Set up evaluations using API
Paid Feature
This feature is not available for the Free tier. Please contact us if you wish to learn more about our Enterprise plan
API Options
This guide uses our Python SDK. All of the endpoints used are available in our TypeScript SDK and directly via the API.
Prerequisites
Install and initialize the SDK
First you need to install and initialize the SDK. If you have already done this, skip to the next section.
Open up your terminal and follow these steps:
- Install the Humanloop SDK:
- Initialize the SDK with your Humanloop API key (you can get it from the Organization Settings page).
Create evaluation
We’ll go through how to use the SDK in a Python script to set up a project, create a dataset and then finally trigger an evaluation.
Set up a project
Create a project and register your first model config
We’ll use OpenAI’s GPT-4 for extracting product feature names from customer queries in this example. The first model config created against the project is automatically deployed:
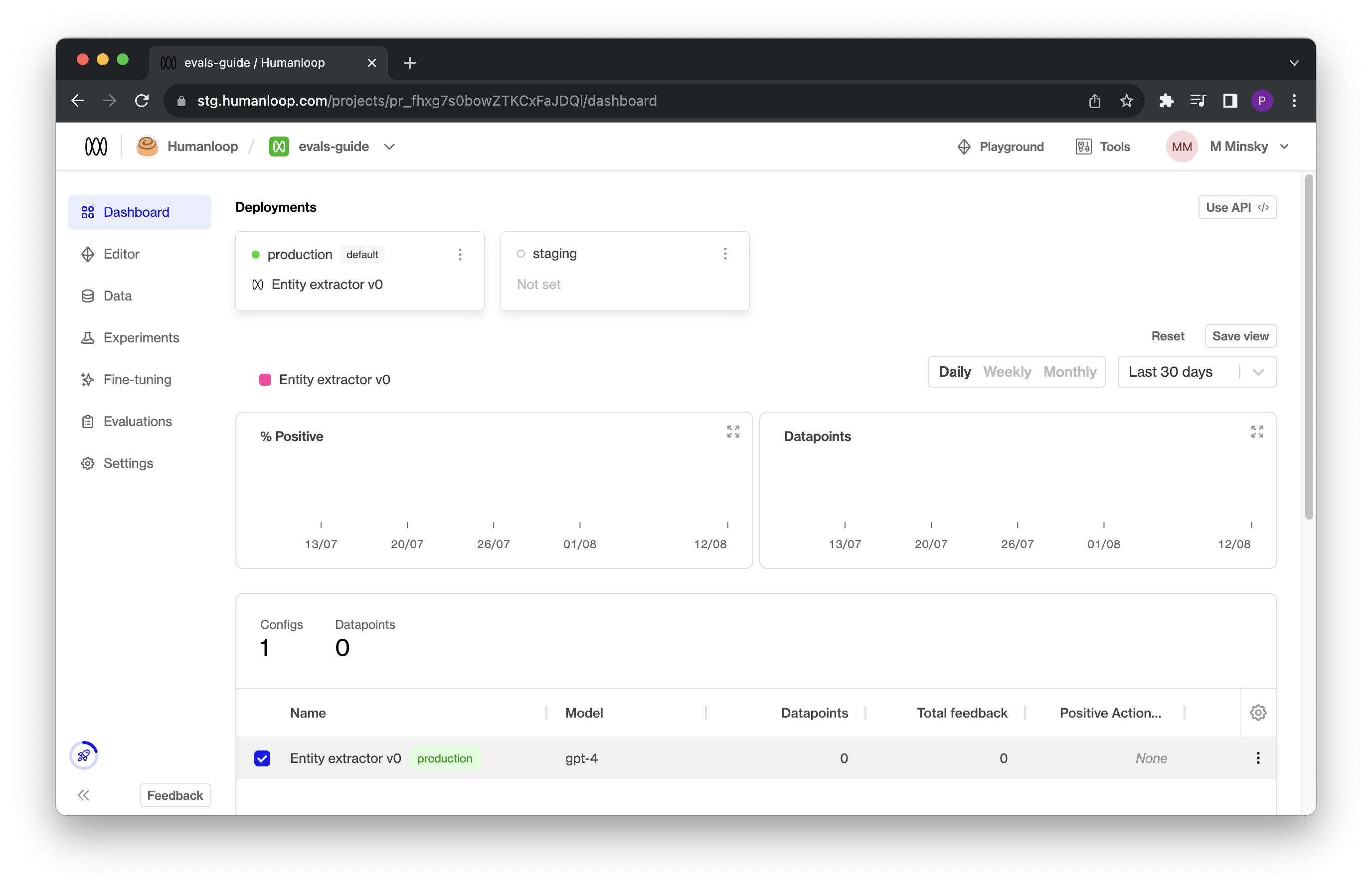
If you log onto your Humanloop account you will now see your project with a single model config defined:
Create a dataset
Follow the steps in our guide to Upload a Dataset via API.
