Self-hosted evaluations
Self-hosted evaluations
For some use cases, you may wish to run your evaluation process outside of Humanloop, as opposed to running the evaluators we offer in our Humanloop runtime.
For example, you may have implemented an evaluator that uses your own custom model or which has to interact with multiple systems. In these cases, you can continue to leverage the datasets you have curated on Humanloop, as well as consolidate all of the results alongside the prompts you maintain in Humanloop.
In this guide, we’ll show an example of setting up a simple script to run such a self-hosted evaluation using our Python SDK.
Prerequisites
- You need to have access to evaluations
- You also need to have a Prompt – if not, please follow our Prompt creation guide.
- You need to have a dataset in your project. See our dataset creation guide if you don’t yet have one.
- You need to have a model config that you’re trying to evaluate - create one in the Editor.
Setting up the script
Retrieve the ID of the Humanloop project you are working in - you can find this in the Humanloop app
Initiate an evaluation run in Humanloop
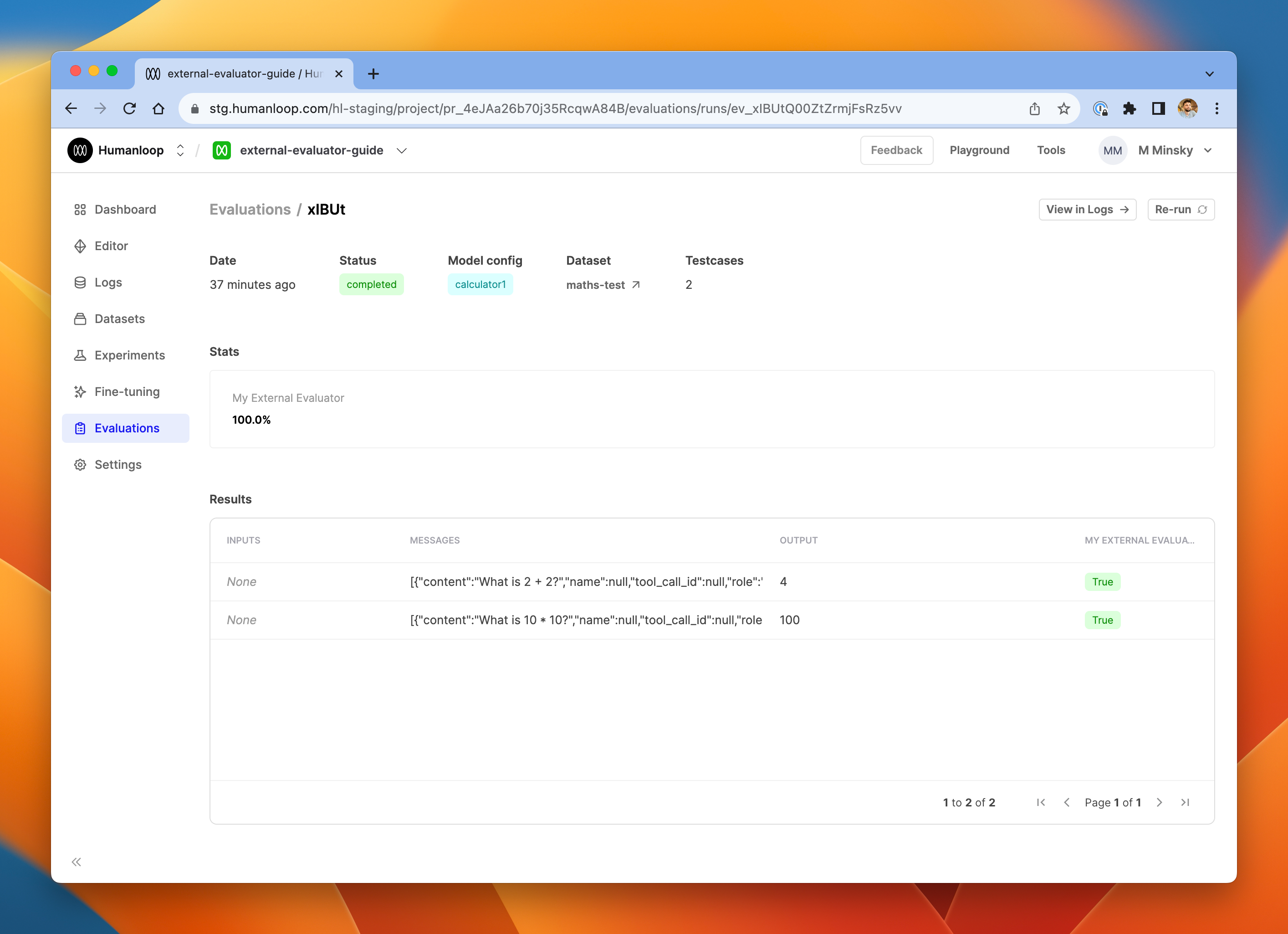
After this step, you’ll see a new run in the Humanloop app, under the Evaluations tab of your project. It should have status running.
Review the results
After running this script with the appropriate resource IDs (project, dataset, model config), you should see the results in the Humanloop app, right alongside any other evaluations you have performed using the Humanloop runtime.