how to log detailed information about your AI project in logging setup guide.