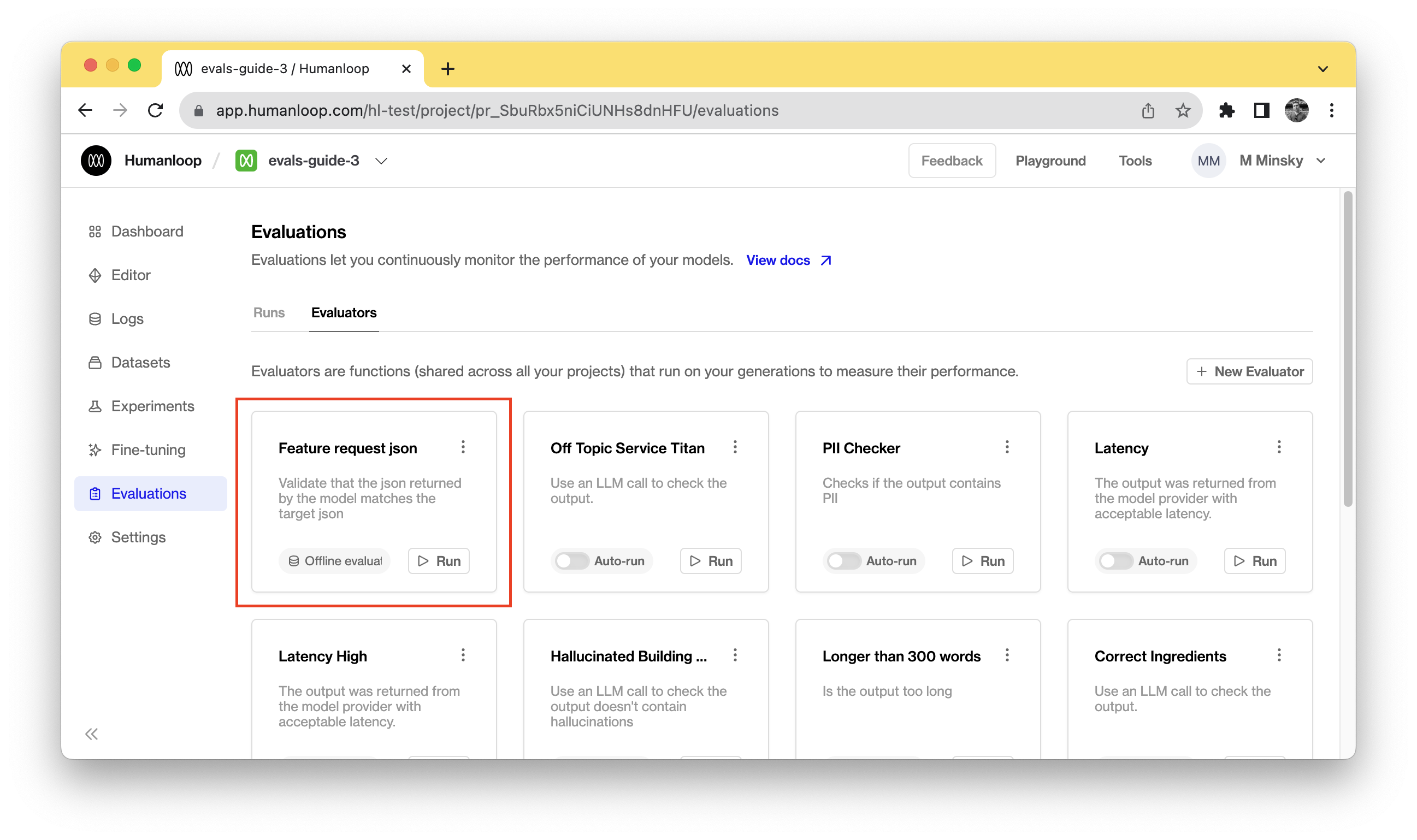
Create an evaluator
Now that you have a project with a model config and a dataset defined, you can create an evaluator that will determine the success criteria for a log generated from the model using the target defined in the test datapoint.
