Run experiments managing your own model
Experiments can be used to compare different prompt templates, different parameter combinations (such as temperature and presence penalties) and even different base models.
This guide focuses on the case where you wish to manage your own model provider calls.
Prerequisites
- You already have a Prompt — if not, please follow our Prompt creation guide first.
- You have integrated
humanloop.complete_deployed()or thehumanloop.chat_deployed()endpoints, along with thehumanloop.feedback()with the API or Python SDK.
This guide assumes you’re are using an OpenAI model. If you want to use other providers or your own model please also look at the guide for running an experiment with your own model provider.
Support for other model providers on Humanloop is coming soon.
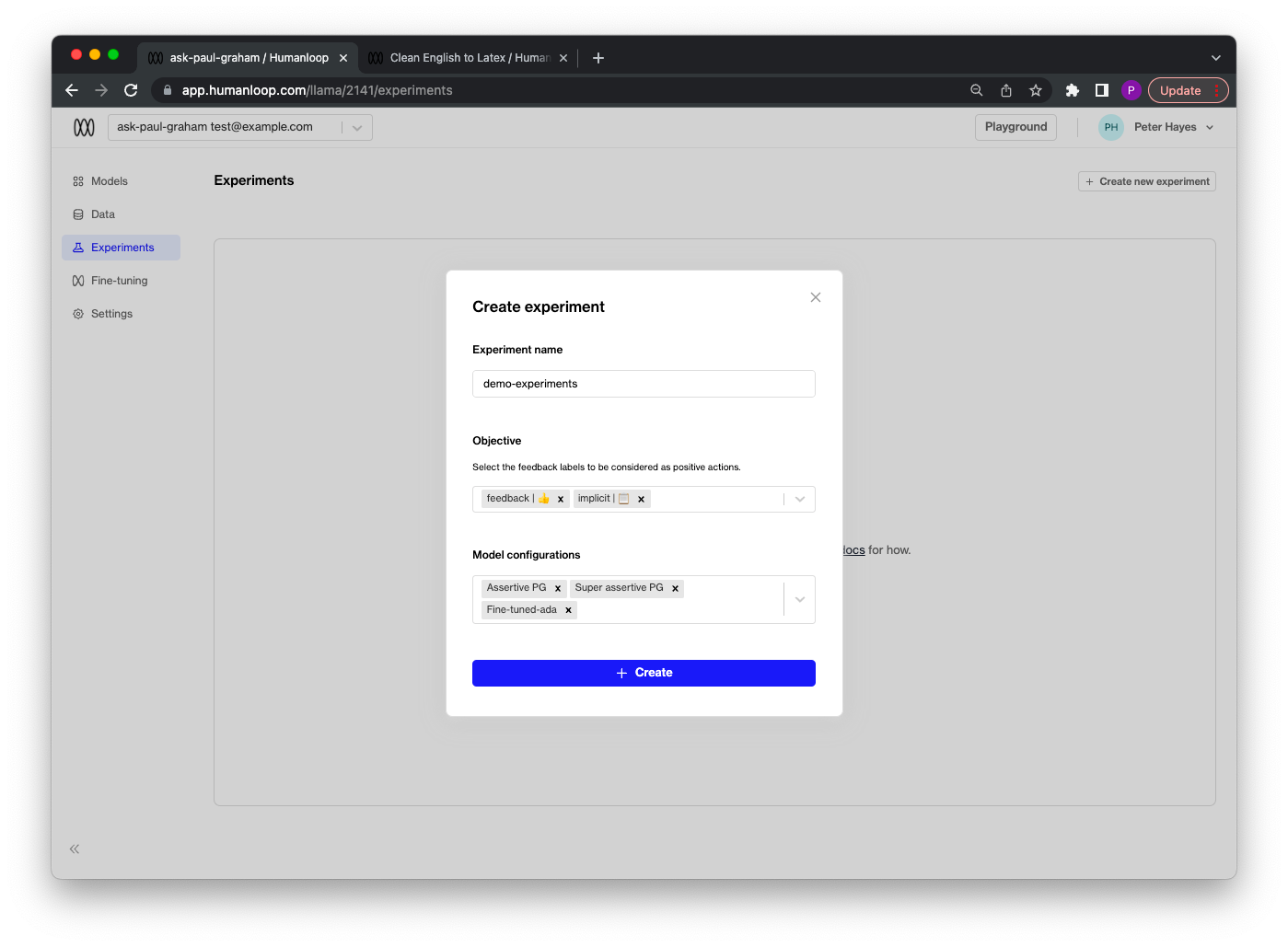
Create an experiment
Navigate to the Experiments tab of your project. ### Click the
Create new experiment button: 1. Give your experiment a descriptive name. 2. Select a list of feedback labels to be considered as positive actions - this will be used to calculate the performance of each of your model configs during the experiment. 3. Select which of your project’s model configs you wish to compare. Then click the Create button.
Log to your experiment
In order to log data for your experiment without using humanloop.complete_deployed() or humanloop.chat_deployed(), you must first determine which model config to use for your LLM provider calls. This is where the humanloop.experiments.get_model_config() function comes in.
Set the experiment as the active deployment.
To do so, find the default environment in the Deployments bar. Click the dropdown menu from the default environment and from those options select Change deployment. In the dialog that opens select the experiment you created.
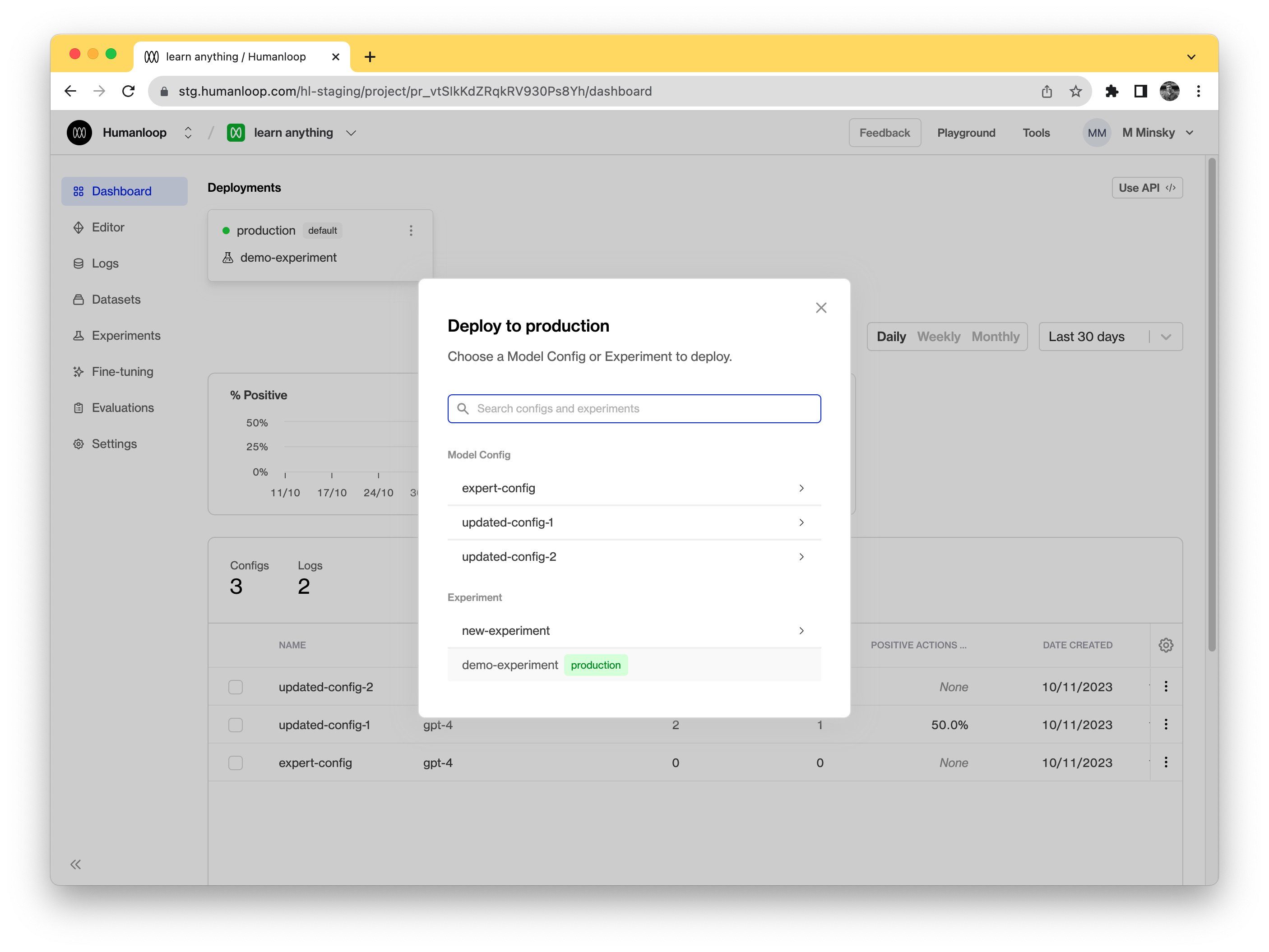
You can also run multiple experiments within a single project. In this case, first navigate to the Experiments tab of your project and select your Experiment card. Then, retrieve your experiment_id from the experiment summary:

Then, retrieve your model config from your experiment by calling humanloop.experiments.sample(experiment_id=experiment_id).