Launch an evaluation
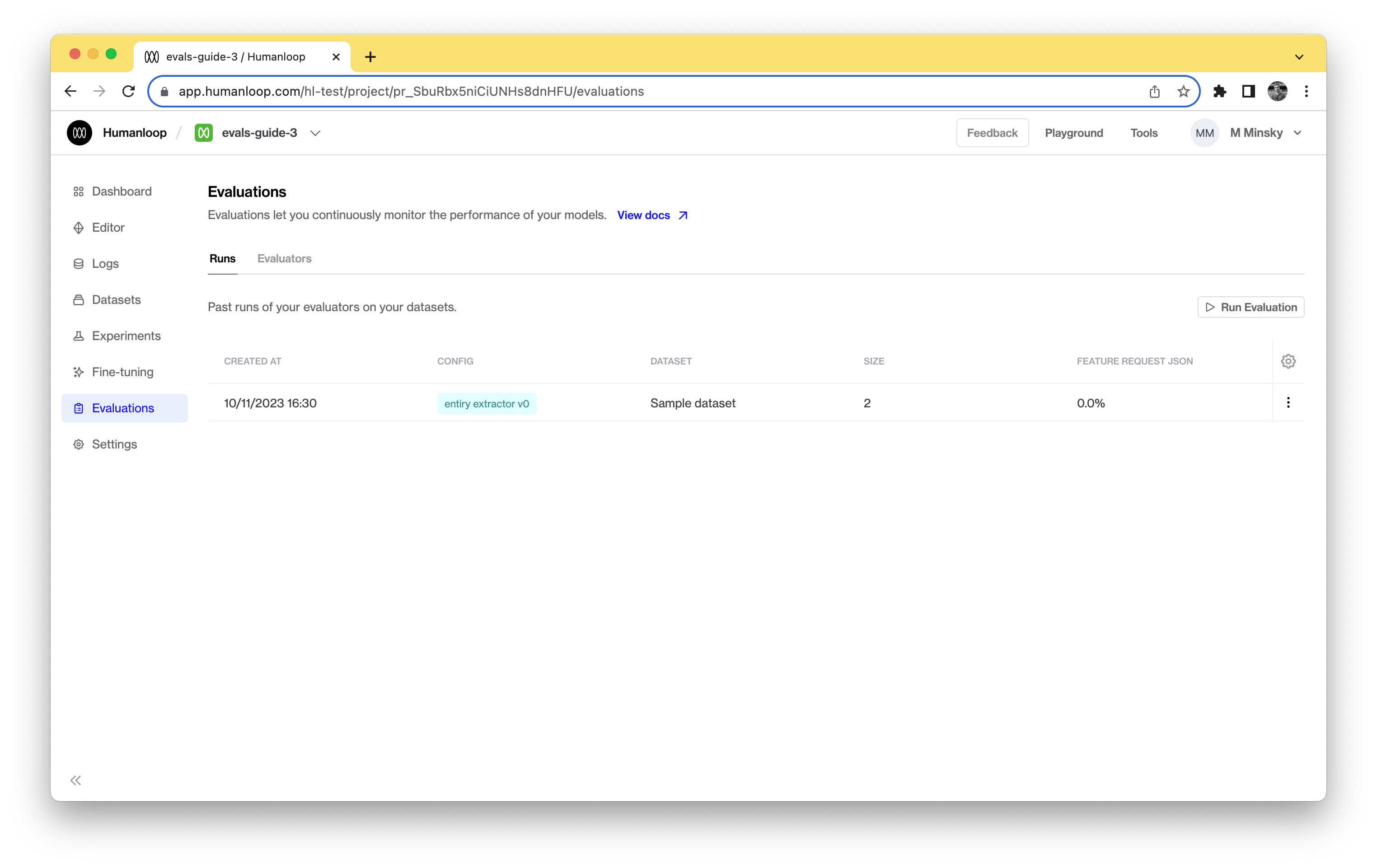
Launch an evaluation
You can now low against the model config using the dataset and evaluator. In practice you can include more than one evaluator:
Navigate to your Humanloop account to see the evaluation results. Initially it will be in a pending state, but will quickly move to completed given the small number of test cases. The datapoints generated by your model as part of the evaluation will also be recorded in your project’s logs table.
Create evaluation - full script
Here is the full script you can copy and paste and run in your Python environment: